



This tutorial shows you how to combine Langchain, Airbyte, and Dagster to build maintainable and scalable pipelines for training LLMs.
Training Large Language Models (LLMs) requires appropriate contextual data. Typically, this data is dispersed across a plethora of sources, including books, websites, articles, open datasets, external services, and an array of databases and data warehouses. Maintaining this data's freshness necessitates a robust pipeline, which transcends the scope of ad hoc shell or Python scripting.
Dagster can assume a pivotal role in LLM training by orchestrating the services involved, running ingestion tasks, transforming and structuring your data and making it readily available for your LLM. When paired with an ingestion tool such as Airbyte and a framework for developing applications powered by language models like LangChain, the task of making data accessible to LLMs becomes not only feasible but also maintainable and scalable.
This article describes the process of establishing such sophisticated data pipelines.
Overview of what we’ll be building
The first step in training a LLM is to aggregate or ingest the data set that the LLM will be trained on.
Popular public sources to find datasets include Kaggle, Google Dataset Search, Hugging Face, Data.gov, UCI’s Machine Learning Repository, Wikipedia/WikiData, and many others.
The data then needs to be transformed, cleaned and prepared for training.
Let’s start with the data ingestion step, using Airbyte. In step 1 we will set up a connection in Airbyte to fetch the relevant data. Airbyte supports hundreds of data sources or lets you implement your own:
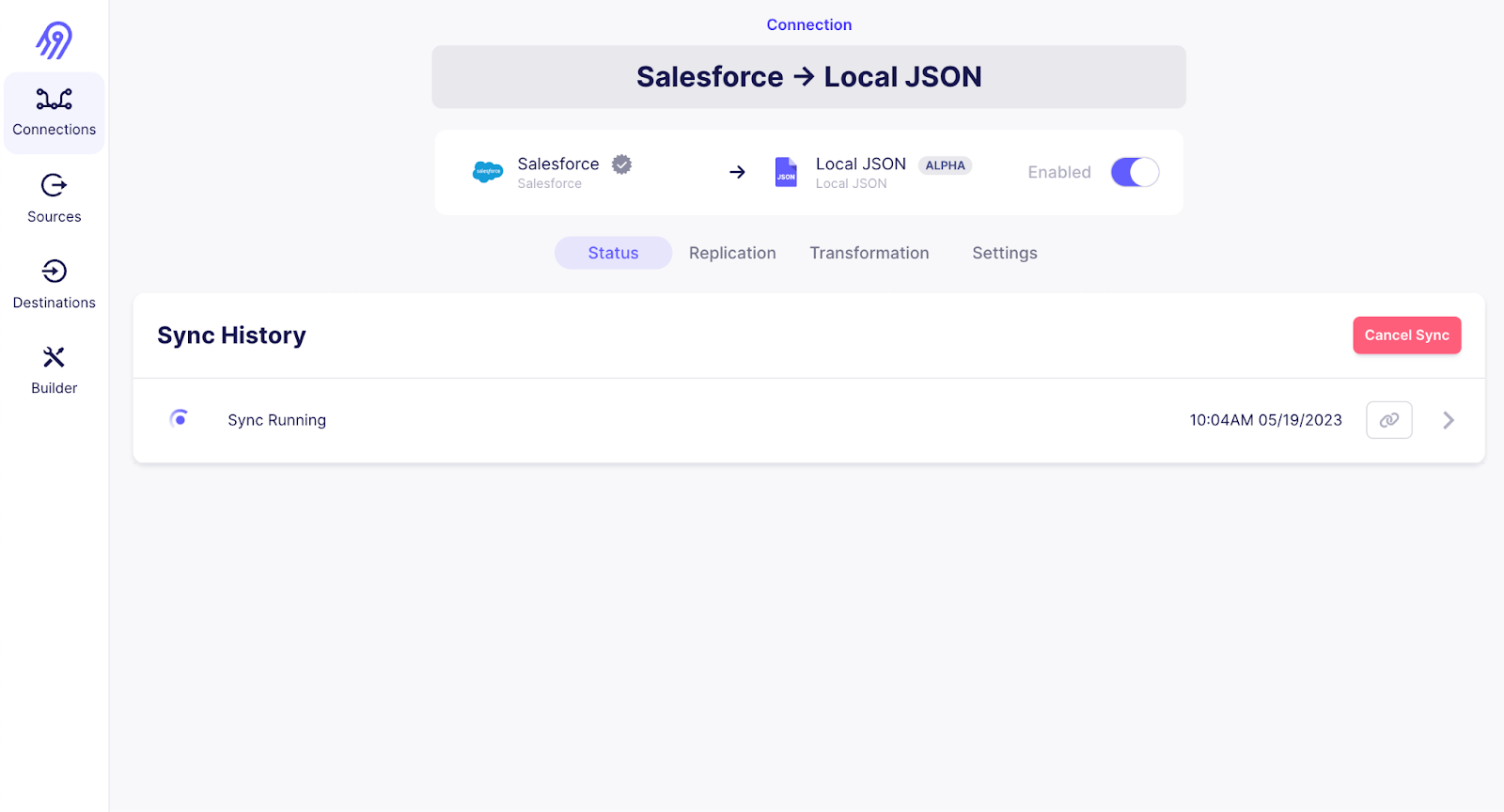
In step 2, we will configure the pipeline in Dagster to process the data and store it in a vectorstore.
