


How Does AWS Support Data Pipelines?
AWS provides an ecosystem of services to support data pipelines at every stage—from data ingestion and transformation to storage, analysis, and monitoring. These services cater to different data processing needs, including batch processing, streaming, workflow orchestration, and security.
For batch workloads, AWS services like AWS Batch and AWS Glue enable efficient ETL (extract, transform, load) operations, allowing organizations to process large datasets at scale. For real-time data processing, services such as AWS Glue Streaming, AWS Lambda, and Amazon Kinesis provide low-latency processing capabilities.
Data storage and warehousing solutions like Amazon S3 and Amazon Redshift ensure that processed data is stored efficiently and is readily accessible for analytics. Workflow orchestration tools like AWS Step Functions and Managed Workflows for Apache Airflow (MWAA) help coordinate complex data processing tasks, ensuring reliability and automation.
AWS also offers monitoring and security tools commonly used with data pipelines, including Amazon CloudWatch for performance tracking and AWS CloudTrail for auditing and compliance.
AWS Services for Building Data Pipelines
Batch Data Processing
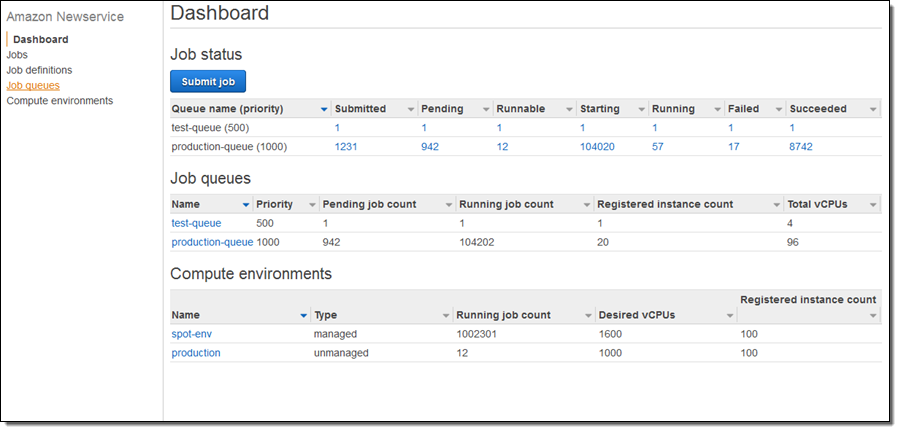
1. AWS Batch
AWS Batch is a managed service that enables efficient execution of batch computing workloads without provisioning or managing servers. It dynamically provisions compute resources based on job requirements, optimizing cost and performance. Batch processing pipelines often handle large-scale data transformations, such as aggregating logs, running machine learning training jobs, or processing financial transactions in bulk.
AWS Batch supports diverse workloads by allowing users to define job queues, specify dependencies, and leverage AWS Fargate or EC2 instances for execution. For example, a data pipeline could use AWS Batch to process large CSV files stored in Amazon S3, convert them to a structured format like Parquet, and load them into Amazon Redshift for analytics.
