


What Are Data Engineering Tools?
Data engineering tools are software applications and platforms that assist in building, managing, and optimizing data pipelines. These tools cover various stages of the data lifecycle, including data ingestion, processing, transformation, storage, orchestration, and monitoring. They ensure that data flows seamlessly through an organization, from raw input to refined outputs ready for analysis, reporting, or machine learning applications.
Different types of data engineering tools work together to address the complexity of managing large-scale data environments. For example, ingestion tools collect data, processing tools clean and transform it, and orchestration tools automate the workflow. By integrating tools for storage, governance, and monitoring, organizations can maintain efficient, secure, and scalable data pipelines that serve multiple business needs.
Types of Data Engineering Tools
Ingestion Tools
Ingestion tools are responsible for collecting data from various sources, such as databases, APIs, or streaming platforms, and bringing it into a centralized system. They handle both batch and real-time data ingestion, ensuring that data flows smoothly into data lakes, warehouses, or processing systems.
These tools are useful for ensuring that raw data from different sources is collected efficiently and made available for further processing and analysis. They also handle the challenges of managing multiple data formats and ensuring that data is ingested in a reliable and scalable manner.
Processing Tools
Processing tools are used to manipulate raw data to prepare it for analysis or storage. These tools execute operations like filtering, sorting, and aggregating data, often across distributed systems. They enable large-scale data processing in both batch and real-time environments, allowing organizations to handle vast amounts of data efficiently.
Processing tools help convert raw or semi-structured data into more refined forms, making it easier to derive insights, apply machine learning models, or conduct detailed reporting.
Transformation Tools
Transformation tools convert raw data into a structured and standardized format. This process often involves data cleaning, normalization, deduplication, and other quality improvements to ensure that data is consistent and usable.
Transformation tools ensure that data meets specific format requirements for downstream applications, such as analytics or reporting platforms. By automating and standardizing transformations, these tools help maintain data accuracy and reliability across systems.
Orchestration Tools
Orchestration tools manage the execution and coordination of data workflows, ensuring that different tasks—such as data ingestion, processing, and transformation—are performed in the correct order. These tools automate the scheduling, monitoring, and optimization of complex data pipelines, handling dependencies between tasks.
Orchestration tools ensure that workflows run smoothly and efficiently, even as data pipelines scale in size and complexity. They also provide error handling and recovery mechanisms, making data pipelines more resilient to failures.
Storage and Integration Tools
Storage and integration tools provide the infrastructure for storing large volumes of data and ensuring that data is accessible across different systems. Storage tools are designed to hold raw, processed, and structured data securely and efficiently, while integration tools ensure that data can flow between systems and applications.
Together, they form the backbone of data infrastructure, enabling organizations to store, access, and share data. These tools ensure that data is always available for analysis and operational use, supporting business continuity and scalability.
Governance and Security Tools
Governance and security tools ensure that data is managed, accessed, and protected according to organizational policies and regulatory requirements. Governance tools provide oversight of data quality, data lineage, and metadata management, allowing organizations to maintain control over their data assets.
Security tools protect data from unauthorized access and breaches through encryption, access control, and monitoring. Together, governance and security tools help ensure compliance with data privacy laws and internal standards, while also protecting sensitive information.
Monitoring and Logging Tools
Monitoring and logging tools track the health and performance of data pipelines and infrastructure in real-time. Monitoring tools provide visibility into key metrics, such as system performance and data flow rates, while logging tools capture detailed records of system activities.
These tools help identify issues early, allowing engineers to troubleshoot problems and optimize pipeline efficiency. Monitoring and logging are critical for maintaining the stability and reliability of data systems, ensuring that operations run smoothly.
Data Visualization and Presentation
Data visualization and presentation tools allow users to create charts, graphs, dashboards, and reports that illustrate trends, patterns, and correlations within data. By providing visual representations, they make complex datasets more accessible and easier to understand, enabling quicker decision-making.
Data visualization tools help users explore and interact with data in real time. Many tools offer drag-and-drop interfaces, allowing non-technical users to create visualizations without the need for extensive coding. These tools also support various data sources, enabling the integration of data from databases, spreadsheets, and cloud storage.
Notable Data Engineering Tools
1. Dagster

