


What Is a Data Quality Platform?
A data quality platform is a system that ensures organizational data is accurate, consistent, and accessible. These platforms integrate tools and techniques to monitor, manage, and improve data quality across the enterprise. They typically offer features like data profiling, cleaning, matching, and enrichment.
By using a data quality platform, organizations can maintain data integrity, which is crucial for accurate analytics and informed decision-making. Data quality platforms work by automating the processes involved in identifying and correcting data errors. This automation reduces manual effort and minimizes the risk of human error.
This is part of a series of articles about data platforms.
What Data Quality Metrics Should You Track?
Completeness
Data completeness is the extent to which all necessary data is present. Incomplete data can lead to incorrect analysis and faulty decisions. Tracking completeness involves identifying missing data fields or records and assessing their impact on overall data quality. Maintaining completeness can involve data audits or automated checks that flag incomplete entries.
Accuracy
Data accuracy measures the correctness of data. Errors in data entry, outdated information, or incorrect data sources can significantly impede accuracy. Accurate data reflects what it is intended to represent without errors or misstatements. To ensure accuracy, data validation processes include regular audits and cross-verification against reliable sources.
Validity
Validity ensures data conforms to set rules and formats. It means data must fall within the established parameters, such as correct formats for dates or numbers and adherence to standard codes or classifications. Ensuring data validity requires implementation of constraints and predefined rules. Valid data is essential for maintaining consistency and uniformity in datasets.
Timeliness
Timeliness refers to the availability of data when needed. For data to be useful, it must be up-to-date and accessible promptly. This metric measures how fast data becomes available after an event or transaction occurs. In industries like finance, real-time data delivery is crucial for decision-making. Systems that support timely data delivery often include automated updates and alerts.
Consistency
Consistency in data quality refers to the uniformity of data across various sources and datasets. Data should not conflict with other datasets and should maintain harmony across different systems. To achieve consistency, data synchronization and reconciliation practices are necessary.
Uniqueness
Uniqueness ensures that each data entry is distinct and not duplicated across datasets. Duplicate entries can corrupt analysis, inflate metrics, and lead to inefficiencies in data handling. This metric helps in maintaining the originality and reliability of data records. Organizations use deduplication processes to identify and eliminate duplicate records, ensuring clean and representative data.
Benefits of Using Data Quality Tools
Data quality platforms helps organizations achieve the following benefits:
- Improving data accuracy: Data quality tools help eliminate errors by identifying inconsistencies and inaccuracies and providing methods to rectify them. By leveraging automated processes, organizations minimize manual data entry errors, thus enhancing overall accuracy. Consistent data entry and validation protocols further improve reliability, ensuring that data used in reports and analytics is dependable.
- Enhanced decision-making: High-quality data enables organizations to make informed decisions with greater precision and confidence. Tools that validate and clean data ensure that insights drawn from data reflect actual business conditions. By providing accurate and comprehensive data, these tools support strategic planning and operational decisions.
- Data governance and compliance: Effective governance requires ensuring data is compliant with policies and regulations. These tools enable the enforcement of data standards and practices required for regulatory compliance. Data quality also helps adhere to legal and industry standards by verifying data accuracy, completeness, and security, helping organizations manage compliance risks through automated checks and documentation.
Key Features of Data Quality Tools
Here are some of the key features offered by a modern data quality tool:
- Data profiling and discovery: Most platforms offer tools to explore data sources, revealing structural insights, patterns, and anomalies. Profiling helps organizations understand their data and prepare it for quality checks by identifying trends and potential issues in real-time.
- Automated data cleaning: Automated rules for data correction, standardization, and formatting streamline the cleaning process, reducing manual intervention. This feature helps resolve inconsistencies, such as typographical errors or mismatched formats, to improve overall data reliability.
- Data matching and deduplication: Many tools include deduplication to detect and merge duplicate entries, and data matching to correlate records from disparate sources. This ensures that each entity (like a customer or product) is uniquely represented, enhancing the accuracy of analyses.
