


What Is Data Ingestion?
Data ingestion involves importing, transferring, and loading data for further analysis and storage. It is the preliminary stage of handling vast amounts of data from diverse sources, enabling efficient data processing and analytics.
This process can either be automated or manual, depending on the scale and complexity of the dataset involved. Data ingestion ensures data is collected in a usable format for subsequent actions such as transformation and analysis.
Ingestion capabilities are important to collect structured, semi-structured, and unstructured data. By ensuring data arrives in a consistent, well-organized manner, organizations can eliminate bottlenecks associated with data processing.
This is part of a series of articles about data mesh.
Key Features of Modern Data Ingestion Tools
Scalability and Performance
A scalable tool adaptively handles increased data loads without performance degradation or latency issues. Performance includes both processing speed and the efficient use of computing resources. Planning for scalability ensures that future growth does not compromise performance, keeping systems responsive and capable of handling variable data loads.
Support for Diverse Data Sources and Formats
Data ingestion tools must accommodate various data sources and formats, ensuring data consolidation. Support for diverse data types, such as databases, CSV files, logs, and APIs ensures data gathering across platforms and applications. An inclusive tool reduces the need for bespoke conversion or pre-processing logic, supporting a pipeline from source to analysis-ready data.
Data Transformation Capabilities
Many ingestion tools provide built-in data transformation capabilities (or integrate with external transformation engines), allowing adaptations for analysis post-ingestion. Transformation typically involves data cleaning, filtering, enrichment, and reformatting to ensure compatibility with different analytical systems. While basic ingestion features collect data as-is, transformation capabilities prepare data in a suitable format, enhancing its utility.
Fault Tolerance and Reliability
Fault tolerance ensures continuous data flow despite potential setbacks like system failures or network disruptions, maintaining uninterrupted processes. A reliable data ingestion system provides mechanisms for automatic recovery, redundancy, and consistency checks. Consistent delivery and processing limit downtime and data loss, crucial for preserving system integrity.
Security and Compliance
Security in data ingestion includes encryption, access controls, and identity management to safeguard data movement from unauthorized access. Compliance involves ensuring data handling adheres to relevant regulations, such as GDPR or HIPAA, protecting sensitive information throughout ingestion processes. Secure data transmission improves trust, while compliance ensures adherence to legal and ethical standards.
10 Notable Data Ingestion Tools
Open-Source Tools
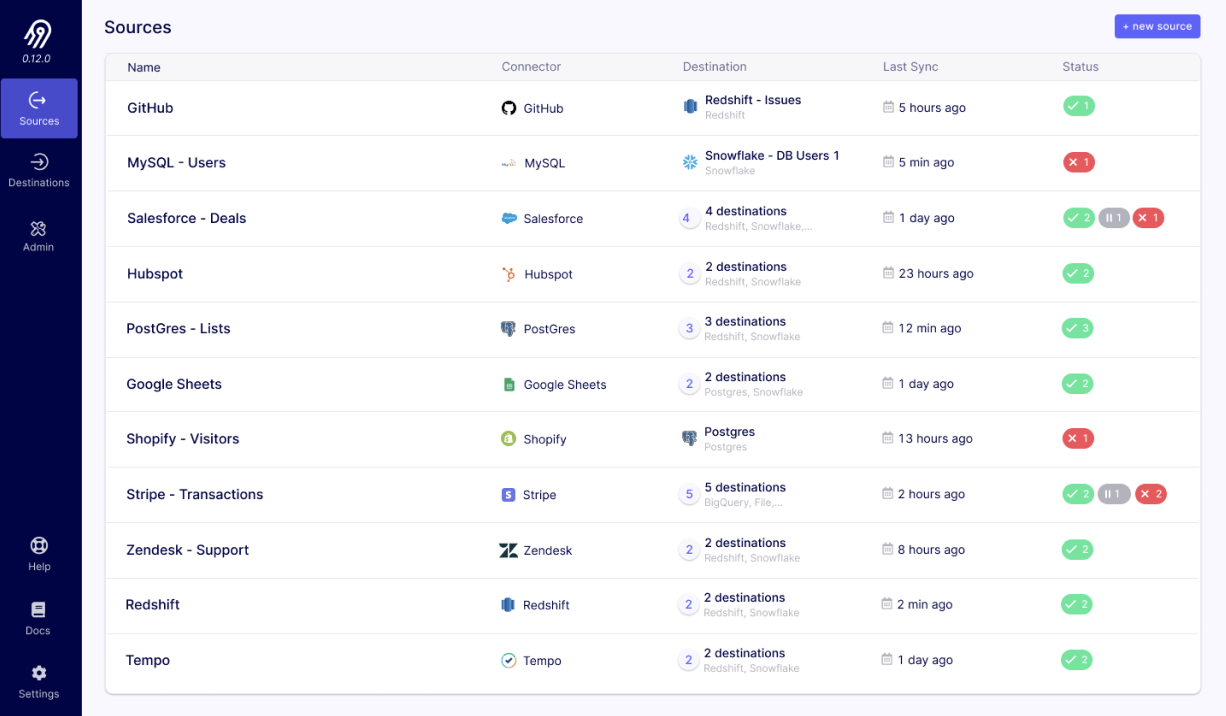
1. Airbyte

Airbyte is an open-source data platform that simplifies the movement of data across various systems, enabling organizations to collect and integrate data from multiple sources into their target destinations. It allows users to sync both structured and unstructured data across cloud environments while maintaining control over security and privacy.