Data Integration
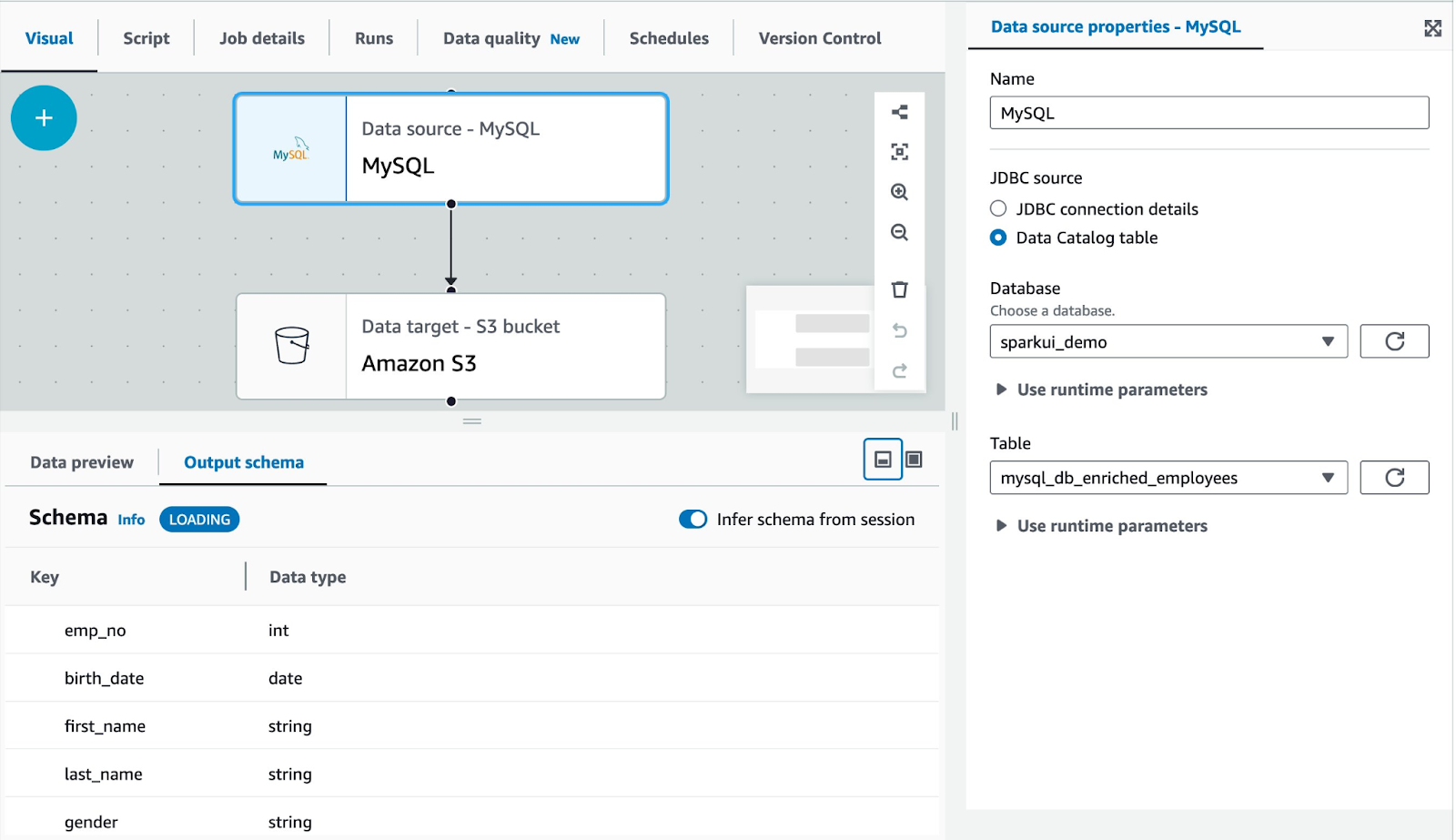
2. AWS Glue
AWS Glue is a fully managed ETL service that automates data integration by discovering, cataloging, and transforming data across multiple sources. It provides a serverless environment for writing ETL scripts in Python or Scala and supports both batch and streaming workloads. Glue’s Data Catalog helps centralize metadata, making it easier to query and manage datasets across services like Amazon S3, Redshift, and Athena.
For example, a data pipeline might use Glue to extract customer transaction data from an RDS database, clean and transform it, and then load it into a Redshift data warehouse for business intelligence. Glue’s ability to generate schema recommendations and automate transformations reduces the need for manual intervention.
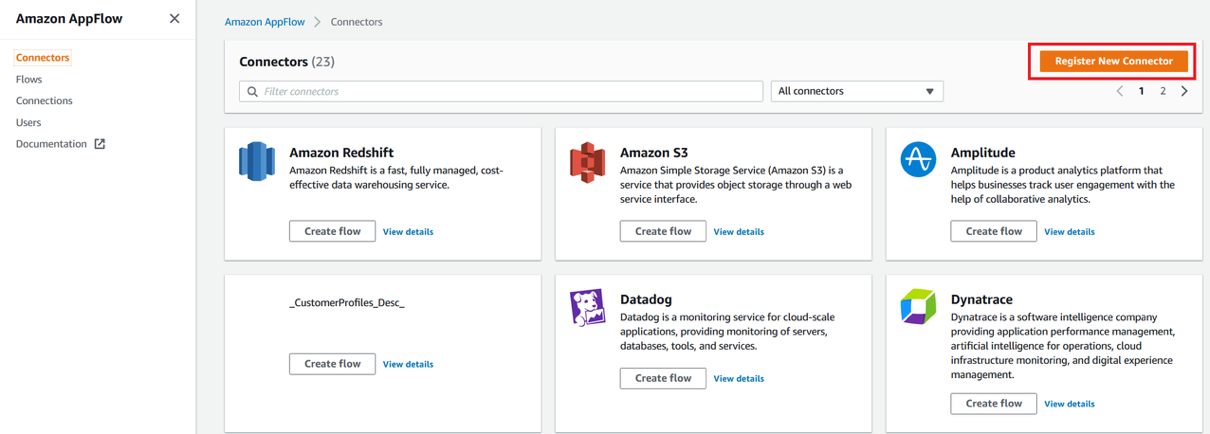
3. AWS AppFlow
AWS AppFlow simplifies data integration by enabling no-code/low-code data transfers between SaaS applications (such as Salesforce, ServiceNow, or Google Analytics) and AWS services. It supports scheduled or event-driven transfers, applying transformations like field mapping and data validation before delivering the data to its destination.
For example, an organization might use AppFlow to sync marketing campaign data from Salesforce into an S3-based data lake, where it is later analyzed using AWS Glue and Athena. By reducing the complexity of connecting third-party applications with AWS, AppFlow accelerates data ingestion while maintaining security and compliance.
Real-Time Data Processing
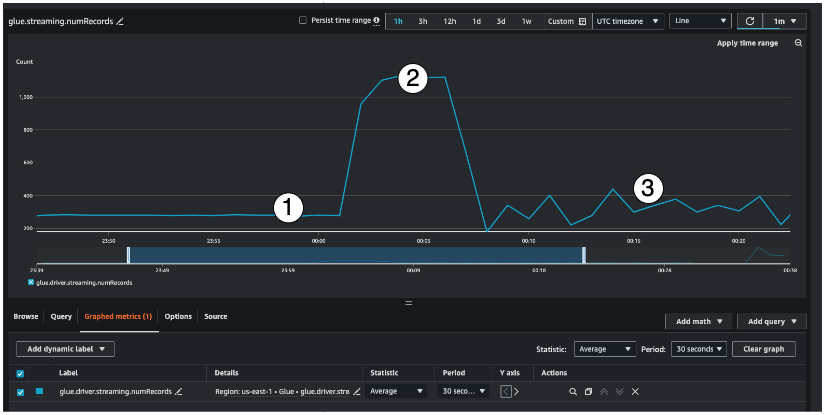
4. AWS Glue Streaming
AWS Glue Streaming is an extension of AWS Glue, tailored for real-time data transformations. It connects to streaming sources like Amazon Kinesis Data Streams or Apache Kafka to ingest and process data as it arrives.
