




How to organize your code locations for clarity, maintainability, and reuse.
Code locations are one of the most unique and powerful features in Dagster. They allow you to maintain separate, isolated environments, each with its own Python libraries and dependencies. This makes it easy to ensure that work is executed in the right context. Even better, Dagster supports multiple code locations within a single deployment, while still providing a unified asset graph and end-to-end lineage.
This level of flexibility is incredibly useful but it can also lead to a common question: “How should I structure my code locations?” The honest answer is: “It depends.” There’s no one-size-fits-all approach. The ideal setup varies based on your team structure, workflows, and how your organization manages code.
That said, there are several common patterns we’ve seen in practice, both within our team and across the Dagster community. You may find that one (or a combination) of these patterns aligns with how you want to organize your Dagster project at your organization.
Single Code Location
There’s nothing wrong with using a single code location. In fact, your first Dagster deployment will likely start this way. Single code locations offer several benefits: there's only one environment to manage, all assets live together, and it’s easier to track changes across the project. Testing pipelines end-to-end can also be simpler when everything is co-located in the same context.
Single code locations tend to work best for early-stage projects or smaller teams that are less specialized. For example, your team might include analysts and data engineers, but the roles are flexible. Analysts may tweak ETL jobs, and engineers may build dashboards. In these cases, having everything in one place supports collaboration and minimizes overhead.
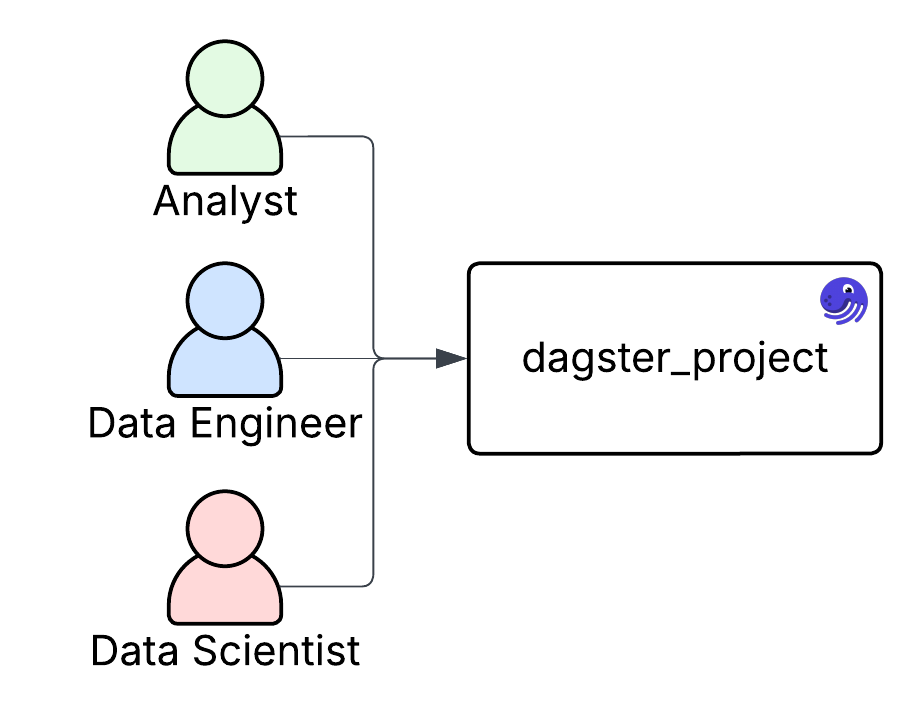
Team Based Locations
As your Dagster project grows, or more people begin contributing, it may be time to consider breaking up your code into multiple code locations. One of the most common ways to do this is by team.
A key reason to split by team is the difference in development cadence. For instance, analysts may update modeling logic frequently, while data engineers make less frequent changes to core ETL pipelines. While it's possible to manage this within a single repository and code location, creating separate code locations allows you to better align each environment with its users' needs and workflows.