License: MIT, ELv2
Repo: https://github.com/airbytehq/airbyte
GitHub stars: 16K+
Contributors: 1K+
Key features of Airbyte:
- Extensive data source integration: Supports over 500 data sources, including structured and unstructured data.
- Custom connectors: Provides a no-code or low-code environment for building custom connectors quickly.
- AI and machine learning integration: Simplifies AI workflows by enabling easy ingestion of unstructured data into vector databases like Pinecone and Weaviate.
- Flexible deployment options: Offers self-hosted, cloud, and hybrid deployment models to accommodate different infrastructure preferences and business requirements.
- Security and compliance: Ensures secure data handling with features like encryption, audit logs, and compliance with standards such as ISO 27001, SOC 2, GDPR, and HIPAA.
2. Apache Kafka

Apache Kafka is an open-source, distributed event streaming platform used for building high-performance data pipelines, real-time analytics, and mission-critical applications. It enables organizations to publish, subscribe, store, and process streams of events in a fault-tolerant and scalable manner.
License: Apache-2.0
Repo: https://github.com/apache/kafka
GitHub stars: 29K+
Contributors: 1K+
Key features of Apache Kafka:
- High throughput: Capable of delivering messages with network-limited throughput and latencies as low as 2ms.
- Scalability: Scales clusters to handle petabytes of data and trillions of messages, with elastic storage and processing capacity.
- Permanent storage: Provides durable and fault-tolerant storage for data streams across distributed clusters.
- High availability: Stretches across availability zones and geographical regions to ensure consistent performance and disaster recovery.
- Built-in stream processing: Supports stream processing features such as joins, aggregations, and exactly-once processing.
3. Apache NiFi

Apache NiFi is an open-source data ingestion platform that automates the flow of data between systems. It enables organizations to capture, transfer, and process large amounts of data from various sources in real time. NiFi addresses challenges like network failures, data inconsistencies, and evolving data formats.
License: Apache-2.0
Repo: https://github.com/apache/nifi
GitHub stars: 5K+
Contributors: 400+
Key features of Apache NiFi:
- Automated dataflow management: Automates the flow of data between systems, ensuring integration across diverse platforms.
- Scalability and performance: Supports high throughput and can scale to handle large volumes of data, managing spikes without impacting performance.
- Flexible data routing and transformation: Offers data routing, transformation, and mediation between systems with minimal configuration effort.
- Real-time monitoring and control: Provides real-time monitoring of dataflows with the ability to track and modify data movement visually via an intuitive interface.
- Back pressure and error handling: Includes built-in back pressure mechanisms and error handling to maintain data flow even under system strain.

