




Every great model starts with great data. This first part walks through how to structure ingestion with Dagster, prepare your text corpus, and build a tokenizer that shapes how your model understands the world.
AI progress moves so quickly that it often feels impossible to keep up. Models balloon in size, training systems grow more tangled, and the number of people who truly understand every layer of a modern LLM stack seems to shrink each year.
That is why Andrej Karpathy’s work continues to resonate. His projects remind us that understanding is still within reach. nanochat is the latest example: a tiny educational LLM that fits into a single repository and can be trained cheaply. It is not meant to compete with state-of-the-art models. Instead, it provides a clear window into how these systems are built.
When I started digging into the nanochat repo, the strengths were immediately obvious. The model architecture is clean. The training loop is approachable. The tokenizer and preprocessing pipelines are written to be understood rather than optimized into obscurity.
Even so, a simple LLM still has many moving parts: data ingestion, tokenization, training, evaluation, checkpointing, and the logic that ties everything together. nanochat does more than show how a model works. It highlights how many steps must align in the right order for training to succeed.
This shifted my focus. Instead of looking only at the model, I began thinking about the workflow. How do we make the entire process visible and reproducible? How can someone run the whole pipeline or a single step with confidence? How can we bring the same clarity to orchestration that nanochat brings to the code itself?
That is the purpose of this series. The goal is not to replace nanochat, but to wrap it in Dagster so the training process becomes modular, observable, and easier to operate. The full example lives here.
Getting the FineWeb Data
nanochat starts with a curated subset of the FineWeb dataset: 1,823 Parquet shards that total roughly 178 GB of raw text. Managing this data is a perfect example of a task that sounds simple but becomes tedious quickly. Downloading hundreds of files reliably, tracking metadata, and recovering from failures all require attention, and every detail matters.
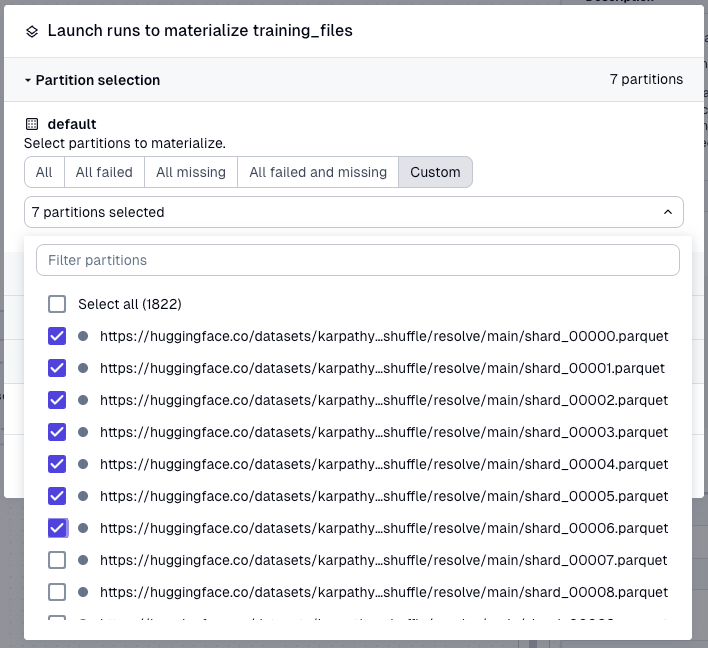
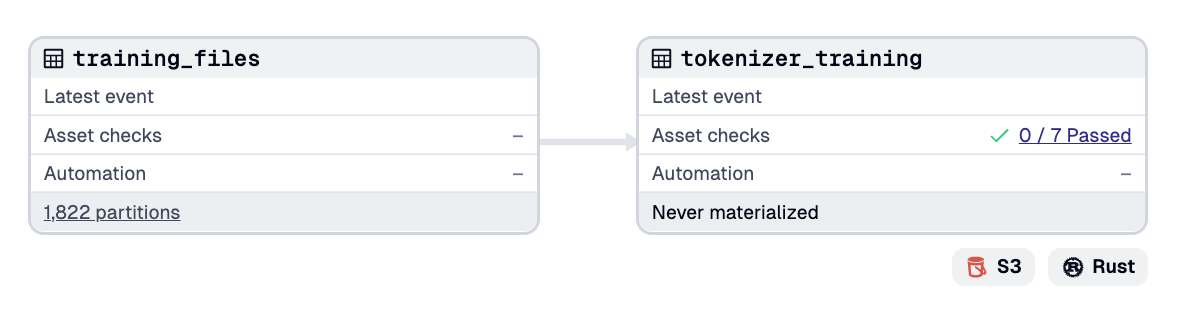
Dagster gives us a clean way to handle this. Each shard becomes a partition of a single asset, the training_files asset. Dagster manages parallel downloads, retries, metadata for each file, and the ability to resume from where you left off.