- Real-time monitoring and alerts: These platforms often support real-time data quality monitoring, alerting users to potential issues as they occur. Real-time alerts help prevent poor data from impacting operational processes, maintaining data reliability across platforms.
- Customizable validation rules: Custom validation rules allow organizations to apply specific criteria based on business requirements. This flexibility enables teams to enforce standards across different datasets, ensuring data quality aligns with unique operational needs.
- Data governance and compliance support: Many tools offer compliance and governance features, including support for industry standards and regulatory requirements. This ensures data adheres to legal and internal standards, helping organizations avoid compliance risks.
- Integration with data pipelines: Data quality platforms often integrate with ETL (Extract, Transform, Load) tools and other pipeline solutions, enabling data checks at each stage of data transformation. This ensures that quality issues are identified and resolved early in the data lifecycle.
- Reporting and metrics tracking: Built-in dashboards and reports enable organizations to track data quality metrics over time. Metrics tracking helps identify trends, measure improvements, and make data-driven adjustments to quality management strategies.
Notable Data Quality Platforms and Tools
1. Dagster

Dagster is an open-source data orchestration platform for the development, production, and observation of data assets across their development lifecycle, with a declarative programming model, integrated lineage and observability, data validation checks, and best-in-class testability.
License: Apache-2.0
Repo: https://github.com/dagster-io/dagster/
GitHub stars: 11K+
Contributors: 400+
Key features:
- Data asset-centric: Focuses on representing data pipelines in terms of the data assets (e.g., tables, machine learning models, etc.) that they generate, yielding an intuitive, declarative mechanism for defining data pipelines.
- Data quality checks: Natively supports running data quality checks at the time of materialization. Combining orchestration and data quality checks in the same platform ensures malformed or erroneous data is not transmitted to downstream systems.