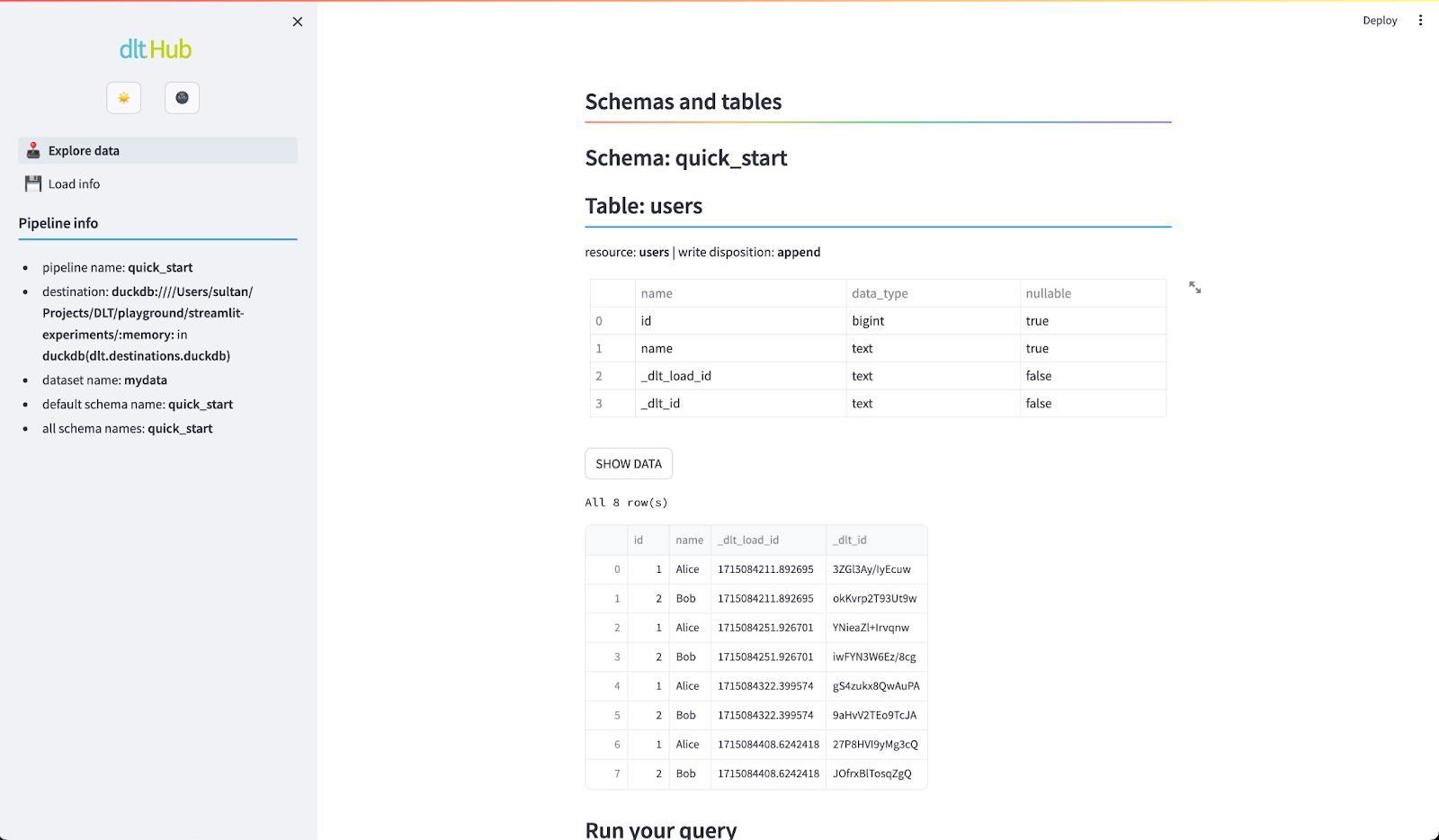
4. dlt

dlt (Data Loading Tool) is an open-source data framework to simplify the creation and management of modern data pipelines. It emphasizes collaboration and accessibility, allowing data teams to build efficient, reusable pipelines with minimal effort. Dlt is tailored for dynamic workflows and excels in adapting to schema changes or evolving data formats.
License: Apache-2.0
Repo: https://github.com/dlt-hub/dlt
GitHub stars: 2K+
Contributors: 80+
Key features of dlt:
- Declarative pipelines: Simplifies pipeline creation using a configuration-driven approach that eliminates the need for complex scripting.
- Change data capture (CDC): Supports incremental data updates for database connectors, ensuring efficient processing without full data reloads.
- Lightweight and portable: dlt is a regular Python library and be used anywhere Python runs, without the need for complex infrastructure, containers, or backends.
- Version control and collaboration: Seamlessly integrates with Git for version control, enabling collaborative development.
- Customizable: Pre-built connectors are open-source and customizable. It’s also possible to create custom connectors using the Python API.
