



How a solo data team delivered a custom system to accelerate data transformation.
Erewhon: Where Organic Meets High-Tech
In the age of digital transformation, data is the lifeblood of retail. As retailers seek to build best-in-class digital shopping experiences, establishing streamlined and integrated data operations becomes mission-critical.



Enter Erewhon: LA's glitzy, upscale organic grocery chain that's more institution than store. Picture celebrity-curated smoothies, crave-worthy organic fare, and a cult following that demands nothing but the best. Family-owned and operated but not your average mom-and-pop shop—it's a cultural hub where organic purity meets cutting edge. Erewhon members' hunger for a premium experience has birthed a growing technology team in an otherwise “traditional” industry.

This case study explores how Sean Pool— a solo data team—successfully implemented Dagster to jumpstart Erewhon’s overall data strategy and reimagine the scope of what they could do with data.
Through adopting Dagster, Sean transitioned Erewhon rapidly from limited low-code solutions to modern cutting edge tools while up-skilling himself as a data engineer.
"Data engineering is essential at Erewhon, enabling us to deliver personalized experiences, accelerate business growth, and automate the boring stuff." - Sean Pool
The Data Challenge: Growing Pains and Ambitious Goals
Sean joined Erewhon as the first data hire, initially tasked with creating a straightforward analytics and reporting system using PowerBI. However, as the company's data needs expanded, it became clear that a more powerful and scalable solution was necessary. Erewhon's existing data infrastructure, based on low-code solutions and basic BI tools, was facing several limitations.
The current systems struggled to handle the growing volume of data from multiple sources, including legacy databases, events from the Erewhon mobile ordering app, software APIs and more. Data silos across the organization made it difficult to gain a holistic view of the business and customer behavior, and many reporting and analytics tasks were time consuming and manual.
Moreover, Erewhon had ambitious plans to leverage data for business growth. The company aimed to implement sophisticated use cases such as data-driven app features, advanced marketing technology, personalized customer experiences, and streamlined process automation. However, the existing infrastructure fell short of supporting these initiatives effectively. Sean, drawing from his experience as an analytics user of data platforms at Fortune 500 companies, recognized the potential value these advanced systems could create. This insight became the driving force behind Erewhon's data transformation journey.
With this north star in mind, there were significant challenges: budget constraints, a lean team structure with Sean as the sole data team member, and the need to upskill from BI and analytics to more advanced data engineering concepts. Despite these limitations, the solution emerged as a carefully crafted, cutting-edge data stack. By composing the right set of tools, Sean found a way to overcome the resource constraints quickly while still delivering a powerful, scalable data platform that could support Erewhon's growing needs and ambitious data initiatives.
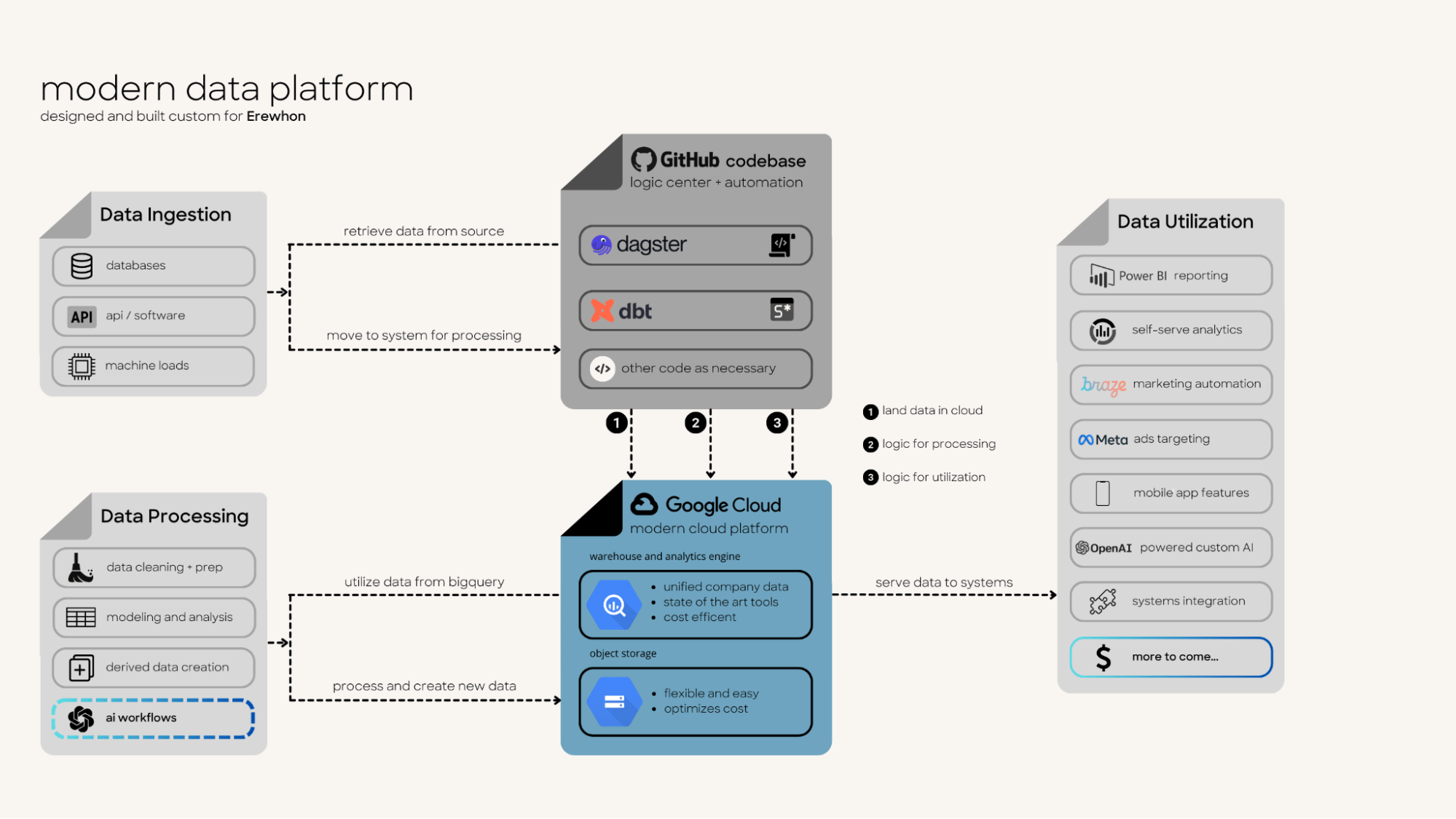
This transformation culminated in the implementation of a code-based system capable of handling a number of different functions. The new platform seamlessly integrated automated reporting, self-serve analytics, marketing automation, targeted advertising, mobile app feature support, systems integration, and AI workflows leveraging internal data. Essentially, Sean had built what could be described as a "monolithic business-focused data platform."