- Observability and monitoring: Features a built-in data catalog, asset lineage, and a robust logging system.
- Cloud-native and cloud-ready: Provides a managed offering with robust, managed infrastructure, elegant CI/CD capability, and multiple deployment options for custom infrastructure.
- Integrations: Extensive library of integrations with the most popular data tools, including the leading cloud providers (AWS, GCP, Azure).
- Flexible: As a Python-based data orchestrator, Dagster affords you the full power of Python. It also lets you execute any arbitrary code in other programming languages and on external (remote) environments, while retaining Dagster’s best-in-class observability, lineage, cataloging, and debugging capabilities.
- Declarative Automation: This feature lets you go beyond cron-based scheduling and intelligently orchestrate your pipelines using event-driven conditions that consider the overall state of your pipeline and upstream data assets. This reduces redundant computations and ensures your data is always up-to-date based on business requirements and SLAs, instead of arbitrary time triggers.
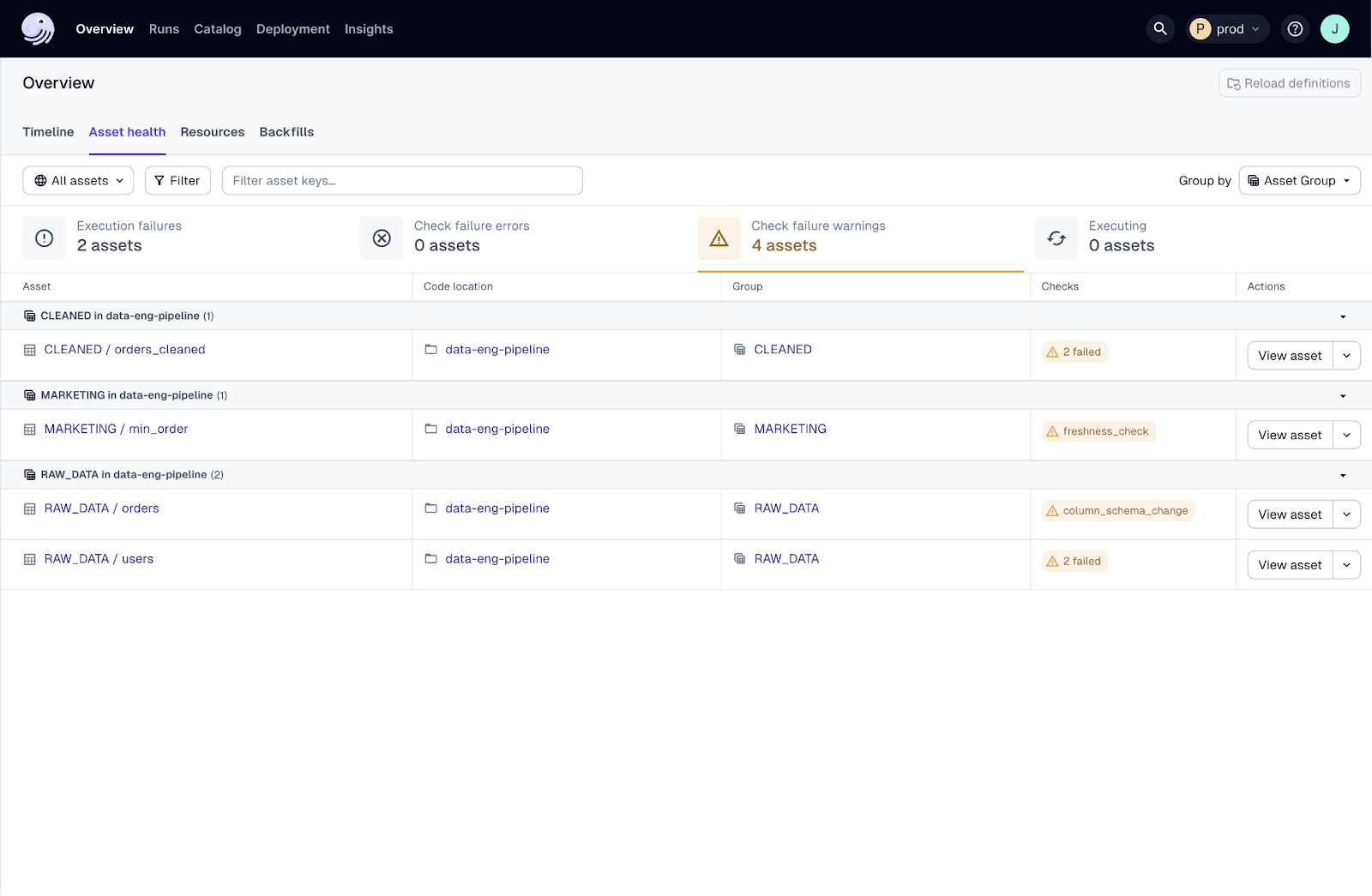
2. Monte Carlo

Monte Carlo is a data quality platform that automates monitoring and testing across production tables to ensure data reliability. By leveraging machine learning, Monte Carlo provides coverage recommendations and automatically checks for data timeliness, completeness, and validity. It supports deep monitoring on critical assets and allows the creation of custom monitors.
License: Commercial
Features:
- Automated out-of-the-box testing: Automated data quality tests with machine learning-powered monitoring across all production tables.
- Comprehensive coverage: Monitors for timeliness, completeness, and validity of data without the need for manual configuration.
- Customizable monitors: Allows for custom SQL rules and monitors-as-code to meet specific data quality needs.
- Incident detection and resolution: Provides alerts and rich insights to detect, triage, and resolve data incidents efficiently.
- Integrated notification channels: Notifies data owners immediately when anomalies or data incidents are detected, ensuring rapid resolution.