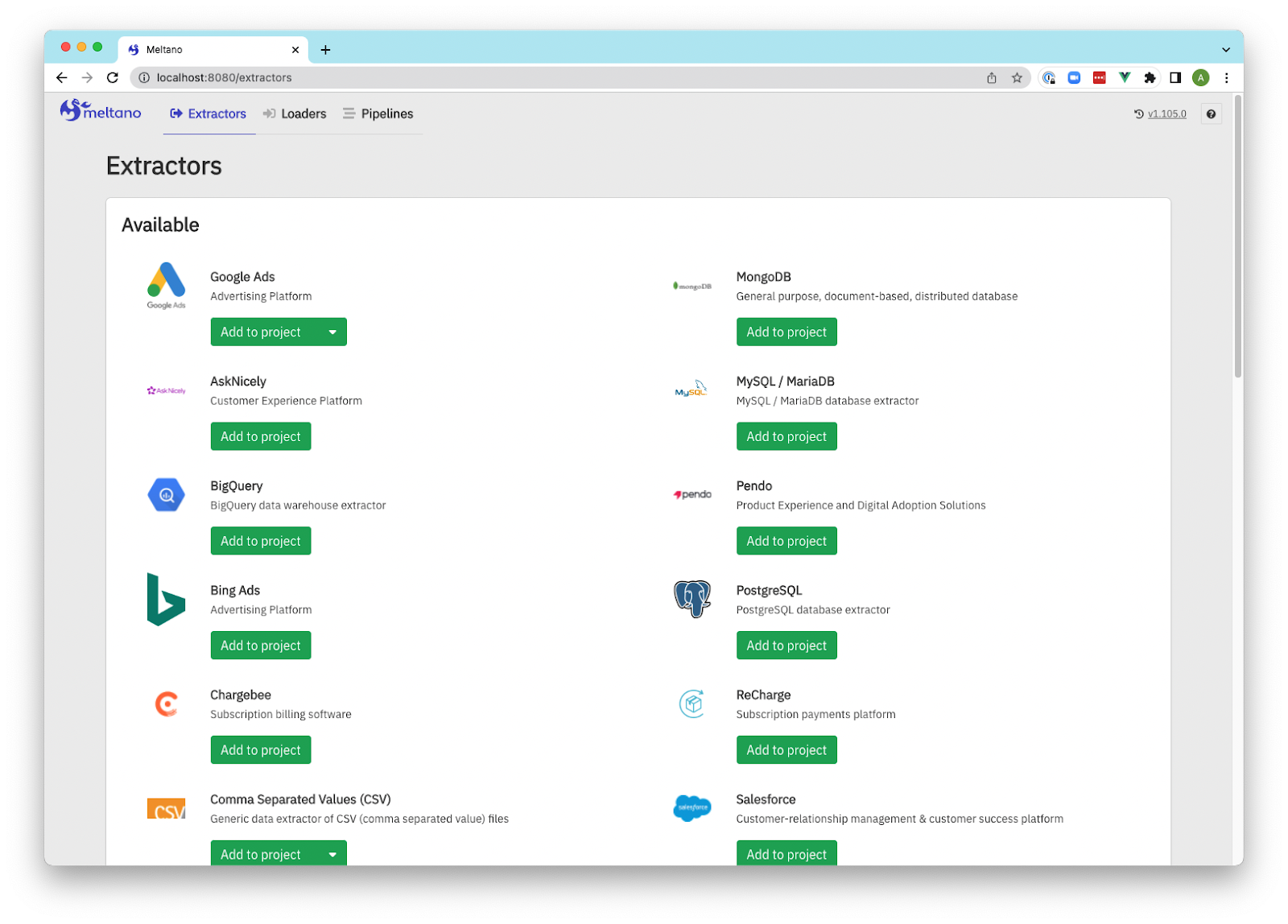
5. Meltano

Meltano is an open-source data integration platform built to empower data teams with flexible and customizable tools. It supports the entire data lifecycle, from extraction to analysis, enabling teams to manage their workflows in a streamlined and modular way.
License: MIT
Repo: https://github.com/meltano/meltano
GitHub stars: 1K+
Contributors: 100+
Key features of Meltano:
- Modular architecture: Allows users to mix and match components for data extraction, loading, and transformation, tailored to their specific needs.
- ELT workflow automation: Simplifies the ELT process with pre-built connectors and transformation tools compatible with dbt and other frameworks.
- Pipeline orchestration: Provides built-in orchestration capabilities to schedule, monitor, and manage pipelines effectively.
- DataOps friendly: Supports iterative development, testing, and deployment, enhancing collaboration and operational efficiency.