For example, Glue Streaming can clean, deduplicate, and enrich streaming data in real time before delivering it to a data lake or downstream analytics tools. This is suitable for applications such as real-time analytics dashboards or fraud detection systems that require immediate insights.
5. AWS Lambda
AWS Lambda is a serverless compute service that lets users run code in response to events without provisioning or managing servers. It supports real-time event-driven workflows by processing data as soon as it is ingested.
For example, Lambda can parse JSON log files from Amazon S3, process IoT device telemetry data, or trigger data pipelines in response to new files being uploaded. Lambda's low-latency processing, coupled with automatic scaling, ensures that it can handle unpredictable data volumes.
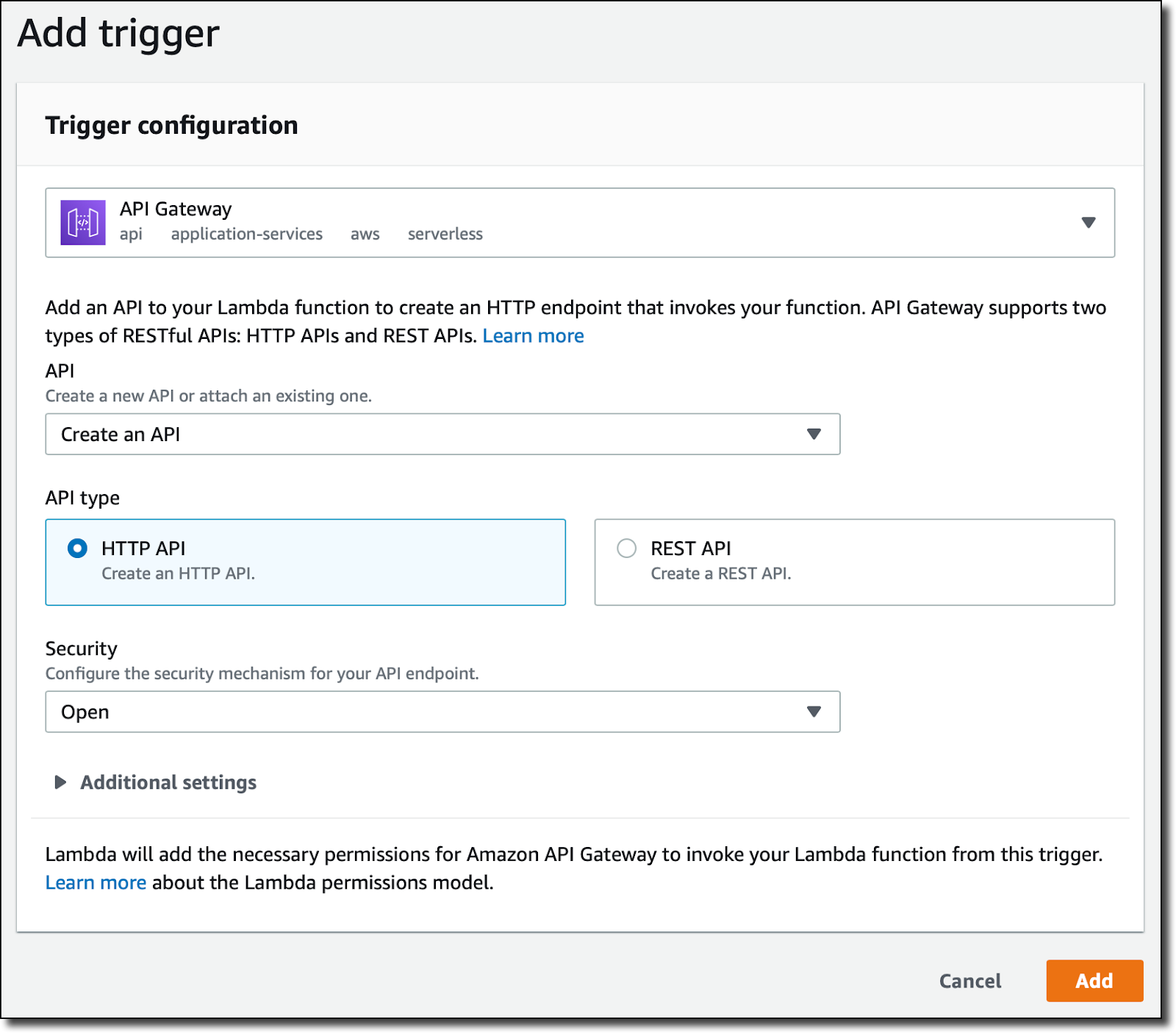
Data Warehousing (AWS Redshift)
6. Amazon Redshift
Amazon Redshift is a fully managed data warehouse that enables fast query performance on large datasets. It is optimized for analytical workloads, supporting columnar storage and massively parallel processing (MPP) to improve query efficiency. Redshift integrates with AWS services like Glue, S3, and Kinesis to enable seamless data ingestion.