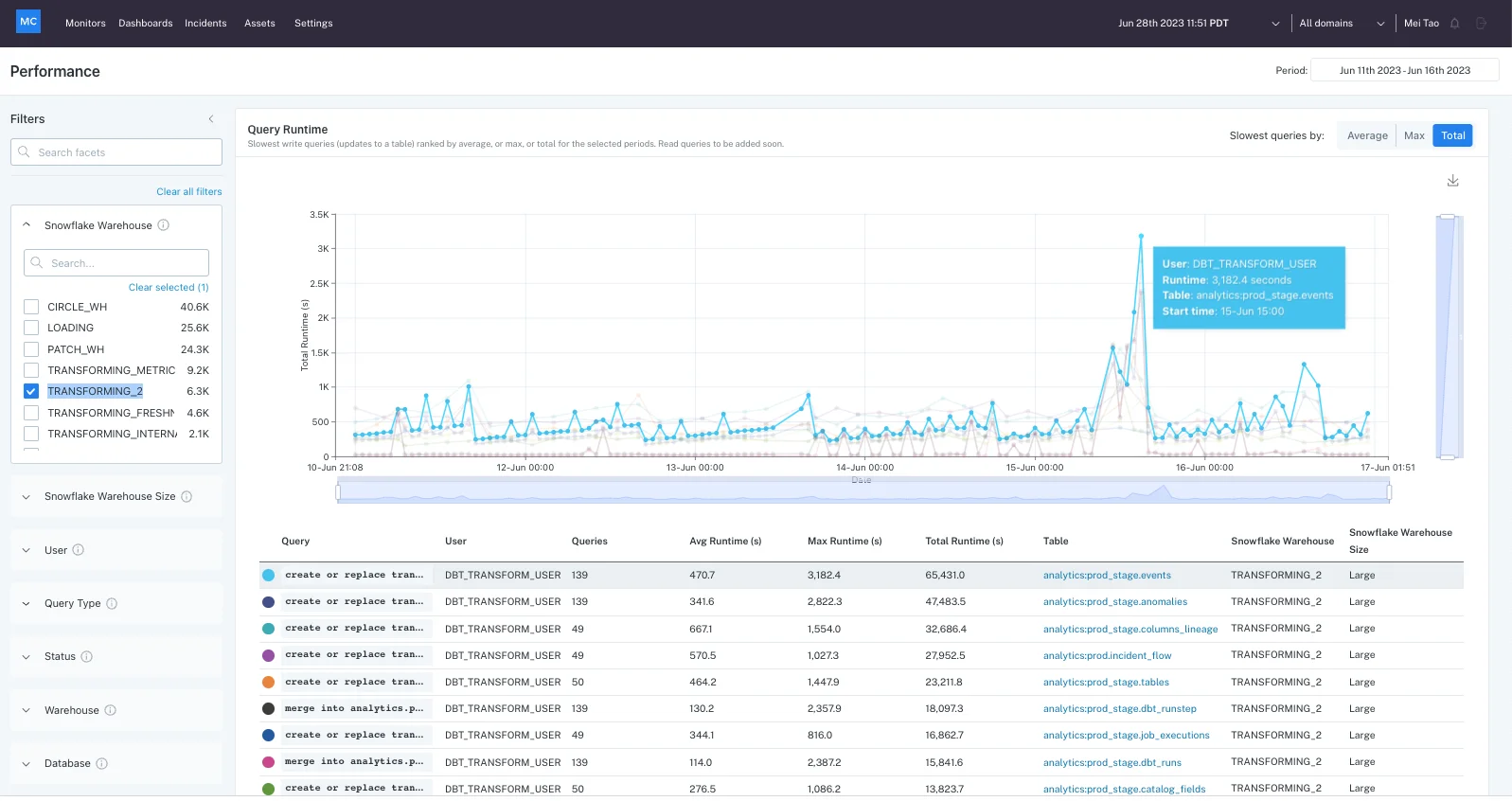
3. IBM InfoSphere Information Server

IBM InfoSphere Information Server is a data integration platform to help organizations manage, transform, and ensure the quality of their data. It offers scalable, massively parallel processing (MPP) capabilities, helping to clean, monitor, and integrate data from various systems.