- Open-source and extensible: Community-driven with the ability to extend functionality through plugins and custom components.
Commercial Tools
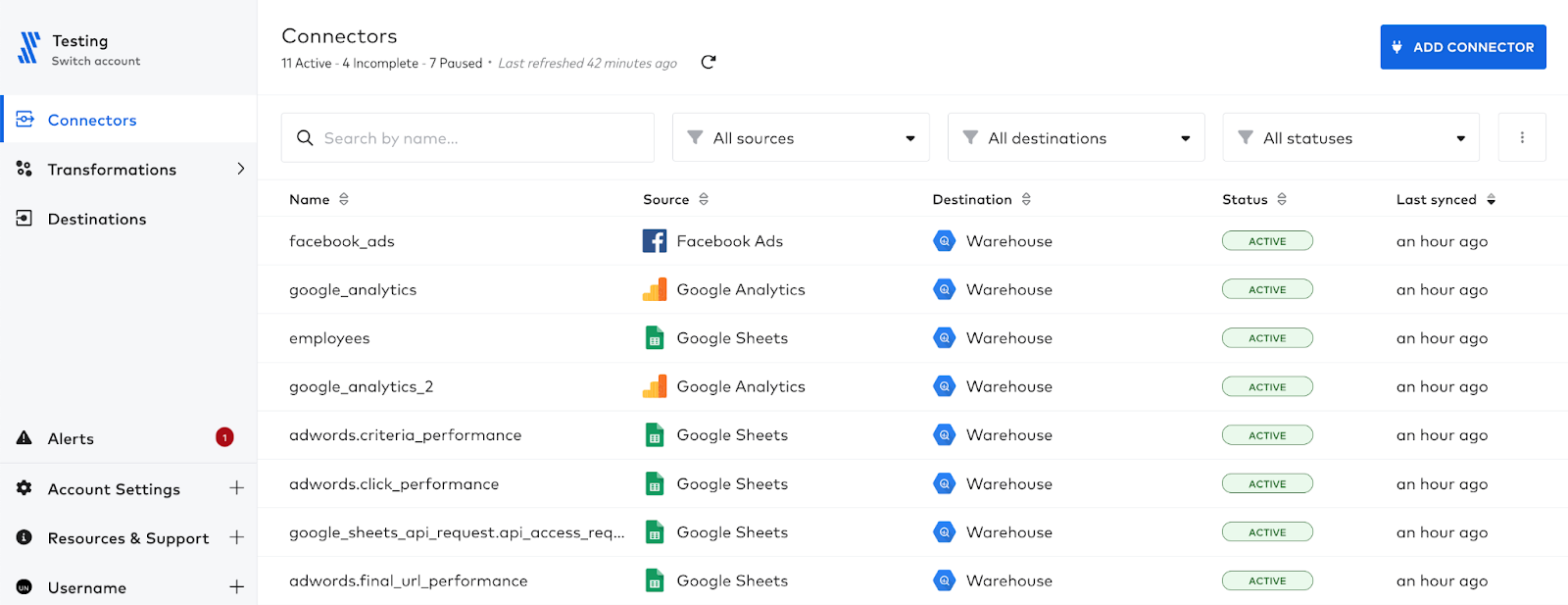
6. Fivetran

Fivetran is an automated platform that enables data replication from over 500 sources. It handles all aspects of data extraction and loading, ensuring that data pipelines remain reliable and low maintenance.
License: Commercial
Key features of Fivetran:
- Automated data replication: Automatically extracts and loads data from over 500 managed connectors, ensuring consistent data availability.
- Low-impact, high-volume replication: Minimizes the performance impact on source systems while handling large volumes of data with low latency.
- Incremental updates and historical loads: After an initial full load, switches to incremental updates, ensuring that only new and updated data is synced to destinations.
- Schema automation and drift handling: Automatically creates and updates schemas, handling schema changes to ensure data is always organized and ready for analysis.
- Custom connectors: Supports custom connectors for sources not covered by pre-built connectors, enabling data ingestion from virtually any source.
7. Stitch

Stitch is a cloud-first ETL platform to move data from a variety of sources to chosen destinations. With support for databases like MySQL and MongoDB, as well as SaaS applications like Salesforce and Zendesk, Stitch automates the process of extracting and replicating data, helping centralize data for analysis without the need for extensive engineering.
License: Commercial, client licensed as open source
Key features of Stitch:
- Data replication: Replicates data from databases and SaaS applications to cloud data warehouses, ensuring data is available for analysis.