For example, a data pipeline might extract transactional data from an operational database, transform it using AWS Glue, and load it into Redshift for advanced analytics. Redshift Spectrum further extends its capabilities by allowing queries on structured and semi-structured data stored in S3 without moving the data.
Workflow Orchestration
7. AWS Step Functions
AWS Step Functions simplifies the orchestration of distributed workflows, ensuring reliable execution of each step in a pipeline. Using its state machine model, users can define tasks, specify their sequence, and include conditional branching, retries, and error-handling logic.
For example, developers can build a pipeline that ingests data with AWS Glue, processes it with AWS Batch, and stores it in Amazon S3, all coordinated by Step Functions. Its integration with AWS services ensures that pipelines are tightly coupled with the underlying infrastructure, improving reliability and reducing the complexity of manual coordination.
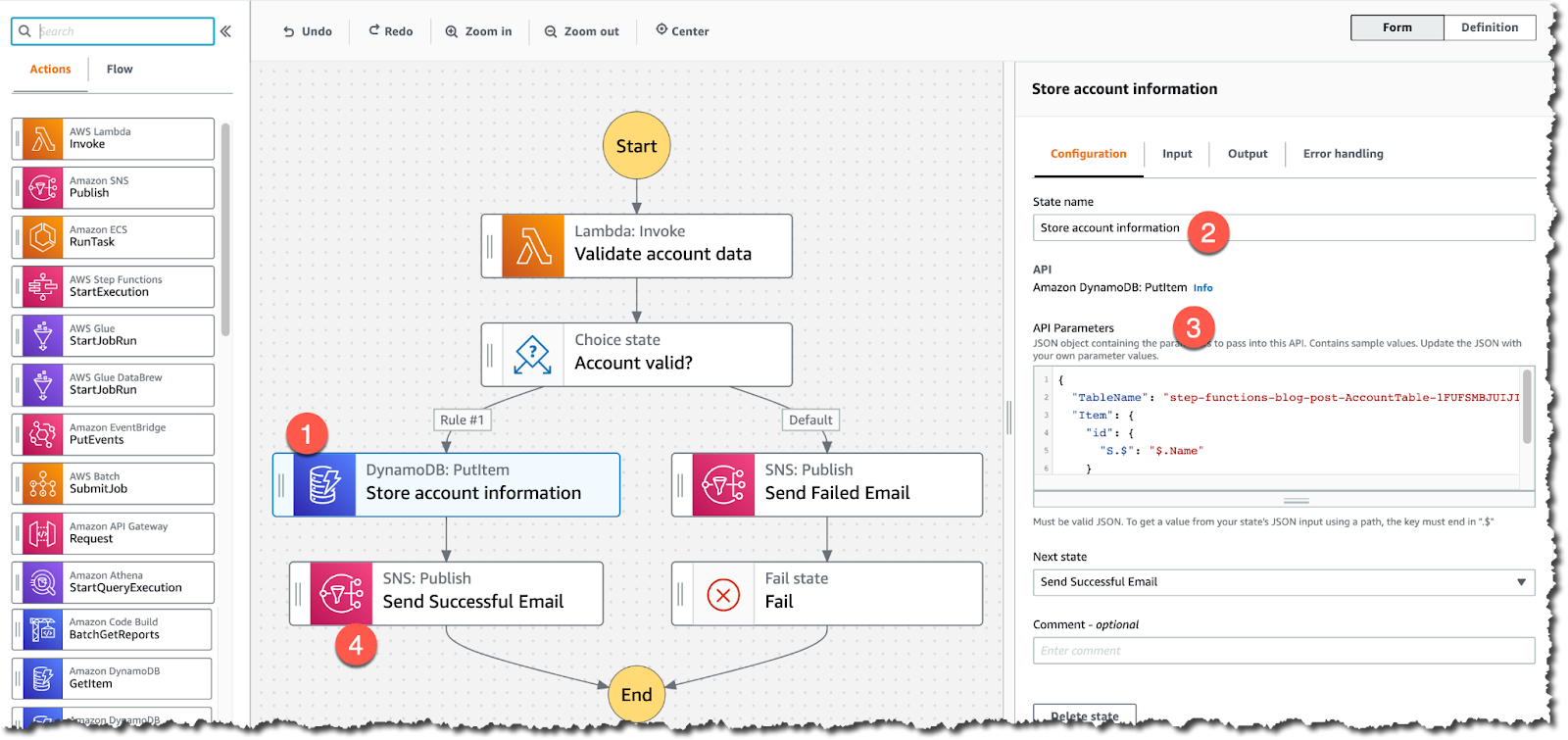
8. AWS MWAA
AWS Managed Workflows for Apache Airflow (MWAA) provides a managed service for Apache Airflow, a widely used open-source tool for orchestrating workflows. MWAA lets users define workflows as Directed Acyclic Graphs (DAGs), enabling developers to create and schedule complex pipelines that span multiple systems.
For example, a developer could design a DAG to pull data from external APIs, transform it with Python scripts, and store the results in a database. MWAA integrates with services like Amazon Redshift, S3, and Lambda, allowing it to manage data movement across the AWS ecosystem while providing a familiar interface for developers who already use Airflow.