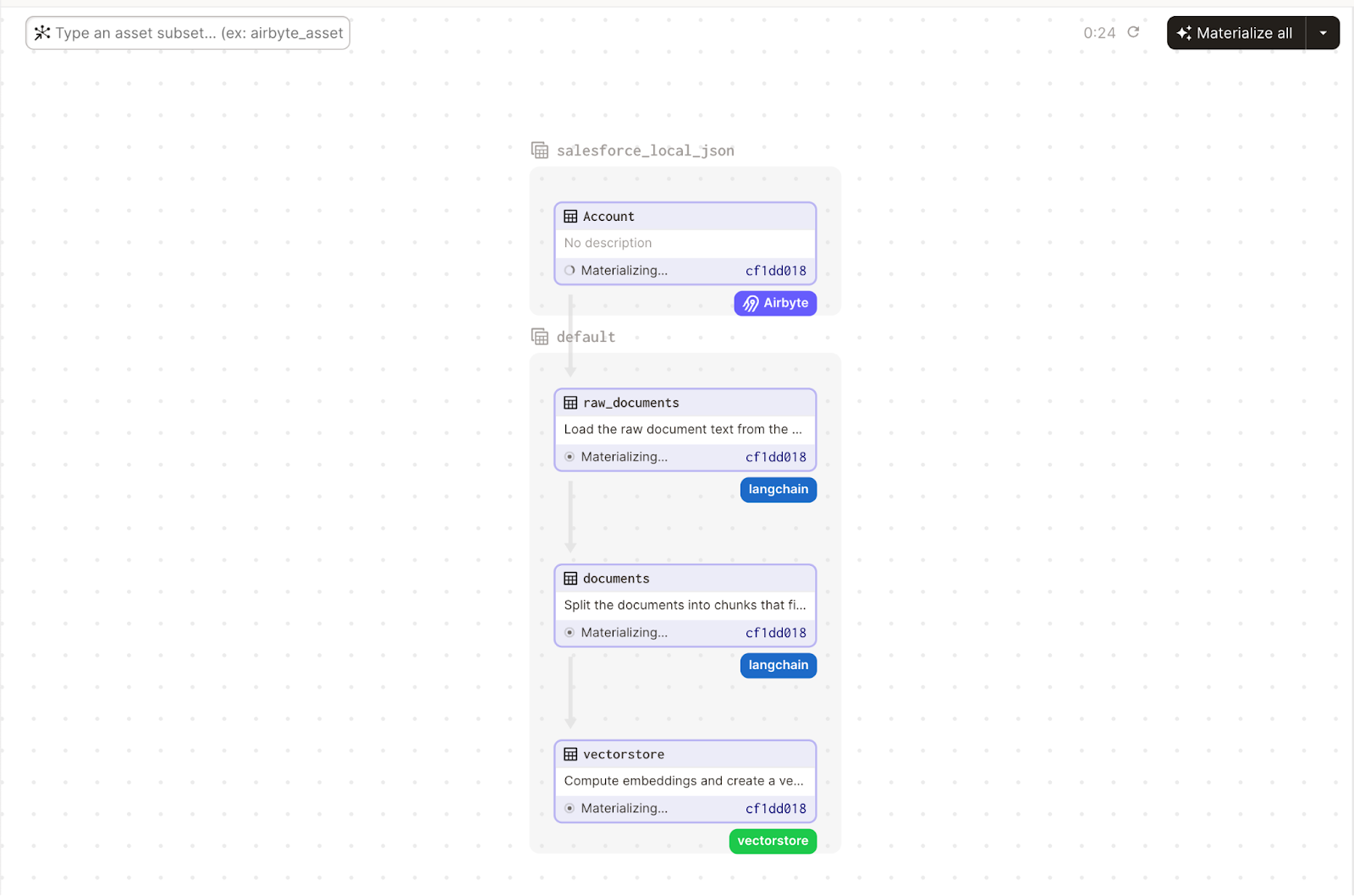
In step 3 we will combine contextual information in the vectorstore using the LangChain