- Wide range of supported sources: Connects to hundreds of data sources, including popular databases like MySQL and MongoDB, and SaaS tools like Salesforce and Zendesk.
- Cloud-first architecture: Designed for cloud environments, ensuring fast data movement with minimal infrastructure overhead.
- Automated ETL process: Automates the extraction and loading of data, reducing manual work and enabling faster access to centralized data for analytics.
- Schema management: Handles schema changes automatically, ensuring that data structures in the destination are always aligned with the source systems.
8. Amazon Kinesis

Amazon Kinesis is a fully managed, scalable platform for ingesting, processing, and analyzing real-time streaming data. With Kinesis Data Streams, organizations can capture large amounts of data from multiple sources such as website clickstreams, financial transactions, social media feeds, and IT logs.
License: Commercial
Key features of Amazon Kinesis:
- Massively scalable data ingestion: Handles gigabytes of data per second from hundreds of thousands of data sources, making it suitable for high-throughput use cases like clickstreams and transaction logs.
- Real-time data availability: Ensures data is available to analytics applications and services like AWS Lambda or Amazon Managed Service for Apache Flink within 70 milliseconds.
- Serverless architecture: Operates in a serverless mode, removing the need for server management. On-demand mode automatically scales to handle workload fluctuations.
- High availability and durability: Synchronously replicates data across three AWS Availability Zones, ensuring data durability and protection against loss. Data can be stored for up to 365 days.
- Dedicated consumer throughput: Supports up to 20 consumers per data stream, each with its own dedicated read throughput, allowing multiple applications to simultaneously process the same stream.
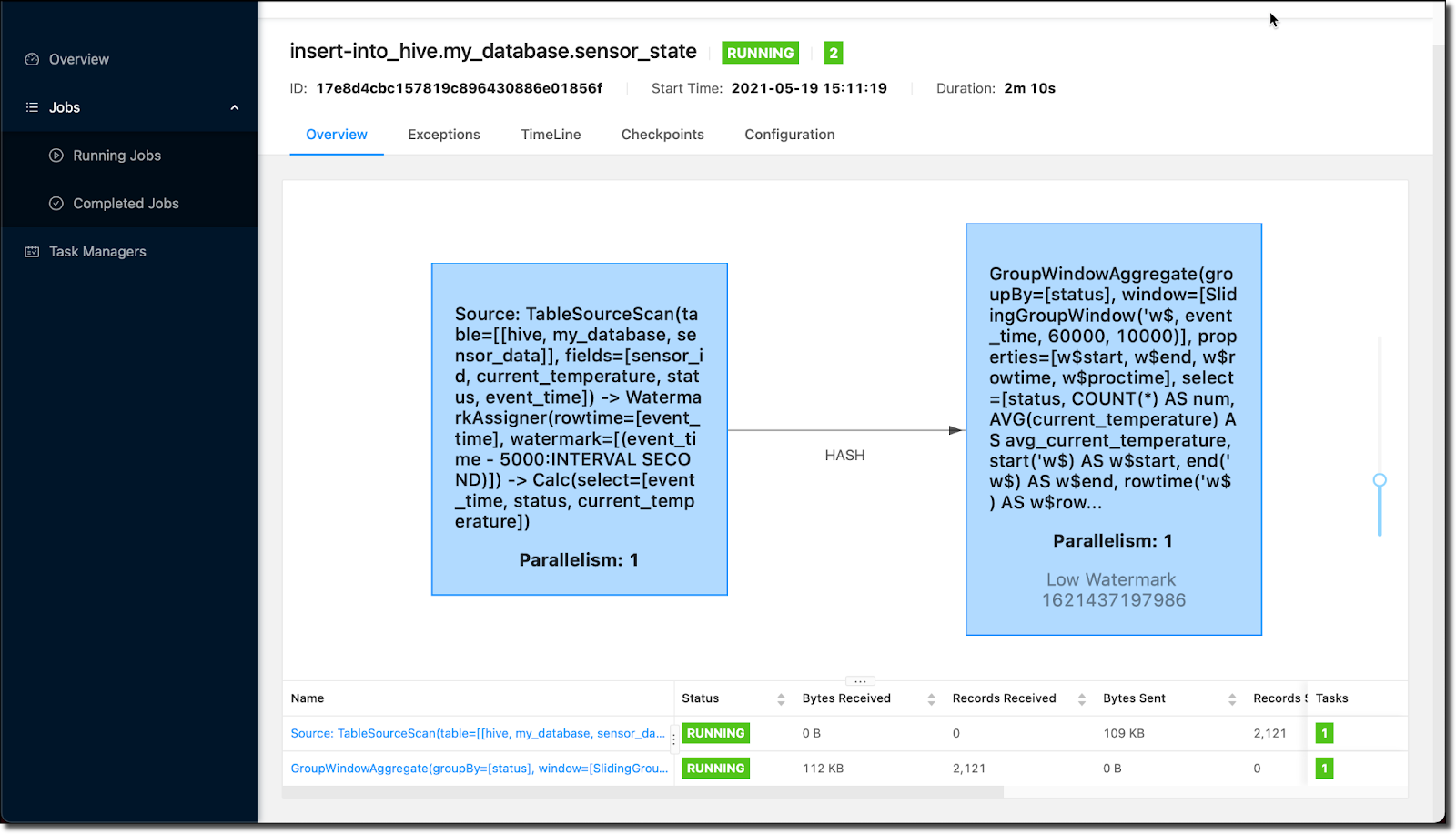
9. Google Cloud Dataflow

Google Cloud Dataflow is a fully managed, scalable platform for real-time data ingestion, processing, and analytics. It allows teams to build streaming and batch data pipelines that process data as it's generated, supporting real-time AI/ML use cases, ETL (extract, transform, load) workflows, and advanced data integration.