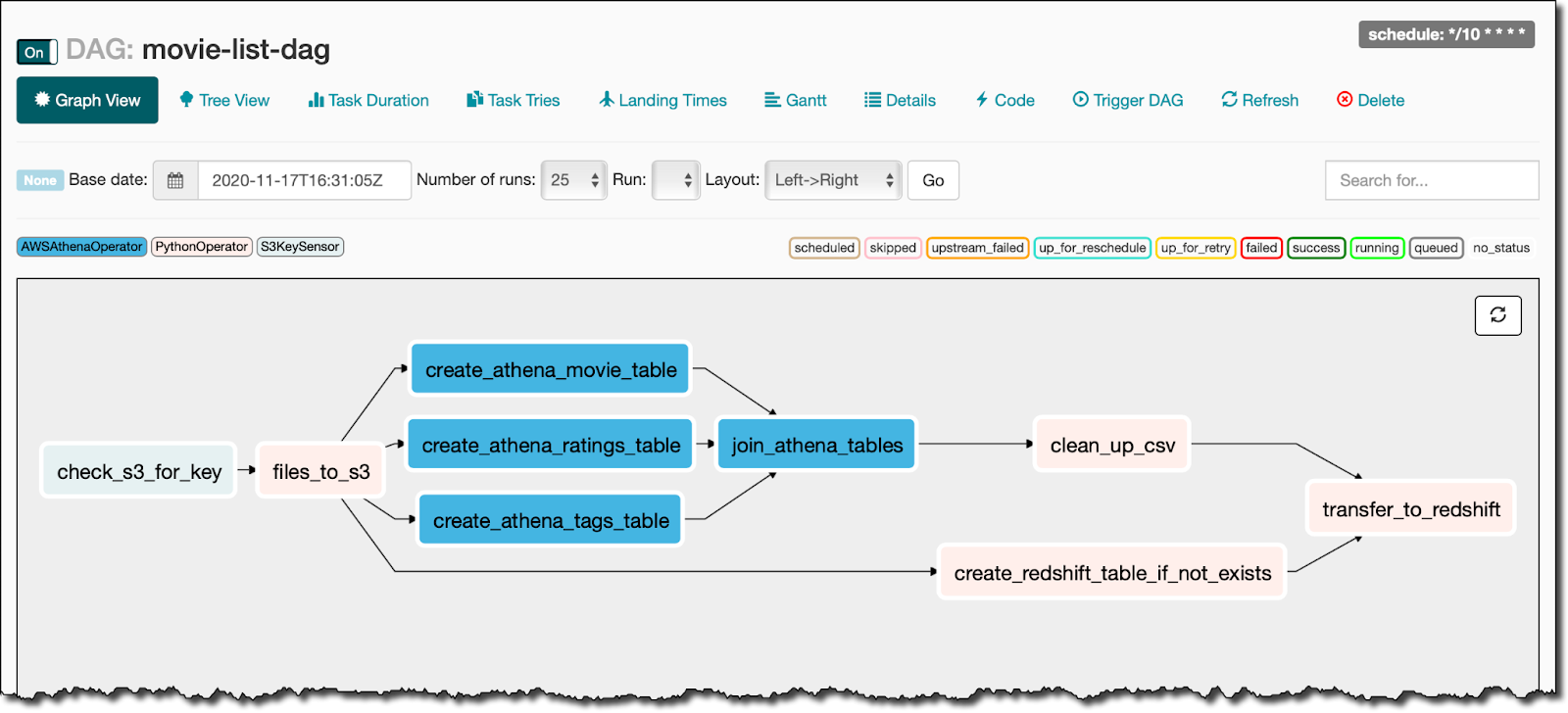
Data Storage and Transfer
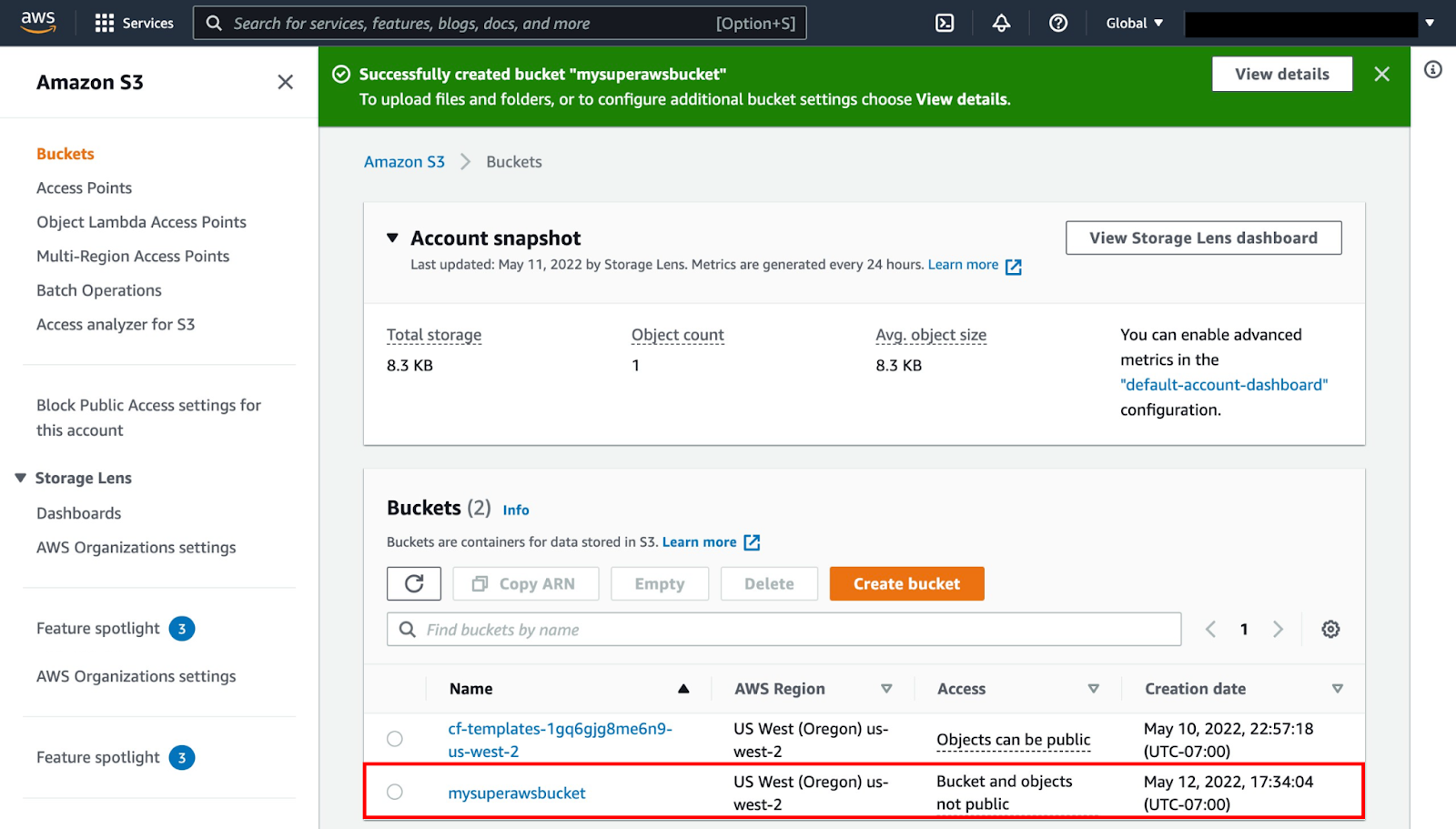
9. Amazon S3
Amazon S3 is a scalable object storage service that serves as the backbone for many data pipelines. It can store raw, processed, and archived data in multiple formats, including CSV, Parquet, and JSON. With features like S3 Select, users can query data directly within S3 without moving it to another system, saving time and resources.
S3 also supports lifecycle policies and intelligent tiering, automatically optimizing storage costs by moving older data to lower-cost storage classes. Its integration with services like Glue, Redshift, and Athena makes it a key component of data pipelines for storage and processing.