Category: Ingestion, processing, transformation, and orchestration tools
Primary function: Data orchestration, data quality, monitoring, and logging
License: Apache-2.0
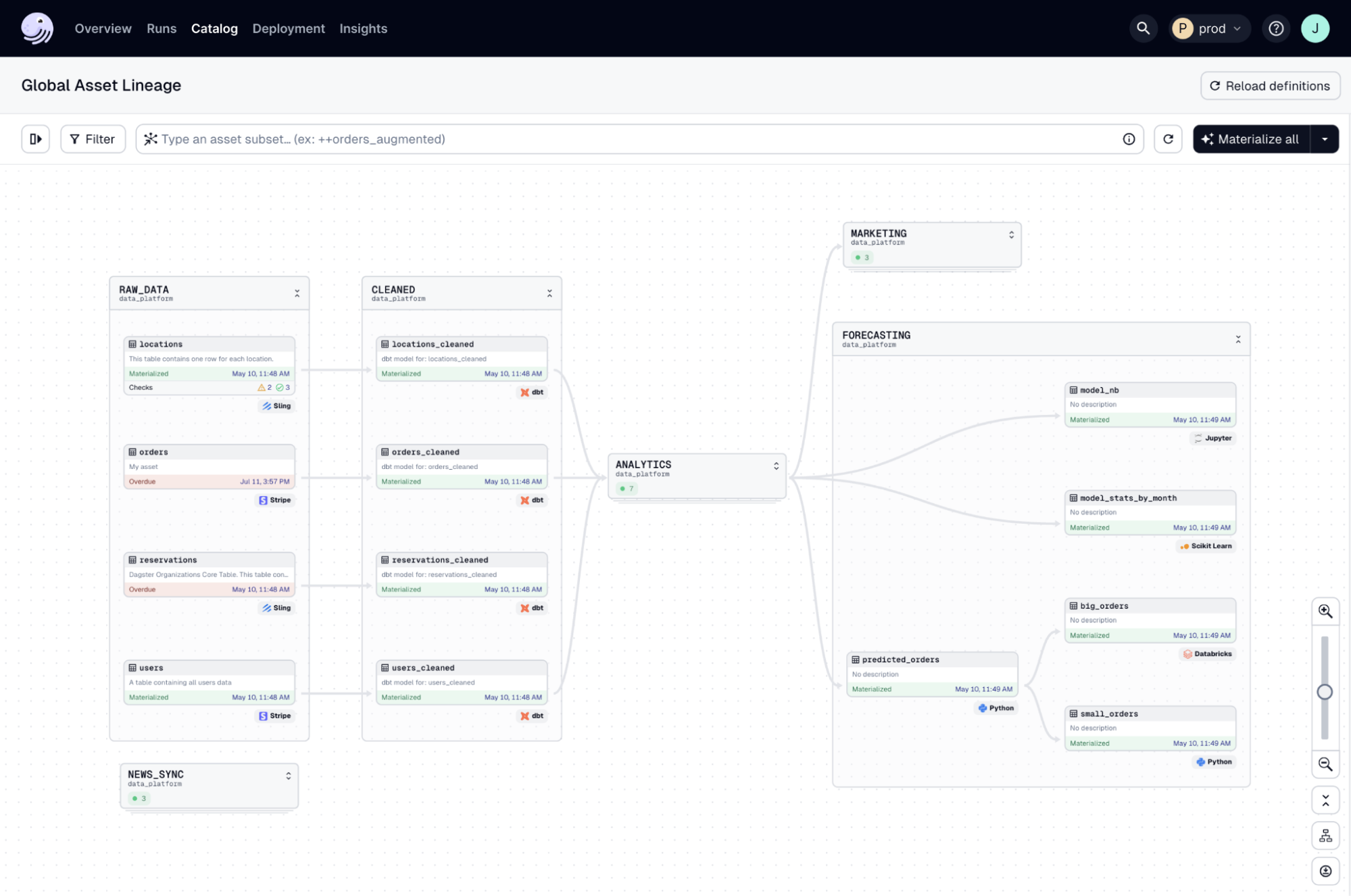
Dagster is an open-source data orchestration platform for the development, production, and observation of data assets across their development lifecycle. It features a declarative programming model, integrated lineage and observability, data validation checks, and best-in-class testability.
Key features of Dagster:
- Data asset-centric: Focuses on representing data pipelines in terms of the data assets that they generate, yielding an intuitive, declarative mechanism for building data pipelines.
- Observability and monitoring: Aims to be the “single pane of glass” for your data team, with a robust logging system, built-in data catalog, asset lineage, and quality checks.
- Cloud-native and cloud-ready: Provides a managed offering with robust, managed infrastructure, elegant CI/CD capability, and support for custom infrastructure.
- Integrations: Extensive library of integrations with the most popular data tools, including the leading cloud providers (AWS, GCP, Azure), ETL tools (Fivetran, Airbyte, dlt, Sling), and BI tools (Tableau, Power BI, Looker, and Sigma).
- Flexible: Supports any Python workflow and lets you execute arbitrary code in other programming languages and on external environments using Dagster Pipes.
- Declarative Automation: Lets you go beyond cron-based scheduling and intelligently orchestrate your pipelines using event-driven conditions that consider the overall state of your pipeline and upstream data assets.
2. dbt (Data Build Tool)

