




A complete guide with all the insights, tips, and some predictions for the data platform engineer, just like an Almanack provides, with practical information for daily life.
I have read the "Poor Charlie's Almanack" by Charlie Munger and thought about what it would take to write one for Dagster. A complete guide with all the insights, tips, and some predictions for the data platform engineer, just like an Almanack provides, with practical information for daily life.
My goal is to offer a collection of wisdom, insights, and principles gathered over the years. Giving you an outside view from someone who has used Dagster since back in 2019, used it at enterprise scale but also for my hobby projects (e.g. real-estate project). The piece should give you a holistic view of Dagster's place in the data ecosystem, how to deal with the complexity of data architecture and enterprises, and scaling your data jobs.
This article shows you how orchestrators such as Dagster are built for an open data platform that integrates the full data ecosystem, with the shift to data assets instead of DAGs, reducing complexity and applying data engineering best practices.
Almanack (also spelled "almanac") refers to a publication containing a variety of information on a dedicated topic. The modern usage of Almanack, particularly in the context of books like those by Charlie or Naval Ravikant, is often metaphorical. It suggests a collection of wisdom, insights, or principles gathered over time.
What is Dagster
In late 2018, on a co-working and co-living sabbatical in Bali, I was searching for something to bring the data warehouse out of the drag-and-drop world of SSIS and Oracle reporting and into a code-first, developer-friendly workflow. I looked at ODE, BiGenius, TimeXtender, and WhereScape, but found that none of them quite fit my open source and programmatic preferences, so I tried to build something myself but didn't succeed. A year later, back at my 9-to-5 in Copenhagen, I heard Nick Schrock on the Data Engineering Podcast describing the motivation and story behind a Python framework called Dagster that did exactly that. I was hooked, and have used Dagster ever since.
Early Focus on Developer Friendliness
To understand the context of 2019, you must understand that back then, most ETL jobs were triggered with cron or bash scripts, and if there was an error, the only option was to re-run in the next nightly window where production wasn't touched. Dagster, as explained by Nick in the podcast, focused on developer-friendliness, in particular for ETL developers back then, and that focus hasn't changed today for data engineers.
So what is Dagster? The original idea, started in 2018 during a sabbatical after Nick worked at Facebook, came with this definition:
One of the goals of Dagster has been to provide a tool that removes the barrier between pipeline development and pipeline operation, but during this journey, he came to link the world of data processing with business processes.
Today the definition hasn't changed much and reads like this from the Dagster Docs:
Dagster is a data orchestrator built for data engineers, with integrated lineage, observability, a declarative programming model, and best-in-class testability.
The initial definition to "link data processing with business" was the key reason that brought me to it, along with the quality of how the components were implemented. Even more compelling was Nick's visionary outline for 3-5 years ahead: to make the work of data engineers similar to software engineers, and make their daily life easier.
Biggest Shift Early On
This vision led to many new concepts Dagster originally created, which we take for granted in today's data work, and shifted the work into a more reliable and useful toolset for data engineers.
Data-aware Orchestration Shift
One of the biggest shifts compared to previous tools and orchestrators was that orchestration was fully data-aware from the very beginning. It tried to understand the heterogeneous complexity that exists at every small to large enterprise company, and thrive in it, supporting the full data engineering lifecycle with its platform and data pipeline capabilities built in.
This gave me a toolkit for building reliable data pipelines out of the box early on, with battle-tested features through its users (open-source) and a quality and thoughtfulness I hadn't seen before. This was personified by Nick and could be vividly felt in the early interviews, but also in the code that the team produced openly on the repo.
For example, backfilling, restartability, or Spark integrations were open on GitHub, to use, and to adapt to your needs. It was a bit like dbt, but instead of modeling your SQL queries, you'd model your data pipelines and integrate complex data architecture.
This also meant that moving datasets or integrating dependencies is strongly supported, not an afterthought. In Dagster you can use resources to work with Polars, Pandas, Arrow, DuckDB, or anything else to pass datasets, and reference data assets declaratively, or even non-existing ones as Dagster knows to create the assets. Compared to Airflow, where you could load only small data with XCom for the longest time[1], this makes code simpler to understand and maintain.