retrieval Question/Answering (QA) module:
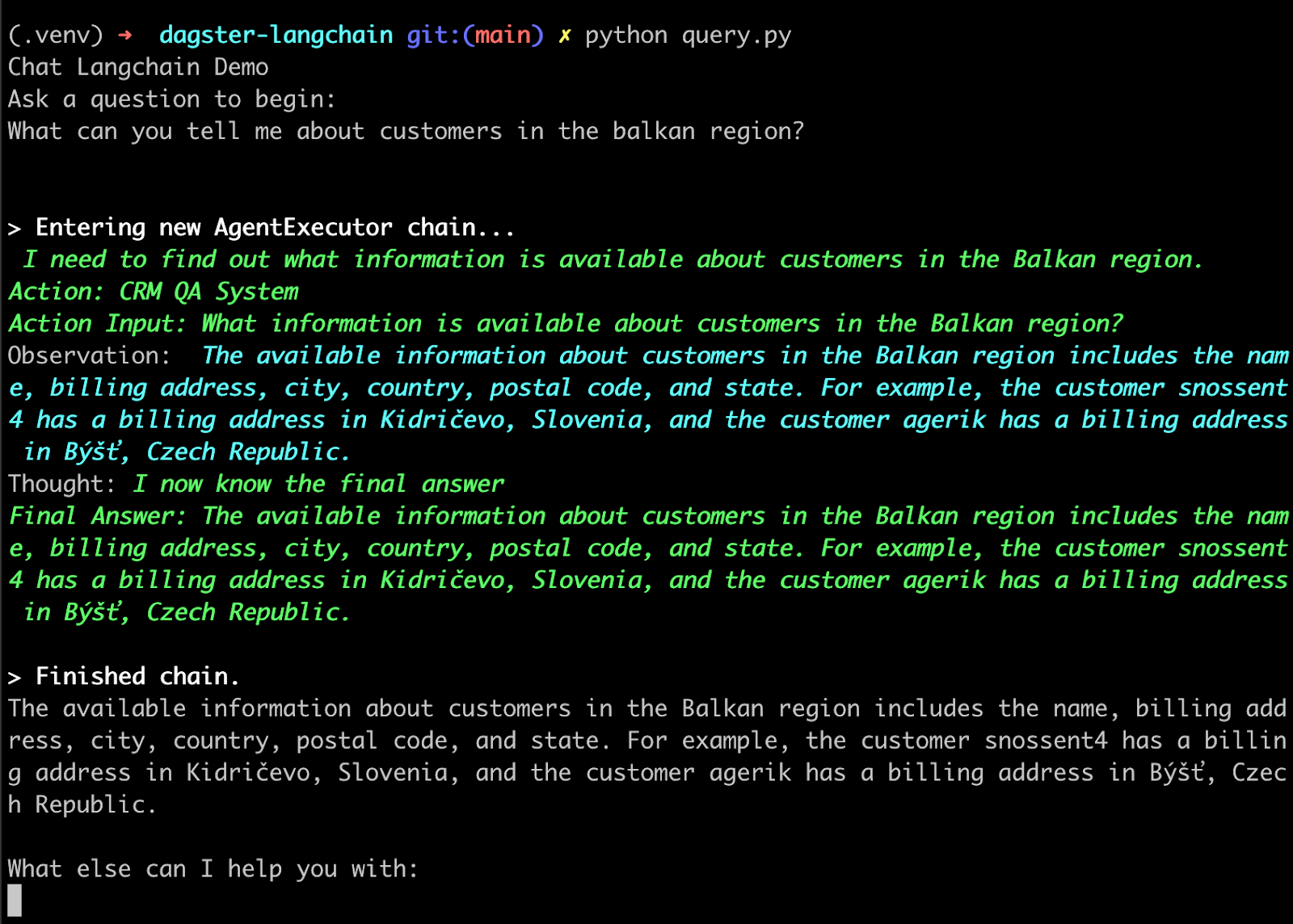
The final code for this example can be found on Github.