Team-based code locations are also a great way to introduce new groups to Dagster. For example, if a new AI or ML team wants to start experimenting with Dagster, you can give them their own isolated code location. This lets them build, test, and even fail independently, without impacting the rest of the project.
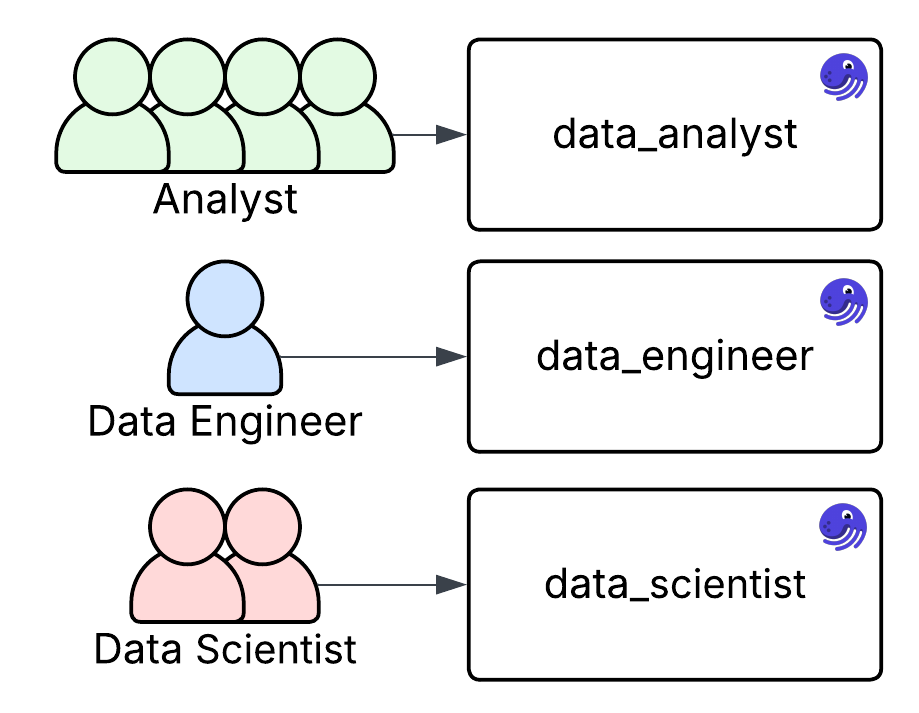
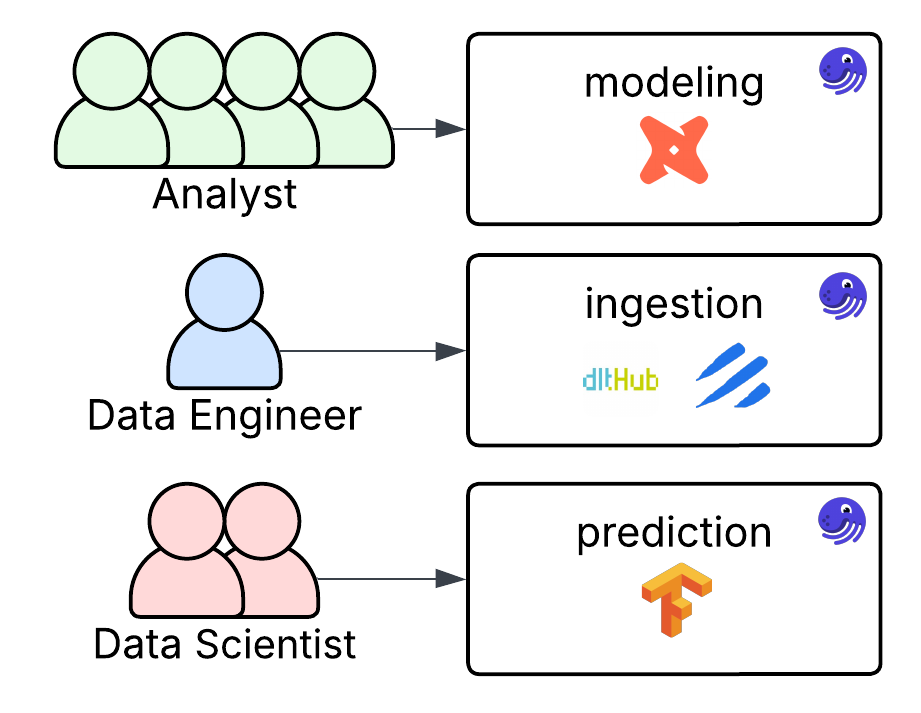
Tool-Based Locations
Another approach is to structure your project using tool-based code locations. In practice, this can look similar to a team-based organization. But instead of grouping code by who uses it, you group it by function and underlying dependencies.
