




The unseen data is often the deadliest. Here’s how to shine a light on it in your business.
Unorganized data systems make you pull your hair out in frustration or deal with serious consequences, mostly because you can’t understand the state of data within/between these systems and how data moves from one system to the next.
Think of two libraries:
- An unorganized one, where books are scattered everywhere. Important books are missing or missed, leading to bad decisions, missed opportunities, and increased operational costs due to inefficiency.
- An organized one, with clear labels, proper placement, regular maintenance, and detailed borrowing logs, all of which make for efficient access to information and reduced costs associated with time waste and resource mismanagement.
The organized library is a great example of good data visibility in businesses, where data is managed and used effectively. Bad data visibility can hurt organizations through missed opportunities, poor data quality, bad decisions, inefficiencies and incomplete data, compliance issues, and big financial losses.
In this primer, I’ll get (or keep) you up to speed on the importance of data visibility in data engineering, the risks and financial implications of bad visibility, and guide you towards more visible and actionable data management practices.
What is Data Visibility?
Data visibility is the ability to see, track, and understand data as it moves through an organization’s systems. It consists of three main components: lineage, monitoring, and access transparency– all essential to data observability.
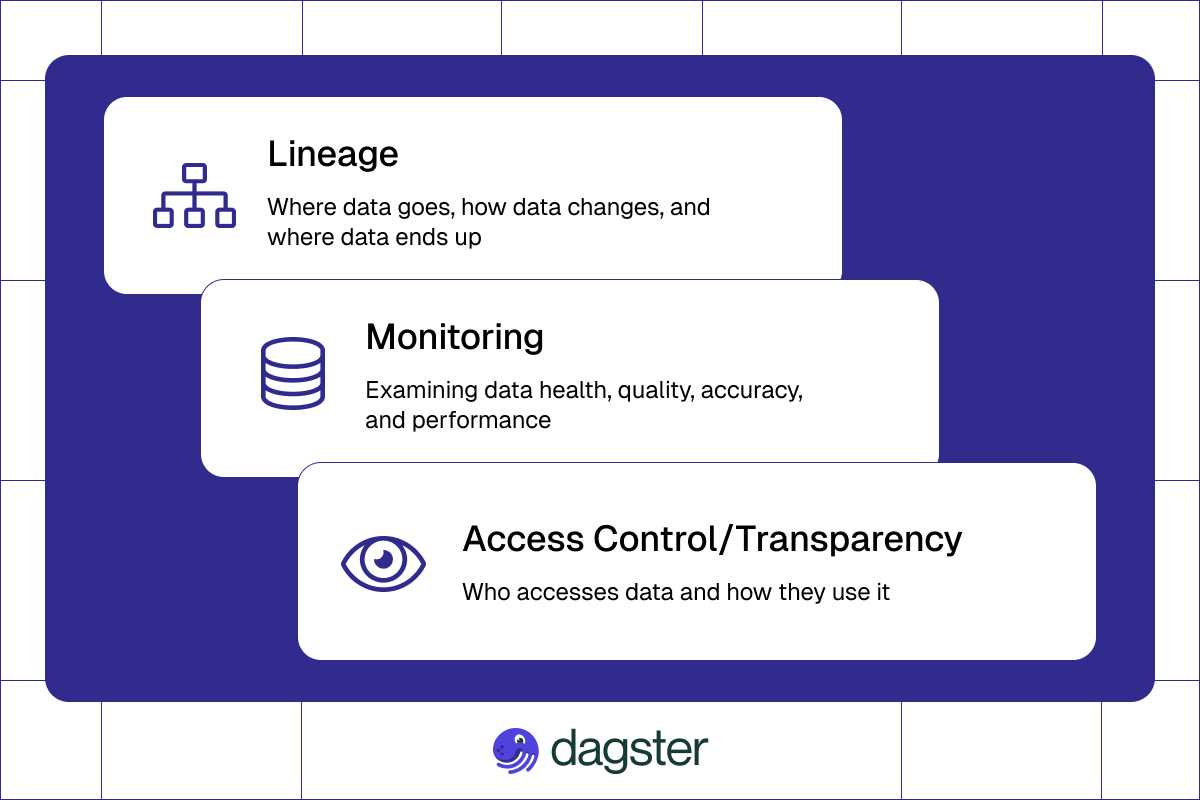
Data Lineage
Lineage is being able to trace the origin, transformations, and journey of data throughout its lifecycle. This lets you know where your data comes from, how it changes over time, and where it ends up to ensure data reliability. Understanding data lineage is essential for maintaining the health of the entire data ecosystem.