Category: Transformation tools
Main function: Data transformation, data quality, and enrichment
License: Apache 2.0
dbt (Data Build Tool) is a SQL-first platform for transforming and orchestrating data pipelines using software engineering best practices. It allows teams to collaboratively develop, test, and deploy data transformations while ensuring data quality and governance. It automates dependency management and supports CI/CD workflows, making it possible to build reliable, modular data pipelines.
Key Features of dbt:
- SQL-first data transformations: Allows users to write transformations in SQL or Python, with dbt managing dependencies and executing models in the correct order.
- Automated testing and documentation: Automatically tests data models before production and generates documentation for better data transparency and collaboration.
- CI/CD and version control: Supports Git-enabled version control and CI/CD pipelines to deploy data models safely across development, staging, and production environments.
- Modular, reusable code: Offers macros and templates to create modular data transformations that are reusable and adaptable to different datasets.
- Cross-team collaboration: Enables collaboration between data science and analytics teams by supporting both SQL and Python, enabling a unified workspace for data modeling.

3. Snowflake

Category: Processing, transformation, storage and integration tools
Main function: Data storage and integration, data governance and security
License: Commercial
Snowflake is a platform for simplifying data engineering tasks, enabling streaming and batch data pipelines on a single system. Its platform is optimized for performance and cost-efficiency, allowing users to process data using declarative pipelines in SQL or Python without needing to manage separate infrastructure.
Key Features of Snowflake:
- Unified streaming and batch pipelines: Handles both streaming and batch data ingestion, offering sub-10-second latency with Snowpipe Streaming.
- Dynamic tables: Automatically manage dependencies and materialize results based on freshness targets for more efficient processing.
- Multi-language support: Supports Python, SQL, Java, and more, enabling code execution in a single optimized engine.
- Data sharing: Direct access to live data via Snowflake Marketplace without the need for additional pipelines.
- Built-in DevOps features: Integrates with CI/CD pipelines and version control systems, simplifying deployment and management of resources programmatically.

4. BigQuery

Category: Processing, transformation, storage and integration tools
Main function: Data storage, ingestion, batch and real-time processing
License: Commercial
BigQuery is a fully managed, serverless data warehouse for efficient data analysis and transformation. With its scalable, distributed architecture, BigQuery allows data engineers to process both structured and unstructured data at high speed, using SQL and Python for querying and transformation.
Key Features of BigQuery:
- Serverless data warehouse: Automatically scales resources for querying terabytes of data in seconds and petabytes in minutes, without requiring manual provisioning.
- Separation of compute and storage: Enables independent scaling of storage and compute resources, improving performance and reliability while handling large-scale data workloads.
- Support for streaming and batch data: Continuously ingests data with real-time streaming, or batch-load data from sources like cloud storage, databases, or files.
- Advanced analytics and machine learning: Offers built-in machine learning with BigQuery ML, geospatial analytics, and support for ANSI SQL.
- Integration: Integrates with popular tools such as Looker Studio and Tableau, along with external data sources like Google Sheets, Bigtable, and Cloud Storage through federated queries.
5. Apache Airflow