10. AWS DataSync
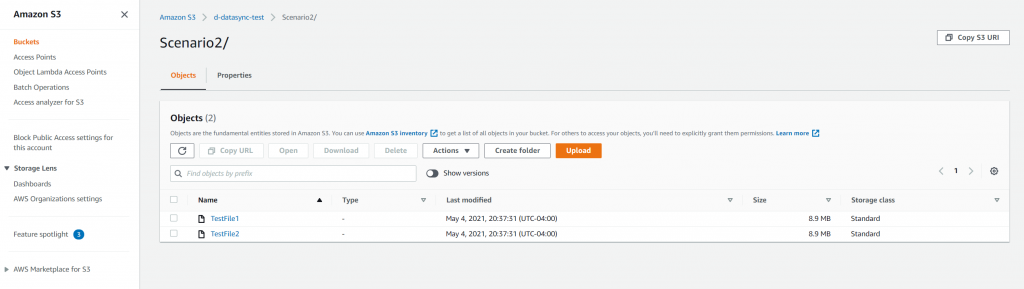
AWS DataSync can accelerate and simplify the transfer of data between on-premises systems and AWS or between different AWS storage services. It automates tasks such as file transfers, data synchronization, and migration, ensuring that the pipeline always has access to the latest data.
DataSync includes built-in data validation, ensuring that transferred data is accurate and complete. For example, DataSync can be used to continuously sync on-premises database backups to Amazon S3, ensuring that the pipeline has up-to-date information for processing.