Key metrics for data lineage include data flow complexity, data source, data reliability, and transformation accuracy. To improve data lineage, you can implement data cataloging systems and lineage tools that track the flow and transformation of data across systems.
Data Monitoring
Monitoring is real-time tracking of data health, quality, and performance. This ensures that data is accurate and reliable throughout its lifecycle and helps in quick recovery from errors.
Important monitoring metrics are data freshness, error rate, and system performance. To improve data monitoring, data engineering teams can use tools that provide a comprehensive inventory of available data assets and track data quality in real-time.
Access Transparency
Access transparency provides visibility into who is accessing data and how they use it. This is important for security, compliance, and understanding data usage patterns. A well-maintained data environment is crucial for ensuring effective access transparency and overall data quality.
Metrics around access transparency are access frequency, user engagement, and compliance score. To improve access transparency, you can implement access monitoring solutions to track who is accessing data and how it’s being used.
These three components provide visibility at different levels, from high-level data flow overviews to detailed logs and metadata, and are essential to provide visibility and reliable data to the people who need the information within your organization.
Who Needs Data Visibility and Why?
Data visibility goes way beyond just the data engineering team.
It affects every level of the organization, from individual contributors to top executives, and plays a crucial role in enhancing business processes. Understanding the different data visibility needs within your organization is key to a good data management strategy.
More data visibility means the information is accessible and understandable to all relevant stakeholders across the organization. When you have it, it will boost organizational efficiency, reduce workload on your data team, and impact several key areas:
- Data Quality: Allows you to find and correct errors, duplicates, and inconsistencies, affecting metrics like freshness, completeness, and accuracy
- Operational Efficiency: Reduces delays, avoids bottlenecks, and streamlines data operations.
- Security and Compliance: Tracks data access and ensures compliance
- Decision Support: Provides context for informed decisions
- Time to Recovery (TTR): Can reduce time to identify and resolve issues
Each stakeholder has different requirements and use cases for data visibility, which directly impact their ability to do their job and contribute to the organization’s success.
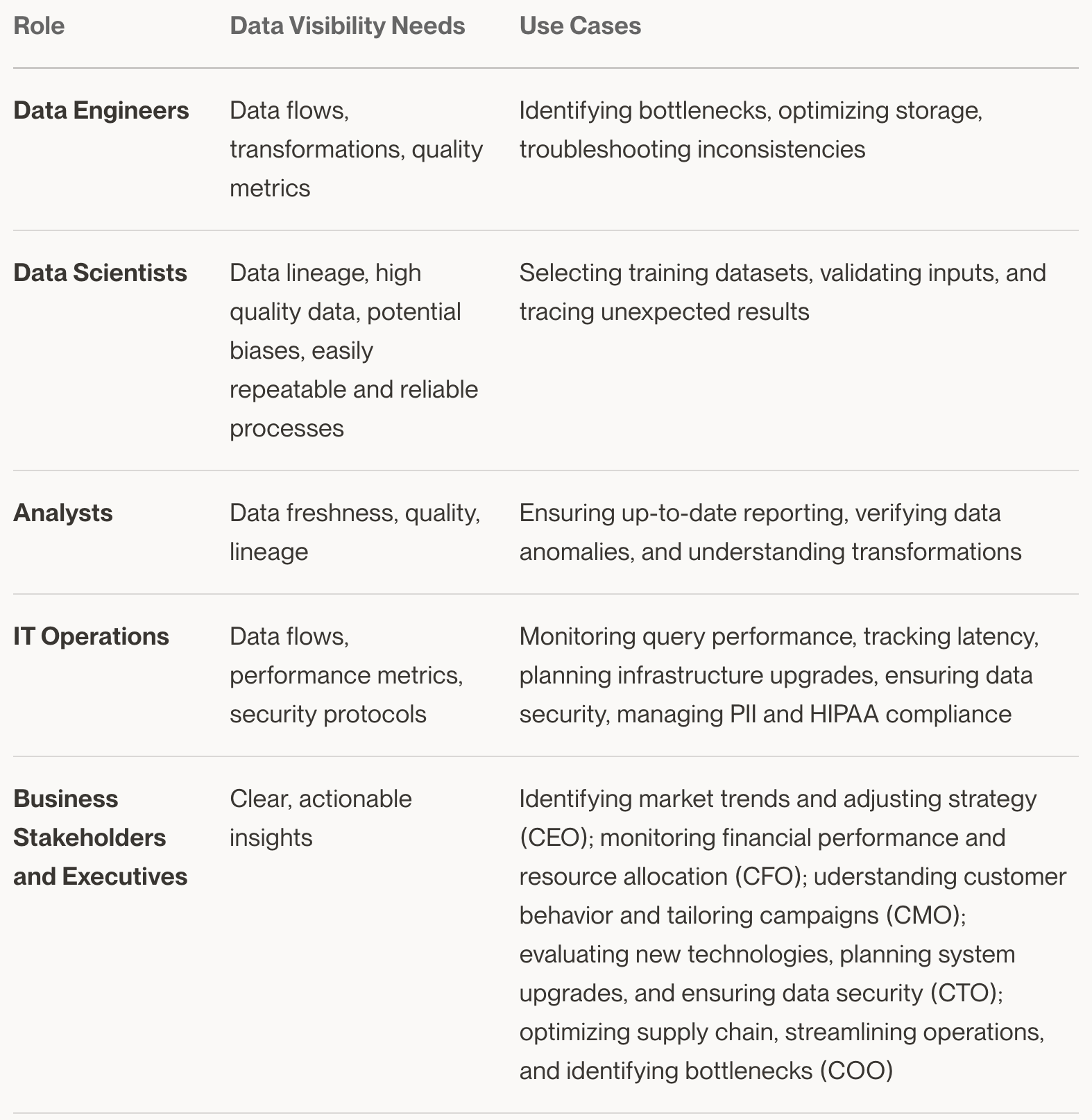
Here are some specific needs and use cases for different roles within an organization:
Organizations that can quantify and improve their overall data visibility will have better data management and decision-making. Those that don’t will be in for a wild ride of risks and consequences.