Category: Orchestration tools
Main function: Data orchestration and workflow scheduling
License: Apache 2.0
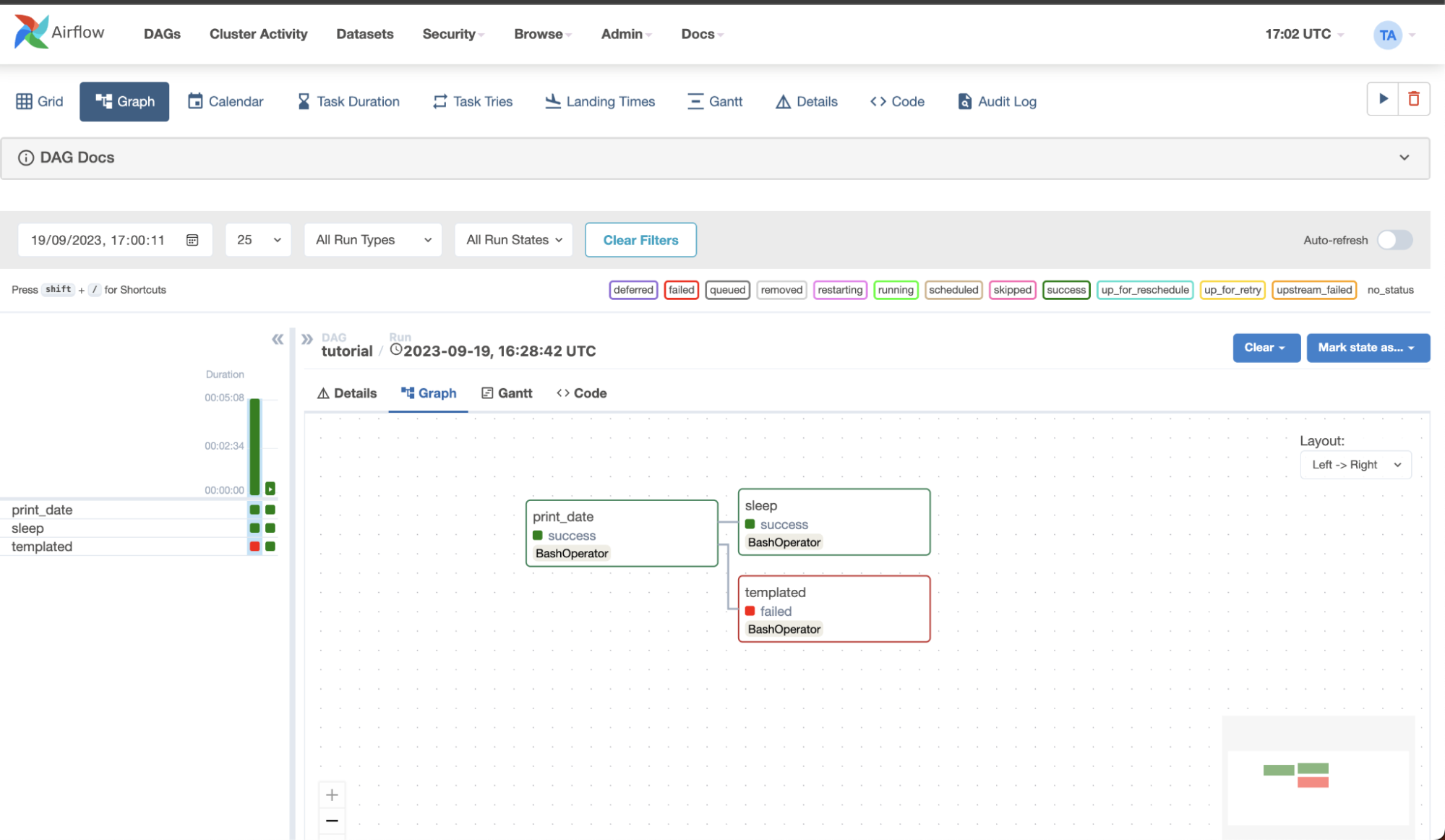
Apache Airflow is an open-source platform for orchestrating complex data workflows. By allowing data engineers to author, schedule, and monitor workflows programmatically, Airflow simplifies the management of data pipelines in modern data environments.
Key Features of Apache Airflow:
- Python-based workflow creation: Define workflows using Python, taking advantage of standard features like loops and datetime formats to dynamically generate tasks.
- Scalable architecture: Leverage Airflow’s modular design and message queue system to scale workflows from a few tasks to a large number of workers.
- Dynamic pipeline generation: Airflow allows dynamic creation of pipelines, providing flexibility to adapt to changing data environments.
- Web interface: Monitor and manage workflows through a modern web UI that provides real-time insights into task statuses, logs, and scheduling.
- Integrations: Airflow includes pre-built operators for integration with major cloud platforms like Google Cloud, AWS, and Azure, as well as other third-party tools.
6. Apache Spark