Monitoring and Logging
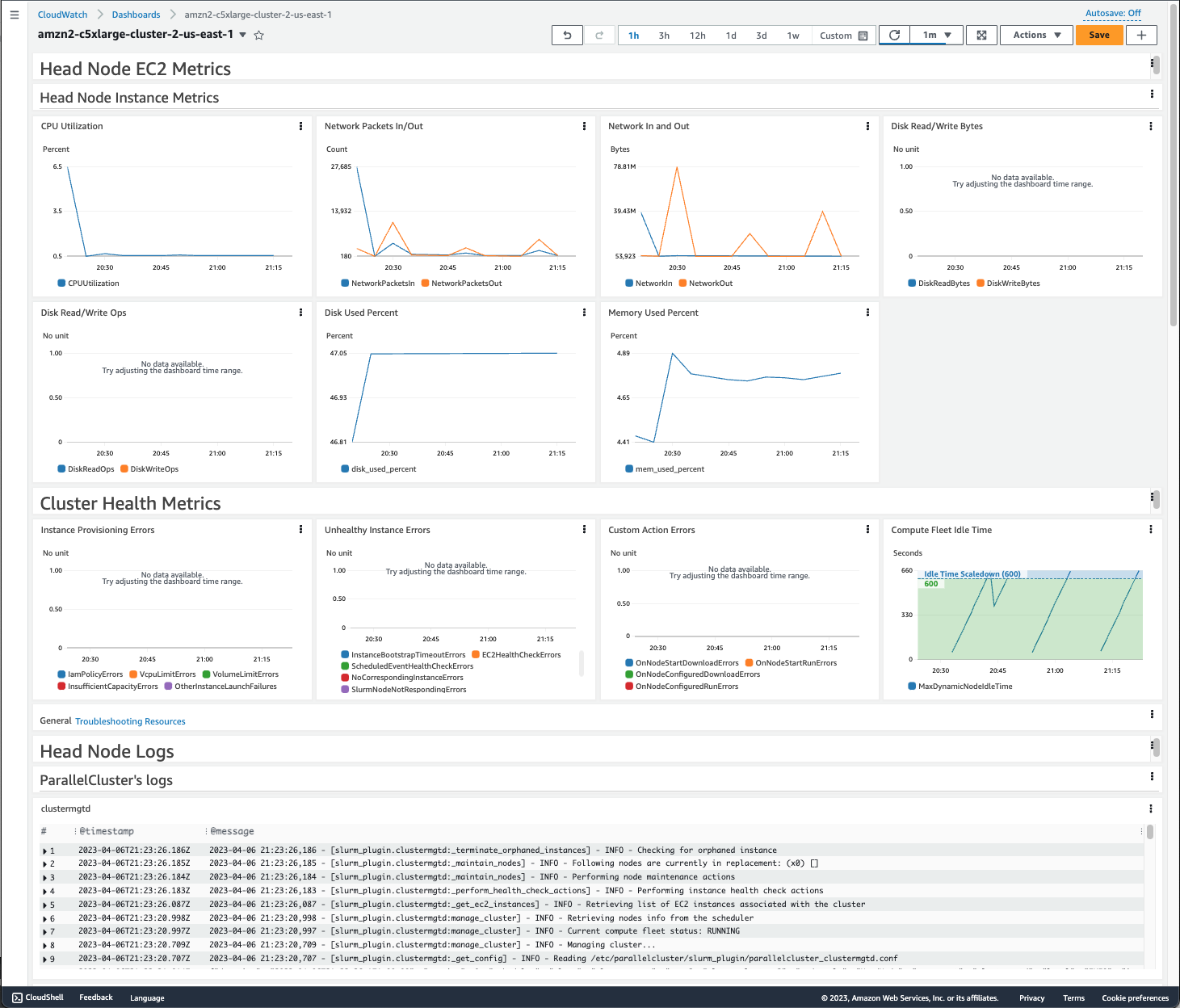
11. Amazon CloudWatch
Amazon CloudWatch provides real-time monitoring and logging for AWS resources and applications. It collects and tracks metrics, such as CPU utilization, memory usage, and data transfer rates, across the services used in the data pipeline.
CloudWatch Logs enable detailed analysis of pipeline activities, such as debugging ETL jobs or identifying performance bottlenecks in AWS Glue or Lambda functions. Additionally, users can create alarms to notify the team of issues like job failures or unexpected data latencies, ensuring that the pipeline runs smoothly.
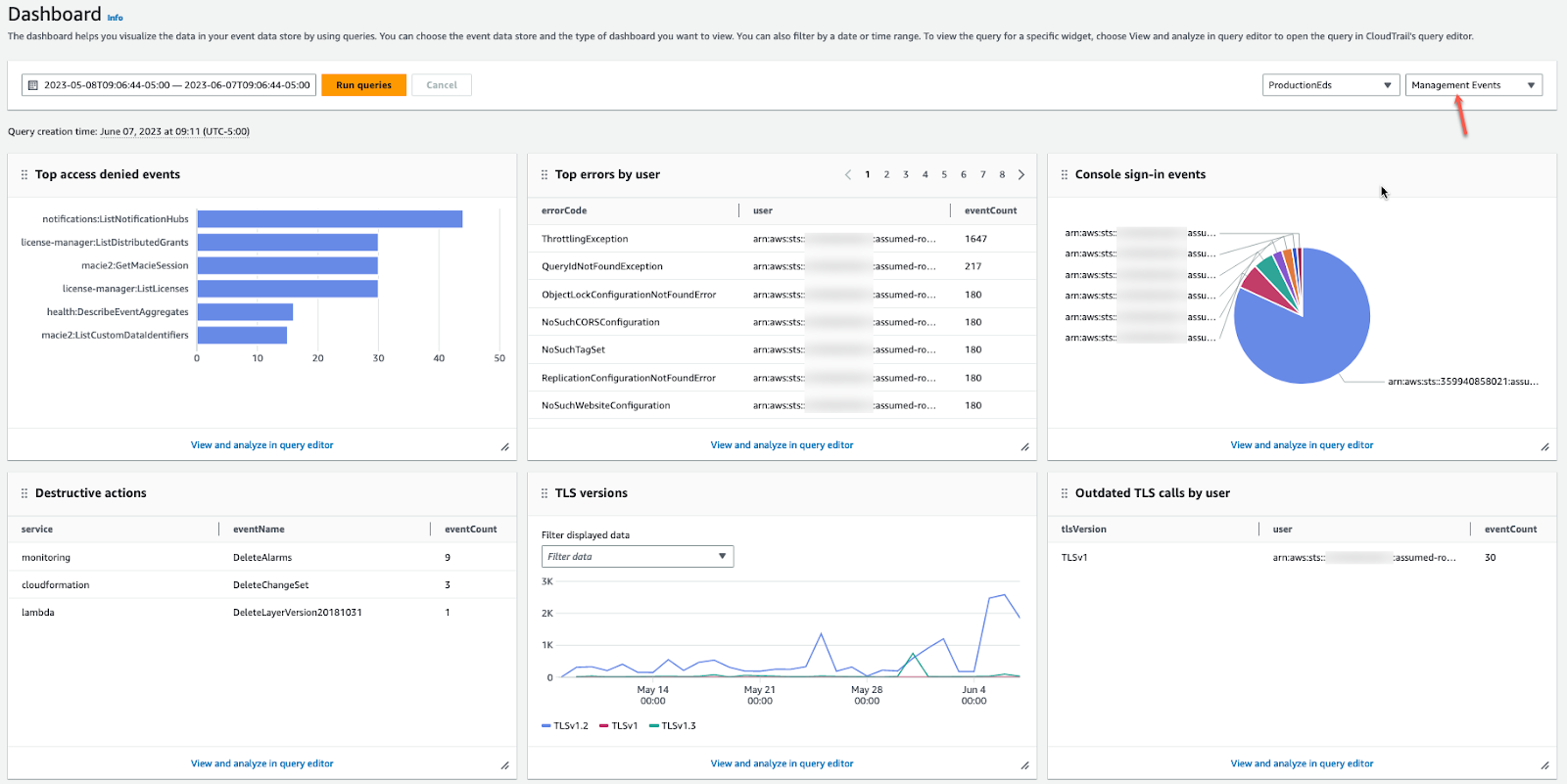
12. AWS CloudTrail
AWS CloudTrail offers detailed tracking of API calls and user activity within the AWS environment. It provides logs that show who accessed what resource and when, making it an essential tool for auditing and compliance. For example, CloudTrail can help trace the origin of a pipeline failure by identifying the exact configuration changes or API calls that occurred before the issue.
5 Best Practices for Building Data Pipelines on AWS
Here are some useful practices to consider when creating a data pipeline in an AWS environment.
1. Define a Clear Data Pipeline Architecture
Designing a well-structured data pipeline architecture is essential for ensuring scalability, efficiency, and maintainability. Begin by identifying the sources of the data and the required transformations before determining the best destination system for storage and analysis. Consider whether data should be stored in a data lake (Amazon S3) for flexibility or a data warehouse (Amazon Redshift) for analytical queries.
Clearly define the flow of data, specifying how each stage (ingestion, transformation, storage, and delivery) will be handled. Use tools like AWS Step Functions or MWAA to orchestrate workflows and manage dependencies between stages. Proper architecture ensures the pipeline is modular and can accommodate future changes, such as integrating new data sources.
2. Implement Robust Security Measures
Protecting the data pipeline is critical to ensure confidentiality, integrity, and compliance. Leverage AWS Identity and Access Management (IAM) to enforce fine-grained permissions, ensuring that only authorized users and services can access pipeline components. For sensitive data, use encryption both in transit (e.g., with SSL/TLS) and at rest (e.g., using AWS Key Management Service with S3 or RDS).
Enable logging and monitoring using AWS services like CloudTrail and CloudWatch to detect and respond to suspicious activity. Additionally, implement network security by using Virtual Private Clouds (VPCs), security groups, and private endpoints to control access to resources.
3. Balance File Sizes to Improve Processing Efficiency