License: Commercial
Features:
- Scalable data integration: Offers scalable ETL (extract, transform, load) capabilities, allowing integration across multiple systems both on-premises and in the cloud.
- Data governance: Provides tools for discovering IT assets and defining a unified business language, improving understanding and governance of data.
- Data quality monitoring: Continuously assesses and monitors data quality, with integrated rules analysis to ensure clean, reliable data.
- Business alignment and productivity: Helps organizations align their data strategies with business objectives, enhancing productivity by integrating with related IBM products.
- Cloud-ready deployment: Supports hybrid, public, and private cloud environments through hyperconverged systems like IBM Cloud Pak for Data.
4. Deequ

Deequ is a data quality library built on top of Apache Spark that enables users to create "unit tests" for large datasets, ensuring data quality before it is used in applications or machine learning models. It allows users to define constraints on data attributes and validate them against predefined rules, helping to detect and fix data errors early.
License: Apache-2.0
Repo: https://github.com/awslabs/deequ
GitHub stars: 3K+
Contributors: 60+
Features:
- Data unit testing: Provides tools for defining and running tests on data, ensuring data meets quality standards before being used in production.
- Scalability with Spark: Built to handle large datasets in distributed environments, making it suitable for data warehouses and big data platforms.
- Customizable data quality checks: Supports various checks such as ensuring non-null values, uniqueness, and compliance with predefined ranges or patterns.
- Anomaly detection: Automatically detects anomalies in data quality metrics over time, providing insights into data health trends.
- Metrics repository: Offers persistence and querying of computed data quality metrics, allowing users to track quality improvements and issues over time.
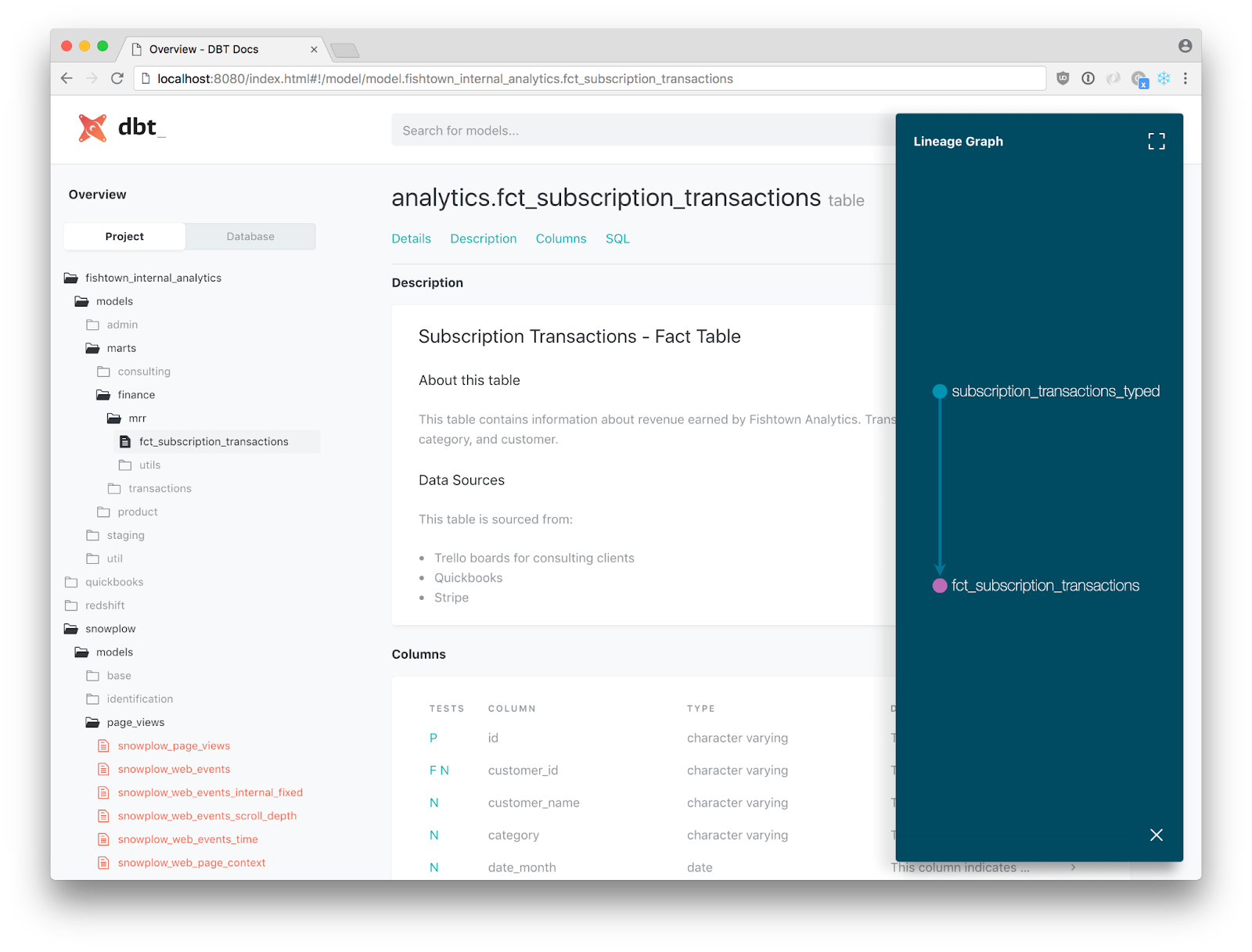
5. dbt Core