Prerequisites for Training LLMs
This is not a beginner’s tutorial and we will assume you are familiar with Python, working with command line, and have a basic familiarity with Dagster.
To run, you need:
- Python 3 and Docker installed locally
- An OpenAI api key
- a number of Python dependencies that can be installed as follows:
Bash
Step 1: Set up the Airbyte connection
First, start Airbyte locally, as described in the Airbyte README.md file and set up a connection:
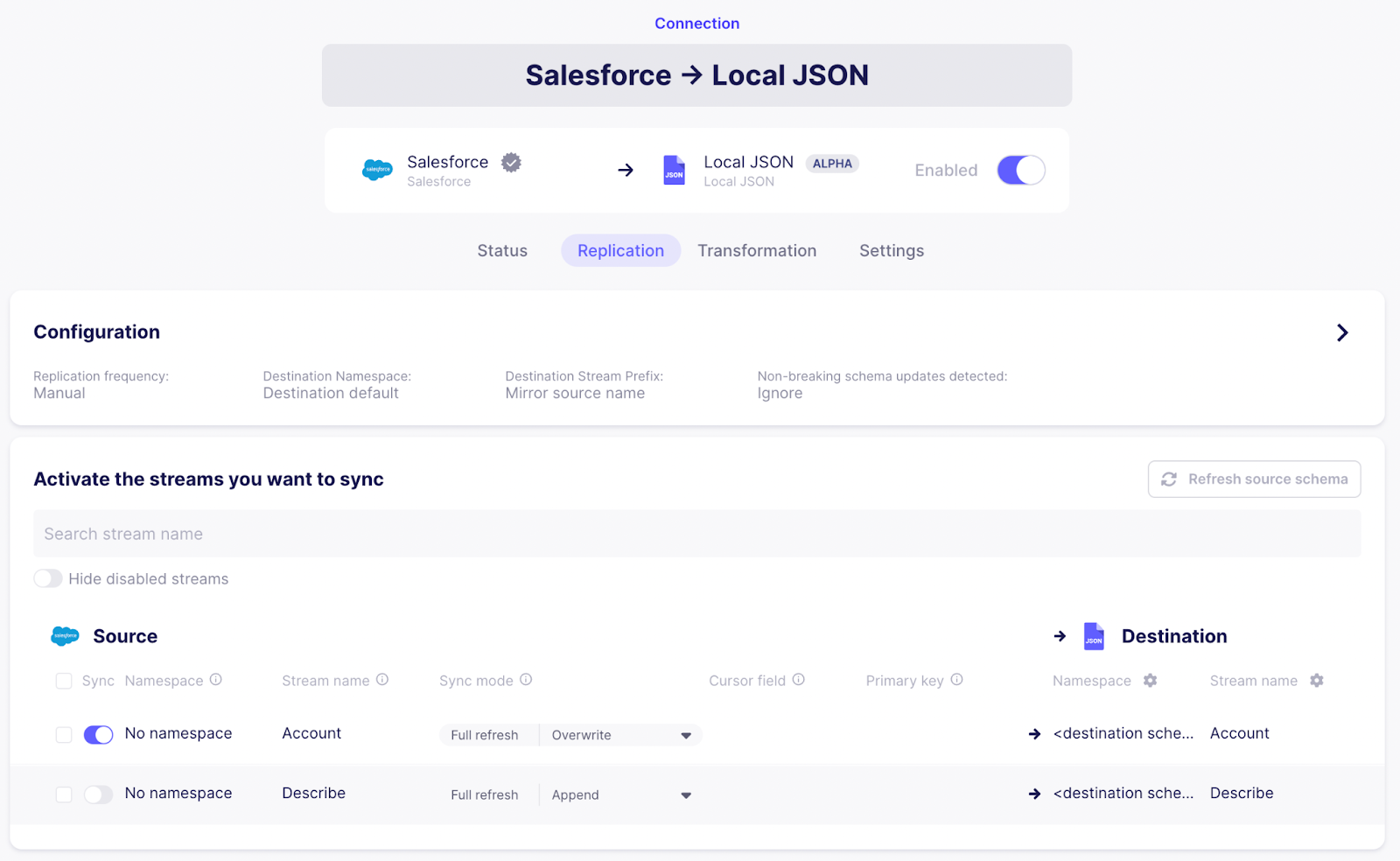
- Configure a source - if you don’t have sample data ready, you can use the “Sample Data (Faker)” data source
- Configure a “Local JSON” destination with path /local - Dagster will pick up the data from there
- Configure a connection from your configured source to the local JSON destination. Set the “_Replication frequenc_y” to manual, as Dagster will take care of running the sync at the right time.