For example, rather than creating a "data_analyst" code location, you might create a dedicated code location for dbt. This makes it clear that the code location is responsible for your modeling layer, and it helps isolate that functionality from other parts of your pipeline. It also simplifies environment management by keeping dependencies lean, avoiding unnecessary packages.
Tool-based locations are especially useful when different tools or frameworks require distinct configurations or runtimes. This architecture promotes clarity and helps enforce clean boundaries between concerns like ingestion, transformation, and reporting.
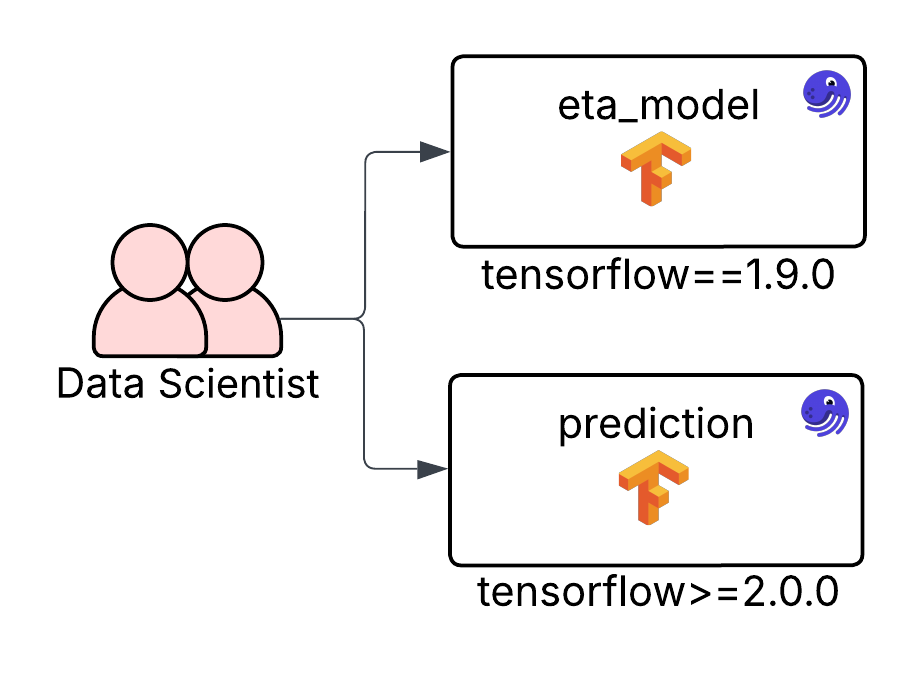
Dedicated Code Locations
A slightly less common but valid approach is creating separate code locations for specific pipelines. This is especially useful when certain processes are more mission-critical than others. If you need to fine-tune, isolate, or tightly control a particular set of assets, placing them in their own code location gives you that flexibility.
Imagine your data science team manages several models, but the Estimated Time of Arrival (ETA) model directly powers the majority of your website’s traffic. Rather than grouping all models into a single code location with shared dependencies, you can extract the ETA model into its own code location. This allows you to pin dependencies, apply stricter testing or deployment standards, and manage it independently from the rest of your modeling code.This approach allows you to update or iterate on most of your pipelines while keeping your most critical workflows stable and isolated from unrelated changes.