Category: Processing tools
Main function: Batch and real time data processing, data transformation
License: Apache 2.0
Apache Spark is an open-source, unified engine for large-scale data analytics. It supports batch and streaming data processing, SQL analytics, data science, and machine learning on single-node machines and distributed clusters.
Key Features of Apache Spark:
- Unified batch and streaming processing: Handles batch and real-time data streams using a single engine.
- SQL analytics: Can execute fast, distributed ANSI SQL queries for large datasets, delivering performance often faster than traditional data warehouses.
- Scalable data science: Performs exploratory data analysis (EDA) and machine learning on petabyte-scale datasets without needing to downsample.
- Machine learning support: Trains machine learning models on small datasets, then scales them to clusters of thousands of machines for production use.
- Multi-language support: Allows users to develop data processing tasks in Python, SQL, Scala, Java, or R.

7. Apache Kafka
Category: Processing tools
Main function: Real-time data processing and data ingestion
License: Apache 2.0
Apache Kafka is a distributed event streaming platform for building real-time data pipelines and applications. Used by many large organizations, Kafka enables data engineers to handle massive volumes of data with high throughput, fault tolerance, and low-latency performance.
Key Features of Apache Kafka:
- High throughput and low latency: Delivers messages with network-limited throughput, achieving latencies as low as 2ms in large, distributed environments.
- Scalability: Scales clusters to thousands of brokers and process trillions of messages per day, while elastically expanding storage and processing to meet growing data demands.
- Durable storage: Kafka’s distributed, fault-tolerant architecture ensures permanent, reliable storage of data streams across clusters.
- Built-in stream processing: Performs real-time data transformations, joins, aggregations, and filtering with exactly-once processing to ensure accurate, event-time analytics.
- Integration: Connects to hundreds of external systems like databases, cloud storage, and more through its Connect API.
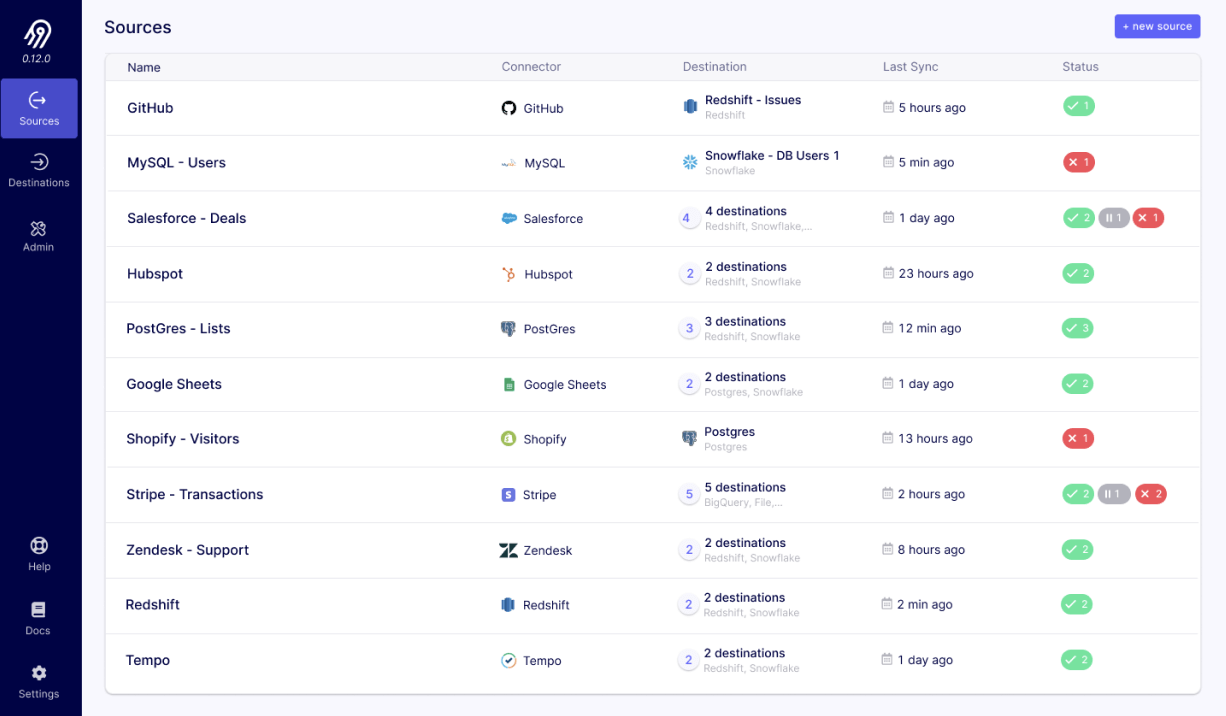
8. Airbyte