Resources also decouple storage from compute. You could use Apache Spark locally with a single JAR file and in test use a full-blown cluster, or use MinIO as an S3 interface with simple bucket configuration and in production an S3 server from Amazon. Both are interchangeable without changing pipeline logic, by pure configuration — that's the beauty of declarative data systems, and Dagster embraces this to this day.
Shift to Data-Asset Based Orchestration
Dagster was super early in shifting from DAGs and operational task-based orchestration to asset-based ones such as BI dashboards, tables, reports, ML models — artifacts the user actually cared about. Everything shifted from an imperative approach to a declarative one like Kubernetes or React, where you define what the dataset must or should have, and Dagster takes care of the implementation logic, mapping it to the configured filesystem, compute engine or cluster.
Now you could quickly describe each pipeline with declarative notations like update: daily or change to update: monthly, or if more advanced, you could define a small sensor logic that checks S3 for updates. Instead of implementing all logic in a data pipeline, we apply the logic directly to the asset and closer to the data, which makes it more transparent and integrated into the full data lineage. When updates happen, we have the full graph, but also a leaner and easier-to-maintain setup.

Going from typical DAG and task-based-oriented (first line) to asset-based DAG (exploded view) | More at Declarative Orchestration
Or zoomed out - you see the focus on the assets, the tables themselves:

Global asset lineage, zoomed out. You see how the task-based view goes from function to function, from download to serve (each of which potentially hides multiple tables), where assets go from dataset to dataset, giving you much more information. | More at Dagster Data Orchestration walkthrough
This led later to "Software-Defined Asset" and its mental model where you can define an asset pre-runtime and declare connections to upstream or downstream data assets (e.g. real-time housing prices that we fetch from a webpage that does not exist beforehand). Now we can already build and implement our graph and data lineage without having to physically create the dataset first. Software-defined assets use code to define the data assets and are version-controlled through git and inspectable via tooling. This transparency allows anyone in your organization to understand the canonical set of data assets and reproduce them at any time, and also lays the groundwork for asset-based orchestration.
As Rich Hickey said, the aesthetics of a programming language do not matter, only the outcome. Assets play into that fact. In data engineering terms, it's not code but data pipelines and DAGs, but what everyone cares about are their outcomes: the data assets.
That led to the shift from working with tasks and DAGs to data assets. That's the developer-friendliness built in from day one: develop locally and deploy to test and production, with infrastructure and technical implementation decoupled from business logic.
It made Dagster a bit more complex to start with — you need to know more upfront — but since every enterprise hits these data engineering challenges eventually, it's better to embrace the fact and build for it. The result was an improved developer velocity, but what I noticed, too, was the joy of building reliable data pipelines, equipped with tools that helped me deal with errors, infrastructure, multi-tenancy, data science, big data, and everything thrown at me back then.
Not only single Purpose
When I first introduced Dagster at my previous company, all of a sudden other teams started to take notice and also wanted Dagster for other work such as provisioning infrastructure with one-click deployment. Especially the cloud platform team needed a tool to automate its scripts to deploy on Kubernetes, OpenShift, and everywhere else, but other teams also had needs to automate. With Python as the programming language for Dagster, reading from an external FTP server, transforming the data, and uploading it somewhere via API were not multi-month projects across different teams. Dagster's flexibility and integration into other tools and systems were a key strength for most teams.
Observability and monitoring were another addition. Every run was logged in the UI and everyone could see the rich metadata of each pipeline run. And because it was open source and had a rapidly growing community, support and ideas didn't run out.
Dealing with the Complexity of Enterprise Systems
If you have worked at any company larger than 10 people, you have noticed pretty fast that you are dealing with multiple source systems, different CRMs, different ERPs, multiple cloud platforms. Most enterprises have all major cloud platforms running in production, whether it is Amazon services, Google GCP, Azure, or any other major platform. You as the data engineer are the one making sure to integrate them, and basically deal with the complexity that comes with it.
How to Reduce Complexity?