BASE_URL = "https://huggingface.co/datasets/karpathy/fineweb-edu-100b-shuffle"
SHARDS = [f"{BASE_URL}/resolve/main/shard_{i:05d}.parquet" for i in range(1823)]
TRAINING_SET = SHARDS[:-1]
@dg.asset(
deps=[raw_data],
partitions_def=dg.StaticPartitionsDefinition(TRAINING_SET),
group_name="ingestion",
)
def training_files(context: dg.AssetExecutionContext) -> dg.MaterializeResult:
file_path = os.path.abspath(os.path.join(FILE_DIRECTORY, filename))
download_file(url_path, file_path)
return dg.MaterializeResult(
metadata={
"file_path": dg.MetadataValue.text(str(file_path)),
"url": dg.MetadataValue.url(url_path),
}
)This simple asset becomes the backbone of the project. Once the shards exist, everything downstream becomes deterministic.
Structuring the model this way also makes it easier to experiment with different amounts of data. This is especially helpful early in pipeline development when you want to validate end-to-end functionality without training on the full dataset. The approach provides flexibility for rapid iteration while keeping the core logic unchanged.
Training a High-Speed Tokenizer With Rust
Once we have downloaded the set of partitions we want to experiment with, the next step is tokenization. This is where we turn the raw text from the previous section into numerical tokens that a neural network can process. We need to ensure that all downstream steps use the same vocabulary, which means creating a single shared mapping regardless of how many shards we include.
Tokenizing hundreds of gigabytes with a pure Python implementation would be painfully slow, and this is an area where performance truly matters. nanochat avoids this problem by including a lightweight Rust tokenizer called rustbpe. Rust provides speed without sacrificing clarity. In practice, it is often 10 to 100 times faster than a Python equivalent and can turn a process that might take hours into one that completes in minutes.
We reuse the same library from nanochat, but with a small extension. Instead of loading raw text files, we let the tokenizer operate directly on Parquet shards using Apache Arrow. This enables efficient zero-copy reads, which is important at this scale.
To connect the Rust and Python components, we rely on PyO3 bindings. This allows us to interact with the Rust tokenizer as if it were any other Python library.
import rustbpe
...
tokenizer = rustbpe.Tokenizer()
tokenizer.train_from_parquet_file(
parquet_path=parquet_path,
vocab_size=10000,
pattern=None, # Use default GPT-4 pattern
text_column="text",
doc_cap=0, # No document cap
max_chars=10_000_000,
)The result is a 10,000-token vocabulary and a set of merge rules that match the format used by tiktoken. In other words, we produce the same tokenizer artifacts as nanochat, but now they are integrated into a larger pipeline.
Because the project depends on a local Rust extension, we also configure uv to rebuild that extension whenever any Rust source file changes. This keeps the environment consistent without manual effort.
dependencies = [
...
"rustbpe",
]
[tool.uv.sources]
rustbpe = { path = "rustbpe", editable = true }
[tool.uv]
cache-keys = [{file = "pyproject.toml"}, {file = "rustbpe/Cargo.toml"}, {file = "rustbpe/**/*.rs"}]After the tokenizer vocabulary is created, the asset uploads it to S3 so that all training assets can access it easily.

Making Validation a First-Class Citizen
One detail that is easy to overlook in nanochat is the validation that happens throughout. After training the tokenizer, nanochat runs several checks. It verifies reversibility and measures compression efficiency, and it compares these results against the GPT-2 tokenizer. These steps are subtle but essential because they confirm that the training data is actually usable before we move on to the far more expensive modeling stages.
Dagster gives these checks a more visible home. Instead of leaving them inside scripts, we promote them to asset checks and associate them directly with the assets they validate. This makes the verification process explicit in the pipeline. You can see what passed, what failed, and whether a failure should block downstream work.
We reuse the same evaluation texts that nanochat uses: an English news snippet, Korean text, Python code, and scientific writing. Each one highlights a different aspect of tokenizer behavior.
EVAL_TEXTS = {
"news": """(Washington, D.C., July 9, 2025)- Yesterday, Mexico's National Service of Agro-Alimentary Health, Safety, and Quality (SENASICA) reported a new case of New World Screwworm (NWS) in Ixhuatlan de Madero, Veracruz in Mexico, which is approximately 160 miles northward of the current sterile fly dispersal grid.""",
"korean": """정직한 사실 위에, 공정한 시선을 더하다
Herald Korea Times
헤럴드코리아타임즈는 정치, 경제, 사회, 문화 등 한국 사회 전반의 주요 이슈를 심도 있게 다루는 종합 온라인 신문사입니다.""",
"code": """class BasicTokenizer(Tokenizer):
def __init__(self):
super().__init__()
def train(self, text, vocab_size, verbose=False):
assert vocab_size >= 256
num_merges = vocab_size - 256""",
"science": """Photosynthesis is a photochemical energy transduction process in which light-harvesting pigment–protein complexes within the thylakoid membranes of oxygenic phototrophs absorb photons and initiate charge separation at the reaction center.""",
}
@dg.asset_check(asset=combined_tokenizer, blocking=False)
def tokenizer_vs_gpt2_news(
context: dg.AssetCheckExecutionContext,
) -> dg.AssetCheckResult:
"""Compare tokenizer compression vs GPT-2 on news text (formal English)."""
return _compare_tokenizer_vs_gpt2_single_text("news", EVAL_TEXTS["news"])
...By placing validation front and center, the workflow becomes easier to reason about. The checks are no longer hidden. They become part of the pipeline’s story.