"The secret sauce was choosing the right tools to decrease time to value and build efficiently. For me, some of those time savers are Dagster, dbt, and dlt. These tools, combined with a little bit of Python and SQL, allowed me, as a solo practitioner, to build enterprise-grade data operations at a fraction of the cost. We ended up with a flexible, scalable system that not only meets Erewhon's current needs but also prepares us for future data challenges." - Sean Pool
Transitioning to High-Code Tools
The data team at Erewhon began with basic BI tools and gradually took on more complex data engineering tasks. With his background in business intelligence (BI) and finance, Sean recognized the limitations of low-code solutions for advanced data use cases. The catalyst to begin building this system was the integration of Braze, a popular data-powered marketing platform. After exploring various options, he identified a homegrown system built on Dagster as the clear ideal solution. Dagster's capabilities in streamlining data pipelines, version control, and modular declarative design aligned well with Erewhon’s requirements.
Erewhon’s data platform is deployed on Google Cloud Platform (GCP). Software engineering best practices are followed with CI/CD, and Slack bots monitor and report critical processes using Dagster’s integration.
"As a non-engineer, at first the idea of creating a ‘code-base’ was unapproachable and scary. The first few hours and days were a struggle, but I soon gained confidence with help from the endless library of internet resources available." - Sean Pool
Implementation and Learning Curve
Implementing Dagster was a significant learning experience for Sean, who did not have a formal software engineering background. Sean dedicated considerable time to learning Python and advanced data engineering concepts, using resources like YouTube tutorials, AI coding assistants, and Dagster University.
As Sean's Python skills advanced, he explored various data engineering tools, with Dagster emerging as the ideal orchestration engine. Its intuitive design, modular architecture, and innovative integrations aligned perfectly with his project needs. Sean appreciated Dagster's asset-based pipeline approach, built-in data quality checks, and refined visual UI. Despite the initial learning curve, Dagster's comprehensive documentation and supportive community facilitated a smooth implementation. This experience both solved the orchestration needs and deepened Sean's understanding of data engineering principles.
"For years, my work was fragmented across various drag-and-drop interfaces, spreadsheets, and disconnected systems. Now, with Dagster, I can make swift adjustments and enhancements on the fly through simple code changes in one central location. Visualizing everything in the Dagster UI is a game-changer – it's truly revolutionized my workflow!" - Sean Pool
Achievements and Impact
This data platform approach enabled Erewhon to rapidly bring modern data strategies to the business. The system unified disparate source data from across the company, and enabled modern software tools to be easily integrated in order to put data to work. Dagster’s modular design allowed the team to add new features and use cases incrementally, ensuring the system could evolve with the company’s needs. It began as the customer data platform to power marketing integration with Braze, but after just 9 months many other functionalities and features were quickly added.
The data team also integrated AI and machine learning capabilities into Erewhon’s data pipelines, which has created many additional planned use cases.
"I had seen how powerhouse data teams operate and deliver value at Fortune 500 companies, and wanted to bring those techniques to Erewhon on a small budget. With the right composition of tools this is more democratized than ever, and Dagster is a clear accelerant to my goals as a data practitioner." - Sean Pool
Overcoming Challenges