First, acknowledge it: heterogeneous data complexity is a fact of the enterprise data lifecycle. Second, lean on tooling with technical integrations and written code that implements each vendor's API, so we don't build everything from scratch repeatedly. Third, work around the actual data assets the users want, not DAGs. With assets we declare outcomes, tests, and dependencies, and the system handles the rest. That cuts dependency hell, an unproductive Software Development Lifecycle, and the fear of change.
Composable is Making Systems Simpler
A more holistic framing comes from Simple Made Easy by Rich Hickey, creator of the Clojure functional programming language, where he debates what makes systems complex: state and objects, lots of vars, syntax, inconsistency. His conclusion is that composable is what makes systems simpler (like in music for a composer, which is what he created Clojure for): the ability to assemble, reassemble, and swap individual components into a flexible whole.
Dagster has exactly that ability, too. It integrates the core principles of Functional Data Engineering — pure and idempotent tasks, immutable partitions, reproducibility, versioning — directly into the framework.
State, Hickey points out, is never simple. Unfortunately for us, data engineering is all state: every datum is tied to a timestamp of when it was created, processed, or backfilled. Fortunately, helping us manage that state is what Dagster does: data assets, virtual assets, partitions, incremental materialization, and partitioned asset checks that evaluate a specific partition of an upstream asset instead of the whole dataset.
Rich concludes "Simplicity is a choice", echoing Leonardo Da Vinci:
Simplicity is the ultimate sophistication
(Open) Data Platform
But how did the shift and the data engineering principles evolve, and how can we apply these as a unified solution?
With Dagster's data-aware orchestration, shift to assets, separation of concerns, and multi-use, we are automating harder data and infrastructure deployment problems, and Dagster solves the problem of managing complex data environments more holistically. To me, it feels as though Dagster gave me this peace of mind and the toolset to simplify data engineering in a complex environment early on, and is the right tool for the ultimate sophistication for data work.
Dagster's approach is composing a data orchestrator that integrates into any type of data work: from data integration with dlt, to transformation with dbt or just Python logic, to updating BI dashboards, to deploying on Kubernetes, all into a unified system. A fully open data platform, making orchestrating data and its flow simpler.
All of these features, combined with DevOps deployment strategies, make Dagster one of the data platform tools that has:
- An integrated UI and control plane for seeing what's going on, unifying all your tools into a single webpage.
- Lets you see your data assets in a list with extensive metadata: it's your data catalog showing all tables, BI dashboards, reports, and other data assets.
- Keeps and creates all the metadata when we run data pipelines across all data systems: With end-to-end access, we can also have metadata and data lineage end to end, which helps us understand where the data comes from, and in case of error, where the bad data is.
- Has integrated scheduling, sensors, backfills, and concepts to work with data, built in.
- Supports multi-team isolation through code locations, so different teams can own different parts of the platform without stepping on each other.
As Dagster is open source, it gets promoted from a usual data orchestrator to an open data platform, with the great advantage of transparency: easily patching an error or integration if you need to integrate an obscure system that only your company has, working on the cutting edge with the community, or getting features from them.
The Venn diagram of Dagster - Obviously you can't optimize a data platform in all directions. If you look at Dagster as a Venn diagram, it has these three circles: the right abstraction, flexibility, and full automation through programmability.
Control Plane: Center with All Metadata
It integrates multiple different teams such as data engineers, platform and infra teams, with data science and business people who want to run their jobs. Feature-wise, it provides data catalog and contract capabilities, lets you see data assets you're responsible for and when they last got updated, and shows their downstream and upstream dependencies, all in one real-time observability and monitoring UI.
This is all done through its control plane, which centers all metadata and unifies different data tools along the lifecycle into one platform, something usually only closed-source data platforms achieve. The control plane serves everything in a single view, showing how all processes are working. It's the operational dashboard for your company.
With data orchestration as the heart of data work, with metadata for any process and access to all source systems we're pulling from or intermediate systems, it's in the perfect place to serve as the central metadata store. Think of INFORMATION_SCHEMA, but for overall data work, not only one single database. Only the orchestrator can understand the system and its status this deeply.
