



We adopted Astral’s new Python type checker, ty, to speed up type checking in the Dagster monorepo. The performance gains were dramatic, but the bigger surprise was that ty caught real runtime bugs Pyright missed. Here’s what we learned migrating a large Python codebase incrementally to ty.
Dagster is a large Python monorepo with more than 100 packages, a steady stream of community and internal contributions, and a CI pipeline that runs on every pull request.
For years, Pyright was our type checker of choice. It was a major step up from Mypy while remaining fast, reliable, and deeply integrated into the Python tooling ecosystem. But as the codebase grew, type checking gradually became one of the slowest steps in our CI pipeline. Our Pyright OSS job was often taking around 15 minutes on every pull request, and across the volume of changes we process, that added up to a substantial amount of engineering time spent waiting on static analysis.
We started evaluating alternatives and ultimately completed a full migration of the Dagster codebase. But the most interesting part of the migration wasn’t the performance improvement. But we started finding real bugs Pyright had previously accepted.
What is ty?
ty is a new type checker developed by Astral, the team behind ruff and uv. We were already heavy users of ruff and uv, which had delivered major improvements in performance and developer experience. So when Astral announced a type checker claiming to be 10–60× faster than Pyright, we wanted to try it on a real production codebase.
On the Dagster monorepo, our Pyright OSS CI step frequently took around 15 minutes. After migrating to ty, the equivalent ty-oss step now completes in roughly 1–2 minutes on the same repository.
Combined with a Rust-native parser and analysis engine, this makes both CI runs and editor feedback dramatically faster.
But after introducing ty, the most interesting result wasn't the speed. It was what the type checker started finding.
How ty found real bugs
When we first pointed ty at the Dagster codebase, it reported roughly 4,500 diagnostics. That number sounds alarming, but it’s expected when introducing a stricter type checker to a large existing codebase. Many of the issues were false positives or places where ty’s inference was still rough around the edges.
But not all of them.
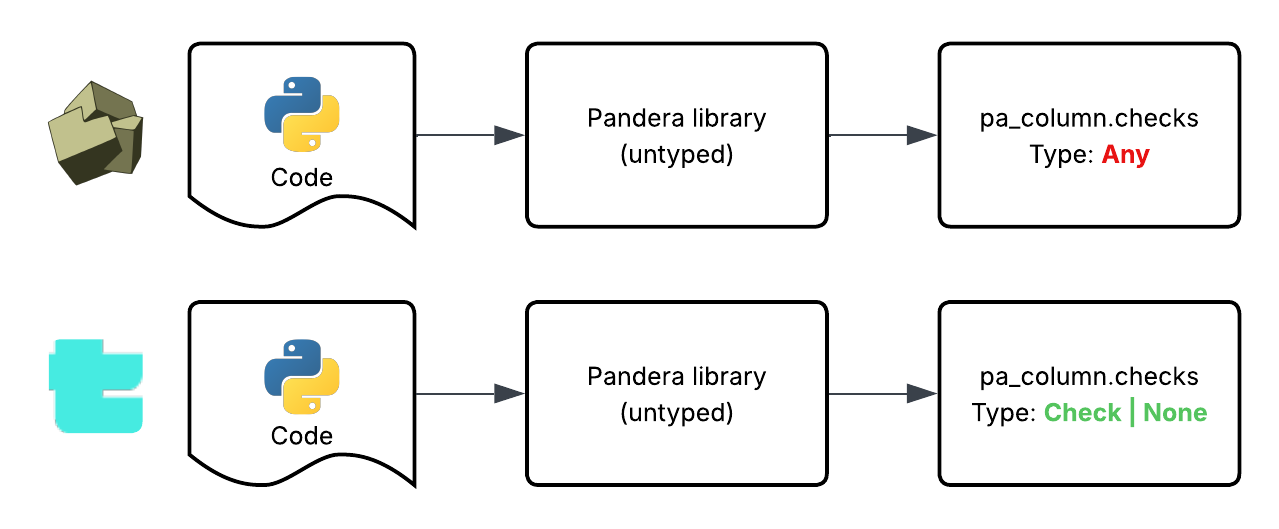
One diagnostic immediately stood out while migrating dagster-pandera. The original code looked like this:
other = [
_pandera_check_to_column_constraint(pa_check)
for pa_check in pa_column.checks
]ty flagged this with a not-iterable diagnostic. Pyright didn’t. ty inferred that pa_column.checks could be None, making the iteration unsafe at runtime. The fix was straightforward:
other = [
_pandera_check_to_column_constraint(pa_check)
for pa_check in (pa_column.checks or [])
]Under certain Pandera schemas, users could hit this path and trigger a runtime TypeError. ty surfaced the issue immediately.
The interesting part wasn’t just that ty found a bug. It was that Pyright had accepted the same code for years.
Initially, we assumed the difference was related to how Pyright handles untyped third-party libraries. But that explanation turned out to be incomplete. Pandera ships a py.typed marker, so Pyright was not treating its APIs as Any.
The difference instead seems to come from subtler differences in inference and type narrowing between the two checkers. In this case, ty propagated inferred types through the dependency interaction in a way that exposed the possible None path, while Pyright accepted the code without complaint.
More broadly, ty consistently surfaced more diagnostics during the migration. Some were false positives, but others exposed legitimate runtime issues that had survived years of static analysis.
The tradeoffs of stricter inference