The data team at Erewhon operates in a lean environment with limited resources. Managing all aspects of the data infrastructure, from development to deployment, tested Sean’s skills and pushed him out of his comfort zone.
Not all challenges were technical. As the solo data engineer, Sean had to secure buy-in from other organizational stakeholders, who were reasonably concerned about the upfront cost of implementing a high-code data stack. From his evaluation this custom solution is magnitudes cheaper for Erewhon when compared to the recommended leading industry SaaS tools.
Sean's strategy for overcoming these challenges involved demonstrating the value of this approach through practical outcomes.
By successfully integrating the customer engagement platform Braze and automating marketing efforts, he showcased the benefits of their data platform. This helped secure the necessary support and resources to continue developing and expanding the system.
Another challenge was the learning curve associated with advanced Python concepts and the specific requirements of Dagster. He invested time in self-education, using resources like Youtube, ChatGPT, and Dagster University to build their skills and knowledge. This dedication paid off, enabling him to develop a powerful and flexible data platform.
Key Benefits of Dagster
Dagster is proving to be an invaluable tool for Erewhon. Its modular and version-controlled design allowed the team to build and maintain complex data pipelines efficiently. This was crucial for a lean team, ensuring that business logic was preserved and easily maintainable. Dagster's integration capabilities enabled the team to incorporate AI and machine learning tools into Erewhon's data workflows, enhancing the company’s data-driven decision-making processes.
One of the most significant benefits of Dagster was its accessibility for data practitioners from non-technical backgrounds. Sean's success demonstrates that individuals without a formal software engineering background can effectively use code-based tools like Dagster with the right resources and dedication. This democratization of data engineering tools opens up new possibilities for lean teams and organizations with limited technical resources.
Dagster also provided cost-effective solutions for Erewhon. By opting for open-source tools and avoiding expensive third-party solutions, the team kept operational costs low while managing significant data volumes. Cost efficiency was particularly important for Erewhon, and this “startup data team” needed to deliver the value of its initiatives without incurring substantial additional costs.
"One underrated aspect of Dagster is the highly opinionated nature of the framework. I believe that as a new developer with fresh eyes, being exposed to state-of-the-art ideas and opinions on how to practice data engineering was invaluable. The recommended integrations make so much sense and simplify many things." - Sean Pool
Conclusion
Erewhon and Sean’s efforts show the potential of Dagster for lean data teams and data engineers from non-technical backgrounds. By adopting Dagster, Sean built a powerful and efficient data platform, driving significant business value and innovation. Sean’s journey demonstrates that individuals without a formal software engineering background can successfully leverage high-code, open-source tools to build sophisticated data solutions with the right resources and dedication.
The case study underscores the importance of these tools in democratizing data engineering and empowering lean teams to achieve their data goals. Dagster's modular design, integration capabilities, and cost-effectiveness make it an ideal solution for organizations looking to enhance their data infrastructure and drive data-driven decision-making. Sean’s success in building a data platform highlights the value of Dagster in enabling data-driven decisions, regardless of the team’s size or technical background.





.jpg)
.png)



.png)