dbt Core is a SQL-first data transformation tool that enables data teams to collaboratively build, test, and deploy data pipelines with a focus on data quality and governance. By applying software engineering best practices like modularity, version control, and CI/CD, dbt ensures that data transformations are reliable, documented, and production-ready.
License: Apache-2.0
Repo: https://github.com/dbt-labs/dbt-core
GitHub stars: 9K+
Contributors: 300+
Features:
- Automated data testing: Built-in testing features allow teams to validate data models, ensuring data accuracy and consistency.
- Version control and CI/CD: Supports Git-enabled version control and CI/CD processes, enabling safe deployment across dev, stage, and production environments.
- Modular data transformations: Allows data transformations in SQL or Python, managing dependencies automatically to reduce errors and improve development speed.
- Data documentation: Automatically generates and shares documentation with stakeholders, providing transparency into data pipelines and building trust in the data.
- Governance and observability: Ensures data governance through version control, logging, and alerting, helping teams maintain compliance and monitor data quality in real time.
6. Ataccama ONE

Ataccama ONE is an AI-powered data management platform that combines data quality, governance, and observability into a single, cloud-native solution. It helps organizations control, monitor, and improve the quality of their data while ensuring it is secure and accessible.
License: Commercial
Features:
- Data quality management: Provides tools to understand, monitor, and improve data quality, while preventing data issues through automated mechanisms.
- Data cataloging: Offers automated data discovery, a business glossary, and a data marketplace, ensuring users can find and leverage high-quality data efficiently.
- Data observability: Monitors critical data sources and sends timely alerts to ensure continuous data reliability and accuracy.
- Master data management: Enables organizations to create and maintain a single, trusted version of master and reference data, ensuring consistent data across the enterprise.
- AI-driven matching and stewardship: Uses AI for data mastering, ensuring accurate matching of records and supporting data stewardship practices.