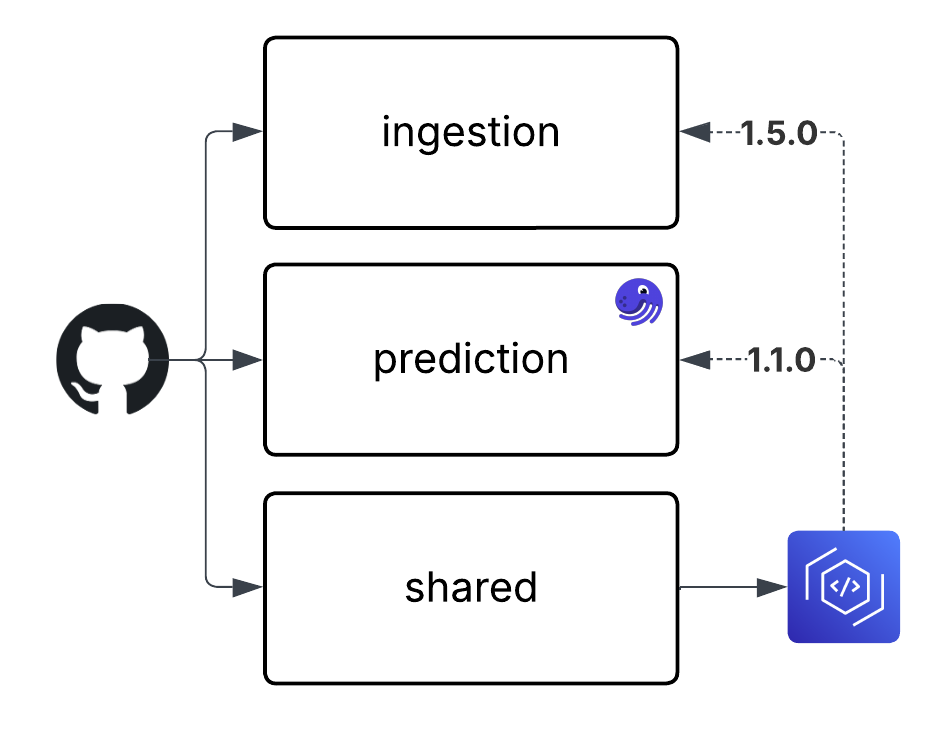
Decoupling Shared Code
If you find that there's a lot of shared Dagster code between your assets, don’t feel pressured to keep everything in the same code location. In many cases, it’s better to decouple general-purpose logic, like custom Dagster resources, utilities, or helpers, from specific asset definitions.
For example, imagine you want to split your Dagster project across multiple code locations, but they all rely on the same custom Dagster resource used to interact with your company’s internal API. Instead of keeping everything in a single monolithic code location, or having to separately maintain that resource in each code location, a cleaner solution is to extract the shared resource into its own Python module. You can then release and version it separately, and treat it as a dependency across your Dagster code locations that require it.
A common way to manage this is by uploading the shared library to a private package repository such as AWS CodeArtifact. This keeps the library internal while still allowing easy installation via `pip` across environments.
Now, each code location can build its Docker image or virtual environment via CI/CD, authenticate with CodeArtifact, and install the shared library like any other dependency. Another major benefit of this approach is versioning. By releasing the shared library with specific versions, each code location can pin its specific usage, making it easier to coordinate upgrades and reduce the risk of breaking changes across teams. Decoupling code in this way can also make it easier to enforce consistent standards across multiple teams developing on Dagster.
What’s best for you?
These are just a few of the patterns you can consider when designing your code locations. The good news is that there are no hard rules. Because Dagster’s architecture makes code locations effectively lightweight and isolated, you can have as many as you need and in whatever combination works best for your organization.
You might find that certain teams prefer the autonomy of their own code locations, or that some Python libraries have version conflicts that are easier to manage when isolated.
So don't be afraid to experiment with different layouts and see what fits your workflows. The goal is to create a structure that scales with your team and makes it easier to manage your data platform.





.jpg)
.png)



.png)