ty consistently produced more diagnostics during the migration, and some of those were false positives or cases where the inference engine was still rough around the edges. But a meaningful subset represented legitimate bugs or unsafe assumptions that had survived years of Pyright checks.
The Pandera example was one instance of this, but it wasn’t isolated. Across the repository, ty generally propagated inferred types more aggressively through dependency interactions and control flow, which led it to report additional potential runtime issues.
That tradeoff ended up being worthwhile for us.
The total suppression count increased by about 10% overall, but the shape changed substantially: thousands of Pyright-specific suppressions disappeared, replaced by targeted # ty: ignore[...] suppressions tied to specific diagnostics.
In practice, that made the suppressions easier to reason about and easier to revisit over time as ty’s inference improves.
How we migrated
We migrated incrementally. With more than 100 packages and roughly 4,500 initial ty diagnostics, switching the entire Dagster codebase at once would have been impractical.
This would also have also been a large undertaking for our development team. However the rollout was almost entirely agent-driven. Instead of manually working through thousands of diagnostics, we used parallel coding agents to process packages independently: running ty, applying straightforward fixes, adding targeted # ty: ignore[...] suppressions for false positives, and preparing migration PRs.
That changed the economics of the migration substantially. Once the workflow was established, migrating packages became highly parallelizable work rather than a long sequential cleanup effort.
We started with smaller, well-typed libraries to validate the process before moving on to larger and more complex packages. In the end, the migration completed across roughly 100 incremental PRs spanning the full repository.
The rough edges
ty is still pre-1.0, and adopting it across a large monorepo wasn’t completely frictionless.
The biggest challenge was diagnostic noise. Starting from roughly 4,500 diagnostics, we found that some checks were initially too noisy for our codebase, especially in older packages with looser typing assumptions.
We handled that noise package-by-package. Rather than globally disabling broad categories of diagnostics, we added targeted # ty: ignore[...] suppressions where the issue was either a false positive or not worth addressing immediately.
That kept the migration moving without weakening the signal everywhere else.
None of these issues were blockers. They were the kinds of tradeoffs we expected from adopting an early-stage tool, especially one evolving as quickly as ty.
Where we are
The migration is now complete. Dagster has fully transitioned from Pyright to ty across the entire monorepo, including the core python_modules/dagster package, dagster-webserver, dagster-dbt, dagster-aws, and the broader library ecosystem.
The results have been substantial:
- OSS type-checking CI time dropped from roughly 15 minutes to 1–2 minutes
- local feedback loops became dramatically faster
- ty surfaced real runtime issues Pyright had previously accepted
- the migration completed across roughly 100 incremental PRs
- parallel coding agents made the rollout practical at repository scale
There are still rough edges. ty is early, the diagnostics can be noisy, and adopting a pre-1.0 type checker across a large Python monorepo required a meaningful amount of migration work.
But even in its current state, ty is one of the most promising pieces of Python tooling we’ve used recently. The performance improvements alone materially changed the developer experience on the Dagster codebase, and the stricter inference model has already proven valuable in practice.





.jpg)
.png)



.png)