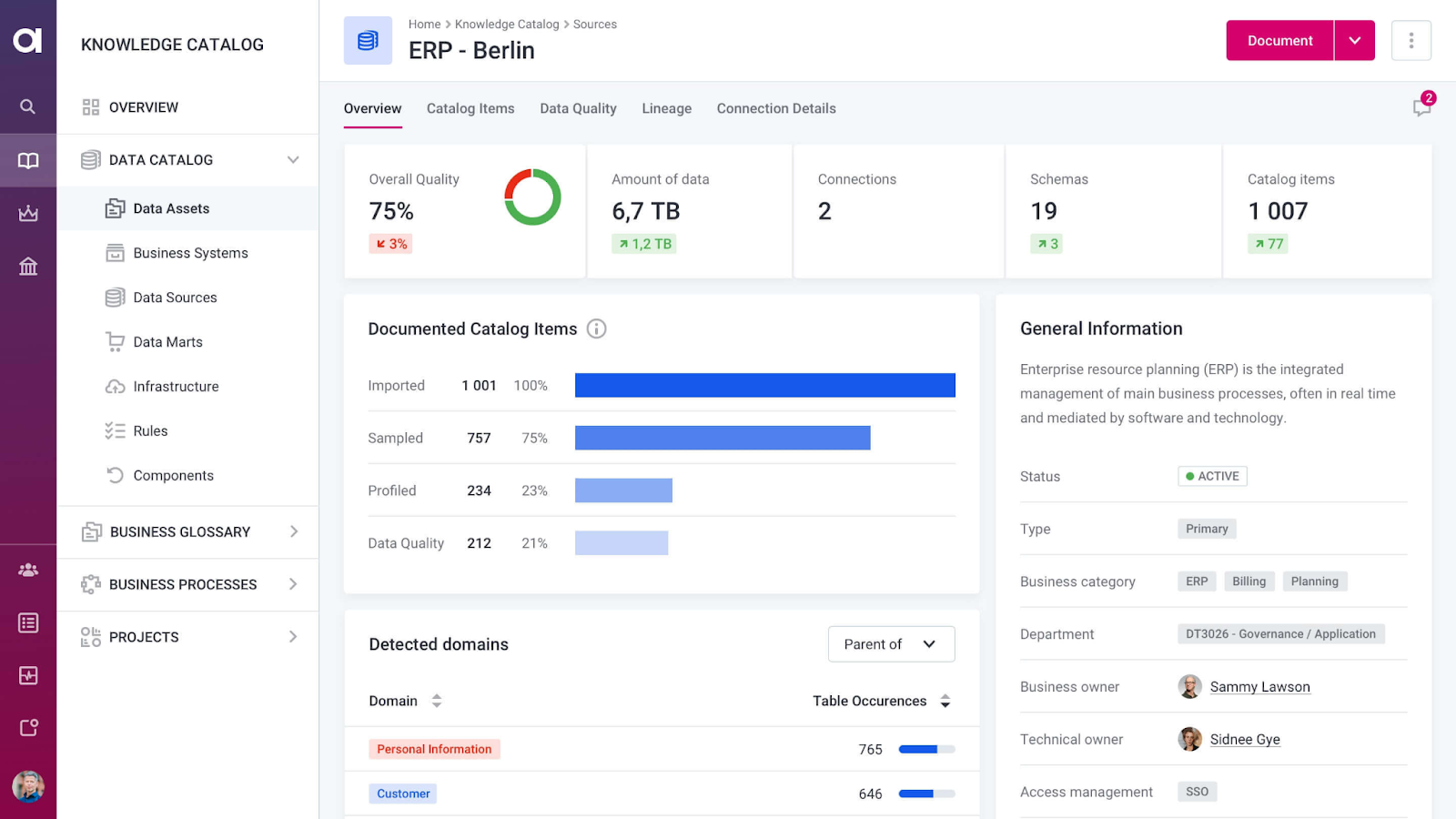
7. Great Expectations

Great Expectations (GX) is an open-source data quality framework that helps organizations build trust in their data by defining and testing data quality through "Expectations," which are data quality assertions. It provides an end-to-end solution for managing the data quality process, from initial exploration to continuous validation, ensuring that data remains reliable and accurate.
License: Apache-2.0
Repo: https://github.com/great-expectations/great_expectations
GitHub stars: 9K+
Contributors: 400+
Features:
- Expectation-based testing: Enables users to define clear, verifiable assertions about their data, covering key data quality dimensions such as schema, freshness, and missingness.
- End-to-end solution: Supports the entire data quality lifecycle, from exploratory profiling to continuous validation with historical results tracking.