Why Open Data Platform: a System that Unifies Open Source
The open in open data platform is interesting, as it's really hard to build a unifying layer across different stateful data systems, and it's worth highlighting that Dagster achieved just that.
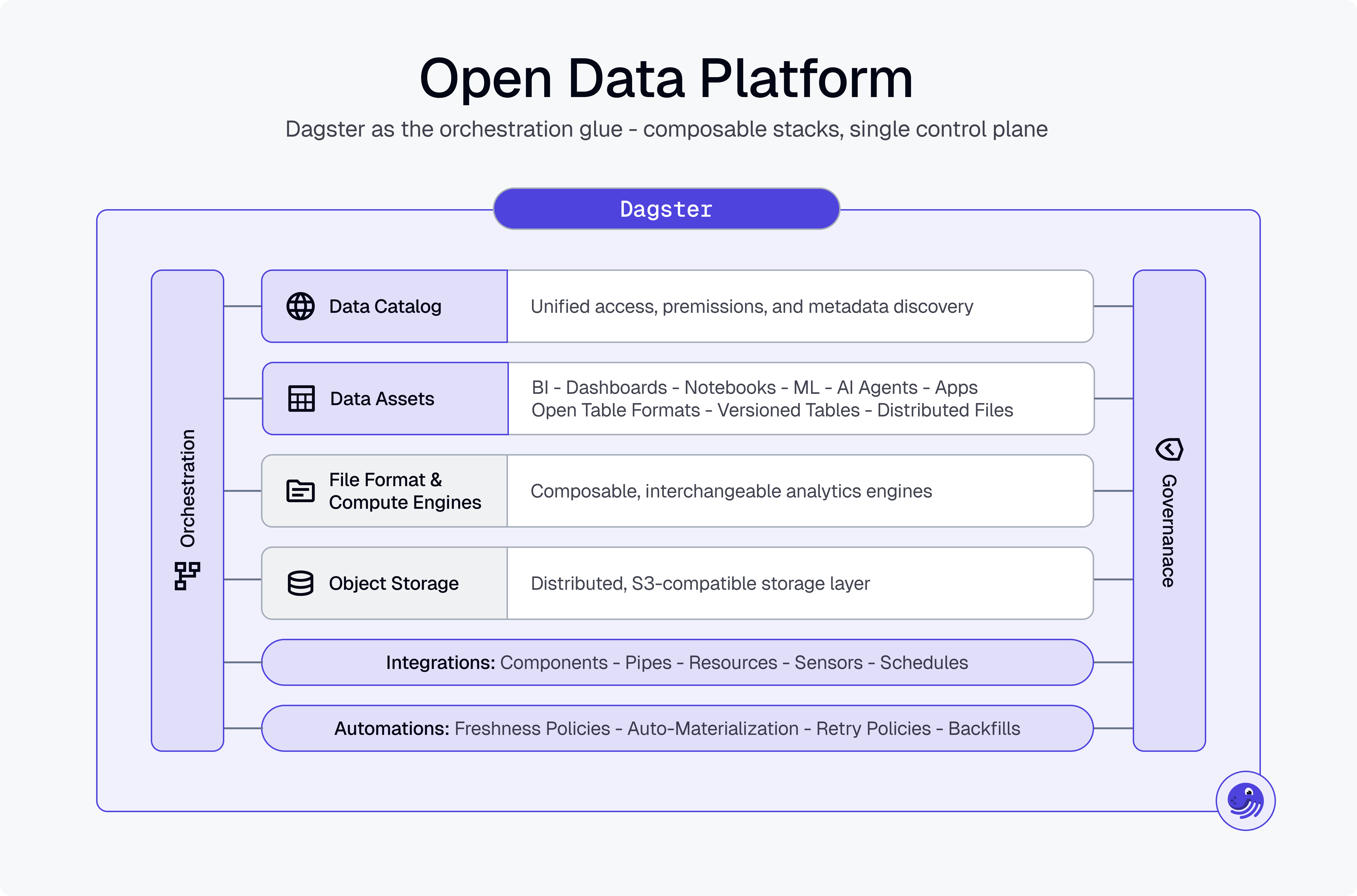
Open Data Platform with Dagster as the integrative data orchestrator into different layers of the data stack — built on open standards, with an open data architecture such as object storage (S3 specs), file formats (Parquet, ORC, Avro), open table formats (Iceberg, Delta, Hudi), and data catalogs. | Legend: Dark blue shaded : Part of Dagster (control plane, orchestration, etc.), light blue: dagster managed metadata, white: external state and systems
If we look at open data stack architecture: unlike cloud data platforms that have the same goal, such as Fabric, Snowflake, Databricks, etc., Dagster builds on open standards and is itself an open standard. It's like a protocol in which we declaratively define our data assets (e.g. Software-Defined Assets, environments, resources) that then get automatically executed with composable computes we define in resources, all interchangeable. Even closed-source engines such as a Databricks Spark cluster work really well.