- To keep things simple, only enable a single stream of records (in the example below, we select the “Account” stream from the Salesforce source)
Step 2: Configure the pipeline in Dagster
Configure the Software-defined Asset graph in Dagster in a new file ingest.py:
First, load the existing Airbyte connection as Dagster asset (no need to define manually). The load_assets_from_airbyte_instance function will use the API to fetch existing connections from your Airbyte instance and make them available as assets that can be specified as dependencies to the python-defined assets processing the records in the subsequent steps.
Python
Then, add the LangChain loader to turn the raw jsonl file into LangChain documents as a dependent asset (set stream_name to the name of the stream of records in Airbyte you want to make accessible to the LLM - in my case it’s Account):
Python
Then, add another step to the pipeline splitting the documents up into chunks so they will fit the LLM context later:
Python
The next step generates the embeddings for the documents:
Python
Finally, define how to manage IO and export the definitions for Dagster. In this example, we are using the default IO manager which will save the results to a pickled file on the local system:
Python
See the full ingest.py file here
Step 3: Load your data
Now, we can run the pipeline:
- Run
export OPENAI_API_KEY=<your api key> - Run
dagster dev -f ingest.pyto start Dagster - Go to
http://127.0.0.1:3000/asset-groupsto see the Dagster UI. You can click the “Materialize” button to materialize all the assets. This will run all steps of the pipeline:- Triggering an Airbyte job to load the data from the source into a local jsonl file
- Splitting the data into nice document chunks that will fit the context window of the LLM
- Embedding these documents
- Storing the embeddings in a local vector database for later retrieval
- Now, a
vectorstore.pklfile showed up in your local directory - this contains the embeddings for the data we just loaded via Airbyte.
Alternatively, you can materialize the Dagster assets directly from the command line using dagster asset materialize --select \* -f ingest.py
Step 4: Create a simple QA application with Langchain
The next step is to run a QA chain using LLMs. Create a new file query.pyand load the embeddings:
Python
Initialize the LLM and QA retrieval chain based on the vectorstore:
Python
Add a basic way of quering the model with a question-answering loop:
See the full query.py file here
You can run the QA bot with OPENAI_API_KEY=YOUR_API_KEY python query.py
When asking questions about your use case (e.g. CRM data), LangChain will manage the interaction between the LLM and the vectorstore:
- The LLM receives a task from the user.
- The LLM queries the vectorstore based on the given task.
- LangChain embeds the question in the same way as the incoming records were embedded during the ingest phase - a similarity search of the embeddings returns the most relevant document which is passed to the LLM.
- The LLM formulates an answer based on the contextual information.
How to build on this example
This is just a simplistic demo, but it showcases how to use Airbyte and Dagster to bring data into a format that can be used by LangChain.
From this core use case, there are a lot of directions to explore further:
- Get deeper into what can be done with Dagster by reading this excellent article on the Dagster blog
- Check out the Airbyte catalog to learn more about what kinds of data you are able to load with minimal effort
- In case you are dealing with large amounts of data, consider storing your data on S3 or a similar service - this is supported by Airbyte S3 destination and built-in Dagster IO managers
- Look into the various vectorstores supported by LangChain - a managed service like offered by Pinecone or Weaviate can simplify things a lot
- Productionize your pipeline by deploying Dagster properly and run your pipeline on a schedule
- A big advantage of LLMs is that they can be multi-purpose - add multiple retrieval “tools” to your QA system to allow the bot to answer to a wide range of questions
- LangChain doesn’t stop at question answering - explore the LangChain documentation to learn about other use cases like summarization, information extraction and autonomous agents
This article was written by Joe Reuter, software engineer at Airbyte. You can find the ortiginal article here.





.jpg)
.png)



.png)