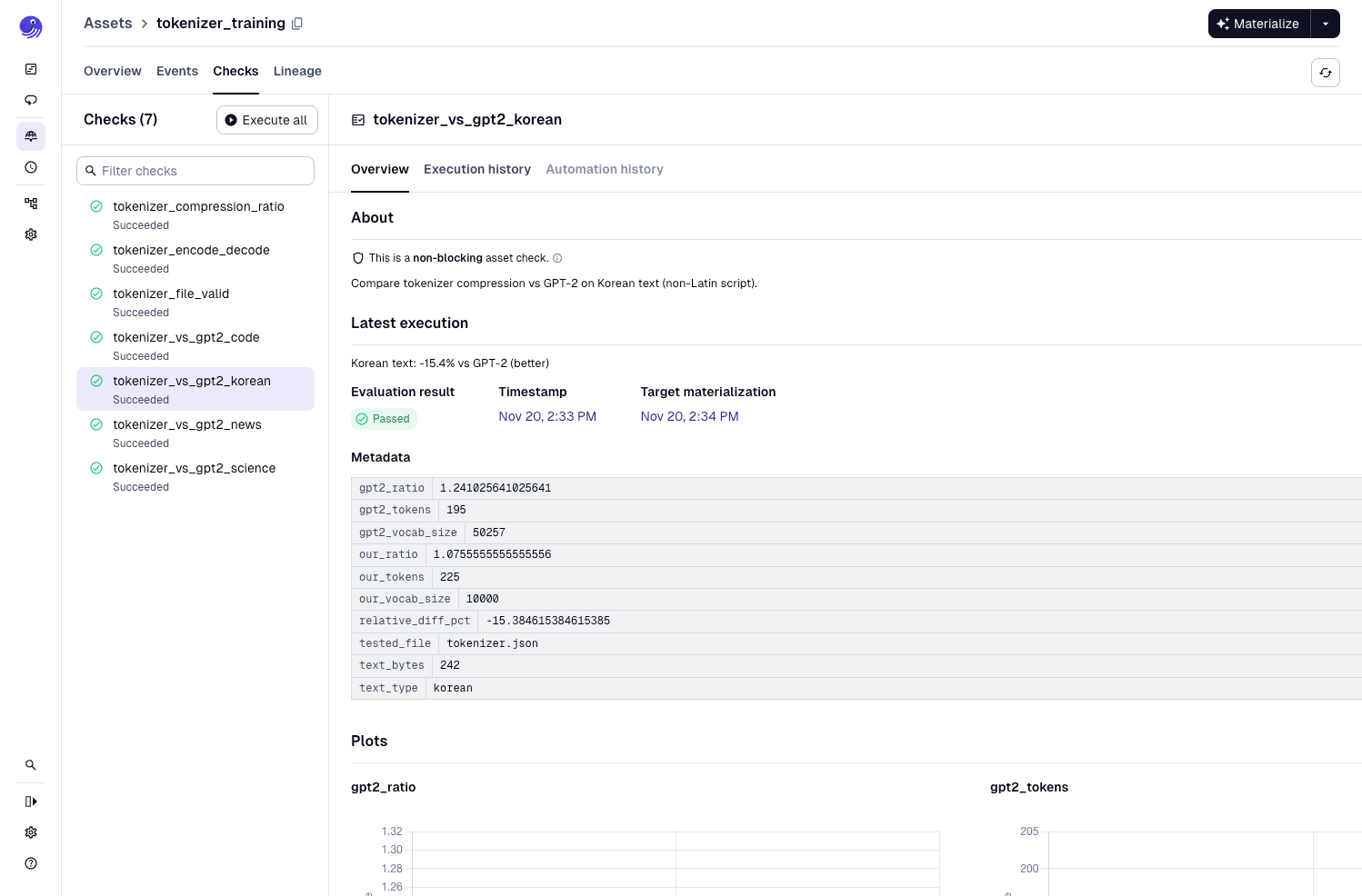
This approach also lets us track changes over time. If we modify the tokenizer code or process different amounts of text shards, we can immediately see how the behavior shifts.
Coming Next: Training the Model
In the next part of the series, we will begin shaping the modeling workflow. This is where we start working with GPUs, model configurations, distributed training, and all the practical considerations that come with running real training jobs.
The modeling code from nanochat will still do the heavy lifting. What you will see is how Dagster continues to guide the workflow so that experimentation becomes smoother, iterations remain traceable, and the entire process is far easier to operate.




.jpg)
.png)
.jpg)



.png)