License: Commercial
Key features of Google Cloud Dataflow:
- Real-time data ingestion and processing: Supports the parallel ingestion and transformation of data from multiple sources, including Pub/Sub, Kafka, and databases.
- Streaming AI and ML integration: Supports AI/ML models with up-to-date data for more accurate predictions. Pre-built templates and MLTransform tools simplify building streaming pipelines for use cases like fraud detection and threat prevention.
- Scalable and serverless architecture: Automatically scales resources based on workload demands.
- Low latency data processing: Processes and delivers streaming data with minimal latency, making it suitable for real-time anomaly detection, dynamic pricing, and operational monitoring.
- Pre-built templates for fast deployment: Offers pre-designed templates for common streaming and batch processing tasks, enabling users to deploy ETL pipelines or integrate data into BigQuery, GCS, and Spanner with minimal setup.
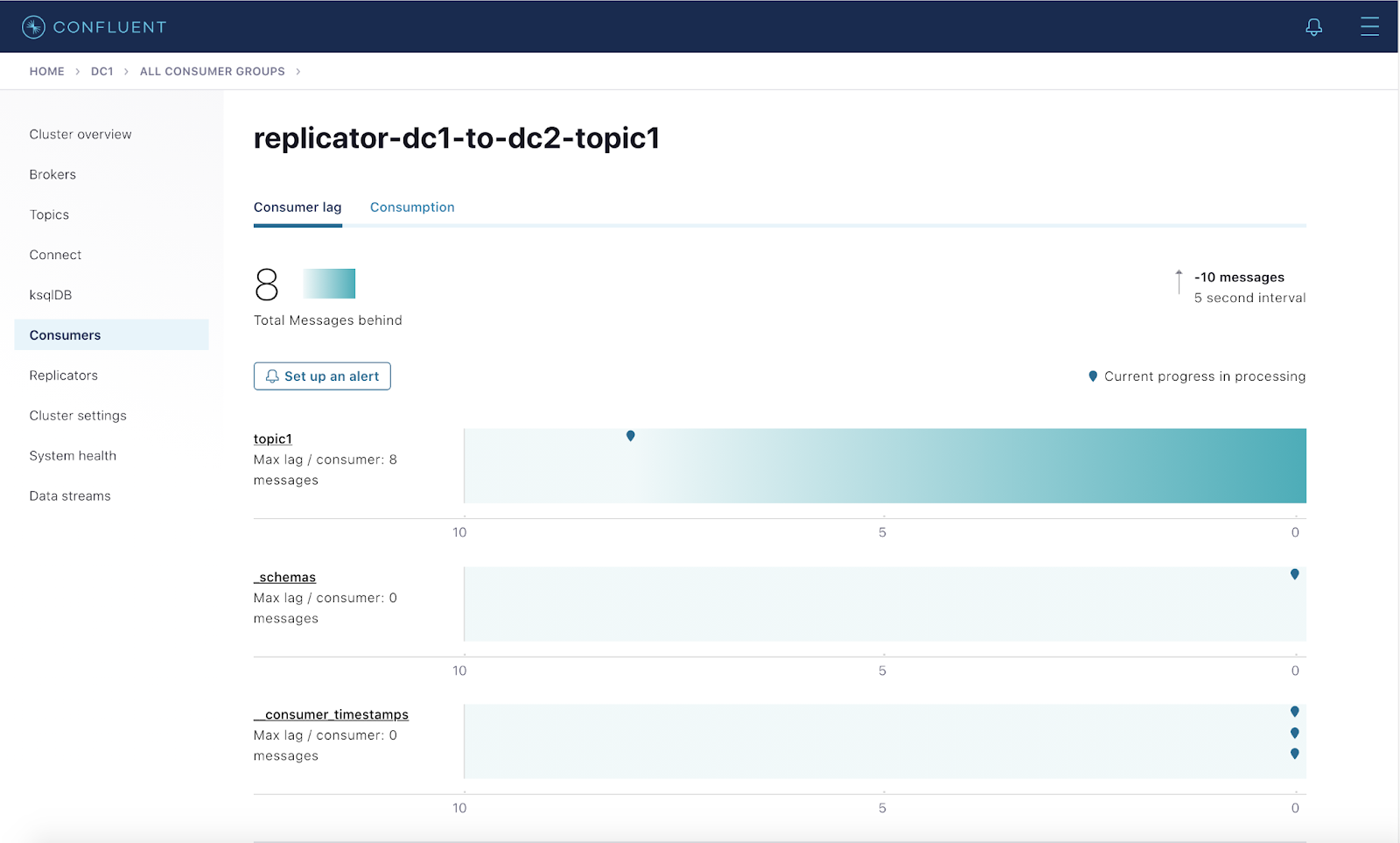
10. Confluent Platform

Confluent Platform is an event streaming platform built on Apache Kafka. It provides tools and integrations to simplify building, deploying, and managing real-time data pipelines and event-driven applications. It enables organizations to move and process data across cloud and on-premises environments.
License: Commercial
Key features of Confluent Platform:
- Kafka-based foundation: Built on Apache Kafka, it provides high-throughput, low-latency data streaming.
- Schema management: Includes Confluent Schema Registry to enforce and evolve data schemas across applications.
- Enterprise security: Offers encryption, role-based access control, and audit logging to meet security and compliance requirements.
- Stream processing: Integrates with ksqlDB for real-time data processing using SQL-like queries.
- Multi-cloud and hybrid support: Enables deployment across cloud providers and on-premises environments.
- Monitoring and management: Includes Control Center for real-time monitoring and management of Kafka clusters.
- Connectors: Provides an array of pre-built connectors for databases, cloud services, and other systems.