Efficient data processing in pipelines often depends on the size of the files being handled. Too many small files can lead to excessive overhead, while very large files can slow down processing. Optimize file sizes based on the tools and services being used. For example, when working with Amazon S3 and Amazon EMR, aim for file sizes between 128 MB and 1 GB to maximize parallel processing efficiency.
Organizations can use AWS Glue or custom scripts to combine smaller files into appropriately sized partitions before storage. Similarly, when writing output from a data pipeline, consider splitting large datasets into manageable chunks for easier downstream processing and analysis.
4. Incorporate Data Validation and Error Handling Mechanisms
To ensure the quality and reliability of the pipeline, incorporate validation checks at every stage. Validate data during ingestion by verifying schema, data types, and completeness. Use tools like AWS Glue's DataBrew or Lambda functions to detect anomalies, such as missing values or outliers, and either log them for later inspection or correct them in real time.
Implement error-handling mechanisms to manage pipeline failures gracefully. For example, configure retries in AWS Step Functions or enable checkpointing in streaming tools like Kinesis Data Streams to prevent data loss. Detailed error logging via CloudWatch Logs can help quickly identify and resolve issues, minimizing downtime.
5. Combine Multiple Processing Steps to Simplify Operations
Consolidating related processing tasks can reduce complexity and improve performance in the pipeline. For example, rather than executing separate jobs for data cleaning, aggregation, and enrichment, use AWS Glue or Spark jobs to handle these steps in a single operation. This minimizes intermediate data movement and reduces the overall runtime.
Use orchestration tools like Dagster and AWS Step Functions to group tasks logically, ensuring dependencies are maintained while avoiding unnecessary duplication of effort. By combining steps, teams can simplify pipeline management and optimize resource usage.
Orchestrating Data Pipelines in the Cloud with Dagster
Dagster is an open-source data orchestration platform for the development, production, and observation of data assets across their development lifecycle.
Thanks to its modular design and rich feature set, Dagster serves as the unified control plane for data processes across the organization, with built-in data lineage tracking and observability, an asset catalog, data validation checks, and best-in-class testability.
With native support for observing non-Python workflows and integrations with the most popular data tools and leading cloud providers like AWS, Dagster integrates seamlessly with your existing data stack.






.jpg)
.png)



.png)