The hardest part is integrated data governance, lineage, access rights, and compute. An orchestration platform like Dagster doesn't give you everything, but you get most of what you need, in an open and composable way.
Composable Data Stacks Possible
What this architecture allows is what Wes McKinney calls "Composable Data Stacks" in Monday Morning Data Chat, essentially rebundling the data platform.
Composable data stacks depend on compute engines. With this architecture, plus Dagster resources or external code (Dagster Pipes), we can easily pick and choose what is best suited for the task at hand, not only for different jobs but also depending on different environments. Although there will never be one singular tool for everything, it's necessary that we have a layer of integration, and there's no better place than the orchestration layer that separates execution and technical logic from business and already deals with multiple data environments.
Pete Hunt, the CEO of Dagster, said recently:
Our goal is to make AI as lightweight, accessible and cheap as we can to drive enterprise value, while enabling our customers with the infrastructure they need underneath - the orchestration and data platform layer where reliability, support, and recovery actually matter.
Pete is reaffirming that the data platform layer is the priority, so AI can build on top of a great foundation. In the eyes of a data engineer, it's a dream come true to have an open platform that is declarative to simplify the overall architecture, but also uses AI for the glue code, based on best practices enforced through Dagster as the open data platform.
The Right Abstraction Layer for an Open Data Platform
Charlie Munger's Almanack distilled decades of investing wisdom into timeless principles and mental models that compound over time. Here I tried the same for Dagster.
The principles touched on won't be obsolete next year. Data-aware orchestration, declarative assets over imperative DAGs, separation of business logic from infrastructure, and composable stacks with a single control plane are all mental models for building data platforms that hold up whether you're running DuckDB on a laptop or Spark across three cloud providers.
Eight years after discovering Dagster on a podcast during my time in Copenhagen, I'm still reaching for it whenever a system gets complex enough to need real orchestration. With extensive built-in data quality checks, best practices like unit-testing, local development to prod, separation of business and technical logic, code locations, Domain Specific Languages (DSLs) for non-technical people, pipes and components to run something in Rust or Go, and many more, the Dagster data platform gives you huge leverage building from strong foundations, with the flexibility to change along the way.
It's the abstraction layer for data engineering to solve hard business problems, an open data platform with opinionated design decisions that compound the longer you build on them.
In the next piece, I'll get into what it actually takes to operate this — architecture, deployment, and governance — as a follow-on to these principles.
Next steps
Find Dagster's official skills for the latest and most updated way of working with Dagster, to feed to your AI agent. Or read the blog post with more information. If using Airflow, migrate from Airflow, or use Airlift for an integration for legacy and critical DAGs still in Airflow.
Find awesome-dagster, and check out further readings of mine at Data Integration as Code: Configuring Airbyte and dbt with Python (Dagster) or Data Orchestration Trends: The Shift From Data Pipelines to Data Products.
Want to use all of this stress-free without the deployment burden? Use Dagster+. Great tradeoff between cloud and OSS, still having the OSS Dagster foundation, but profiting from extra features (GitHub integration, cloning, etc.) and not needing to set up a DevOps pipeline or fiddle with Kubernetes.





.jpg)
.png)



.png)