Category: Ingestion tools
Main function: Data ingestion and support for multiple data sources
License: MIT
Airbyte is an open source ELT platform for simplifying and scaling data integration for data engineers. It provides an extensive collection of connectors that support data extraction from various sources, enabling organizations to move and load data into warehouses, lakes, and databases.
Key Features of Airbyte:
- Extensive data extraction: Extracts data from over 500 API, database, and file sources, including large datasets from CDC databases and multiple systems simultaneously.
- Incremental data loading: Loads data into over 50 destinations, including warehouses, lakes, and databases, with support for incremental loading to keep data up-to-date.
- Connector builder: Users can build custom connectors using a no-code or low-code approach, enabling self-serve data movement for any HTTP API without the need for local development environments.
- Unified ELT platform: Helps manage schema changes, with users setting sync frequencies between 5 minutes to 24 hours, and handles upstream breaking changes.
- Tool integration: Integrates with Dagster, dbt, and Airflow for data orchestration.
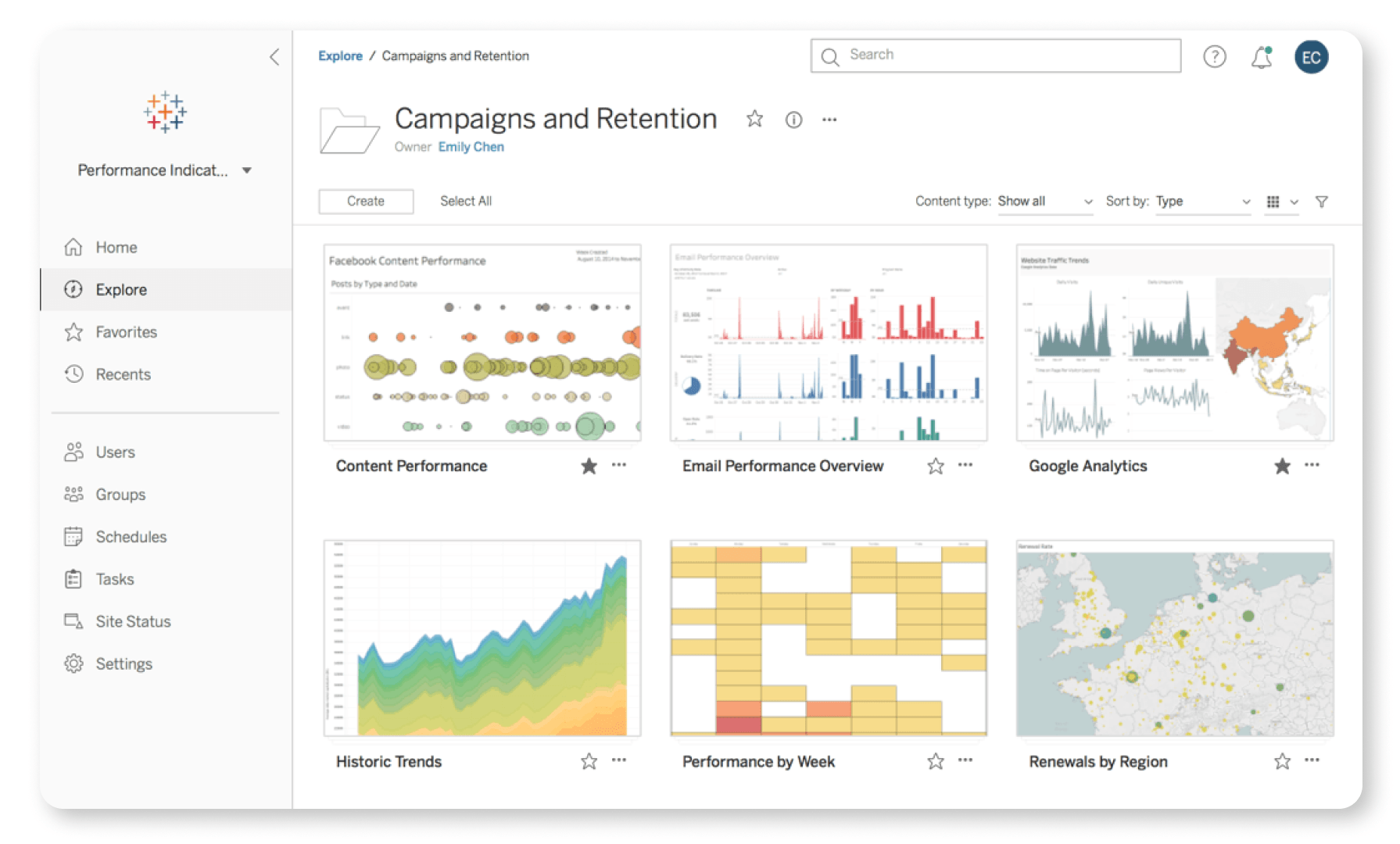
9. Tableau