The Role of Data Orchestration in Data Ingestion
Data orchestration is essential in coordinating and managing the flow of data throughout the ingestion process. While data ingestion focuses on collecting and transferring data from various sources into a centralized system, orchestration handles the overall pipeline to ensure that these tasks occur in the correct order, on schedule, and with minimal disruptions.
It ensures that data from multiple sources is efficiently processed, cleaned, and delivered to downstream systems such as data lakes, warehouses, or analytics platforms. Data orchestration involves automating the sequencing of tasks involved in ingestion, such as extraction, transformation, and loading. This automation reduces manual intervention, making it easier to manage large and complex data pipelines.
Additionally, orchestration tools monitor the data pipeline for errors, providing automatic retries or error notifications if a task fails, ensuring the entire ingestion process remains resilient and consistent. Orchestration tools also assist with resource management. They ensure optimal utilization of resources by allocating computing power, storage, and bandwidth according to the needs of ingestion tasks.
Orchestrating Data Ingestion with Dagster
As a data-centric data orchestrator, Dagster allows data teams to execute their ingestion pipelines as a cohesive part of their wider data platform, enabling tighter integration between data ingestion and downstream products that depend on this data.
With a built-in toolkit for data ingestion thanks to our Embedded ELT feature and integrations with leading providers like Fivetran and Airbyte, Dagster allows you to orchestrate your ETL workloads on your platform of choice.
Other features like Dagster Pipes and Asset Checks also help streamline some of the most challenging aspects of running data ingestion at scale, like setting up parallel processing on remote, distributed infrastructure and enforcing data quality checks at the point of ingestion.
To learn more about building data ingestion workloads with Dagster, see this rundown of ELT Options in Dagster.






.jpg)
.png)



.png)