- Integrations: Integrates easily with existing data stacks and can be deployed throughout pipelines to pinpoint and resolve data quality issues quickly.
- Collaborative interface: Offers a plain-language interface that allows both technical teams and business stakeholders to participate in the data quality process.
- Scalability: GX Cloud can scale across your organization, ensuring data quality processes can be extended wherever they are most needed.
8. Informatica Cloud Data Quality

Informatica Cloud Data Quality is an AI-powered platform to manage the entire data quality process, allowing companies of any size to analyze, clean, and enhance their data for reliable analytics and decision-making.
License: Commercial
Features:
- AI-powered: Uses AI to automatically identify data issues, generate rules, and detect anomalies, speeding up the data quality process.
- Data profiling and observability: Offers tools for iterative data analysis, allowing users to continuously monitor and understand data health.
- Prebuilt rules for data cleaning: Provides a set of prebuilt rules to quickly profile, clean, standardize, and enrich data.
- Data transformation tools: Includes capabilities for data verification, standardization, deduplication, and cleaning to ensure data accuracy and consistency.
- Elastic infrastructure: Supports high-performance data pipelines with scalable infrastructure to handle large volumes of data efficiently.
9. SAS Data Quality

SAS Data Quality is a platform that simplifies the process of preparing, cleaning, and enriching data for analysis. With its low-code/no-code interface, users can easily manage data quality without needing advanced technical skills or coding expertise.
License: Commercial
Features:
- Low-code/no-code interface: Offers a visual flow builder for data wrangling and preparation, eliminating the need for coding and enabling self-service data management.
- Data profiling and cleaning: Provides industry-leading data profiling tools and prebuilt transformations to detect and resolve data quality issues quickly and efficiently.
- In-memory processing: Executes data preparation tasks in memory, allowing for real-time data transformations and speeding up the data quality process.
- Collaboration and reusability: Supports collaboration on data projects with reusable workflows, ensuring consistent data quality across teams and throughout the data lifecycle.
- Entity resolution: Helps to identify and resolve duplicate or inconsistent data entries, ensuring accurate, high-quality data for analytics.
10. Collibra Data Quality & Observability

Collibra Data Quality & Observability is a platform that monitors data quality and pipeline reliability to help organizations quickly identify and resolve data anomalies. By leveraging AI-driven rules and real-time monitoring, Collibra ensures that bad data is caught before it impacts downstream systems.
License: Commercial
Features:
- AI-generated adaptive rules: Automatically generates thousands of monitoring controls, adapting to data changes to prevent bad data from propagating downstream.
- Data classification and enforcement: Automatically classifies sensitive data using prebuilt, industry-specific rules, enforcing data quality controls across your data assets.
- Generative AI for rule creation: Supports natural language prompts to write complex data quality rules, accelerating the development of custom rules with reusable templates.
- Pipeline health monitoring: Provides visibility into data pipeline health by business unit and data source, allowing teams to detect and resolve data quality issues before they affect operations.
- Schema change detection: Monitors for unexpected schema changes to ensure data validity and prevent potential disruptions in dashboards, reports, and other assets.
Conclusion
Maintaining high data quality is critical for organizations to drive accurate analytics, informed decision-making, and overall operational efficiency. Data quality platforms offer robust tools and automations to ensure data is accurate, consistent, and reliable across diverse sources and systems.
By implementing data quality management practices, organizations can mitigate the risks associated with poor data, enhancing business outcomes and ensuring compliance with regulatory standards.
Data quality can also be improved by tightly coupling data quality checks with the orchestration of the processes that generate the data. This is exactly what Dagster’s Asset Checks feature enables, proactively alerting you to any data quality issues and preventing erroneous data from flowing to downstream systems.
To learn more about how Dagster can serve as the single pane of glass for the health of your data pipelines, see this deep dive into Asset Checks.






.jpg)
.png)



.png)