Category: Data visualization and presentation
Main function: Data presentation and visualization
License: Commercial
Tableau is a self-service analytics platform that enables data engineers to transform raw data into actionable insights. With an AI-powered interface, Tableau simplifies data visualization and analytics, offering drag-and-drop functionality and integration with AI technologies like Salesforce Einstein.
Key Features of Tableau:
- Intuitive data exploration: Its drag-and-drop interface can be used with built-in AI from Salesforce Einstein to quickly explore and analyze data, enriched with business context for deeper insights.
- Automated data narratives: Users can add automated, easy-to-understand narratives to dashboards, making data analysis faster and more accessible for business users.
- Data governance and security: Helps ensure secure, trusted data across environments with integration for single sign-on (SSO), compliance monitoring, and industry-standard certifications like SOCII and ISO.
- Scalable architecture: Scales data infrastructure without manual server configurations or hardware management.
- Collaboration and sharing: Supports teamwork with features that allow users to discover, share, and collaborate on data across devices, from desktops to mobile.
10. Apache Hadoop

Category: Processing, transformation, storage and integration tools
Main function: Batch data processing and data storage
License: Apache 2.0
Apache Hadoop is an open-source framework for processing and storing large amounts of data across distributed computing clusters. It enables data engineers to handle large-scale data processing by breaking tasks into smaller workloads that can be executed in parallel.
Key Features of Apache Hadoop:
- Distributed data storage (HDFS): Stores data across multiple nodes in a cluster, ensuring fault tolerance by replicating data across nodes, protecting against hardware or software failures.
- Parallel data processing (MapReduce): Supports high-performance processing by splitting large datasets into smaller tasks that are processed in parallel, reducing computation time.
- Scalability: Scales from a few nodes to thousands, enabling the processing of petabytes of data on commodity hardware.
- Flexibility in data formats: Can handle structured, semi-structured, and unstructured data, providing versatility in how data is stored and processed.
- Ecosystem integration: Works with other big data tools such as Apache HBase, Hive, and Spark to extend its functionality for analytics and real-time data processing.

Dagster: The Single Pane of Glass for Your Data Platform
Dagster is the unified control plane for your data platform. It not only orchestrates your data processes but also gives you the right abstractions to effectively manage and centralize complex data processes managed by diverse data teams and running on heterogeneous compute, tooling, and infrastructure.
It features a best-in-class developer experience, a modular architecture with first-class multi-tenancy, and built-in support for complex event-driven triggers, data quality checks, and a rich data catalog.
Most importantly, it doesn’t try to supplant your existing tooling; instead, it helps you manage the fragmented data ecosystem by providing native integrations with the most popular data tooling and cloud platforms, allowing data teams to run any tool on any infrastructure at scale, while serving as the single pane of glass to orchestrate and monitor these processes.






.jpg)
.png)



.png)