The Risks of Poor Data Visibility
Running without data visibility will get you into multimillion dollar mistakes and reputation shattering incidents– and that’s not even including the legal implications. Here are some high profile data incidents across different industries:
- Operational Risks: Increased likelihood of data errors and inefficiencies in processes. For example, in 2012, Knight Capital lost $440 million in just 45 minutes due to a trading error caused by outdated code. (SEC Press Release)
- Flawed Decision Making: Decisions based on incomplete or inaccurate data can lead to disastrous outcomes. In 2013, the JCPenney rebranding strategy failed and cost $985 million and their CEO’s job. This decision was based on incomplete customer data and misinterpreted market trends. (Forbes article)
- Loss of Stakeholder Trust: Reduced confidence in the organization's data management capabilities. In 2012, JPMorgan Chase lost $6.2 billion in the "London Whale" incident. This was partly due to poor visibility into their risk models and trading positions, which led to inaccurate risk assessments. The incident resulted in loss of trust from investors, regulators, and the public, damaged the bank's reputation, and led to increased regulatory scrutiny. (SEC Press Release)
- Financial Impact: Revenue loss due to missed opportunities or data-related errors. In 2016, Meta (then Facebook) overestimated video view times by 60-80% for two years, resulting in misallocated advertising budgets and damaged client relationships. (Wall Street Journal article)
- Compliance Issues: Failure to meet regulatory requirements and maintain data integrity. In 2020, Morgan Stanley was fined $60 million by the U.S. Office of the Comptroller of the Currency for not properly decommissioning data center equipment, potentially exposing customer data. (OCC News Release)
- Reputational Damage: Long-lasting negative impact on brand image. Uber's 2016 data breach cover-up affecting 57 million users resulted in widespread criticism and loss of consumer confidence. (FTC Press Release)
What would happen to your business if your key data became unavailable or unreliable? How would these scenarios impact your and your company? Frustrated and less productive developers who leave? Loss of customer and partner trust? Falling behind other competitors because you can’t develop new services or data products?
The point is clear: the consequences of poor data visibility and not having reliable data management will touch every part of your business, from the C-suite to the frontline employees.
To avoid these shockwaves and minimize the risks, you need to take a proactive approach to data visibility.
Data Visibility Best Practices
Most data visibility issues happen when data teams build individual data processes and data pipelines without considering the company’s long-term data strategy. To get efficiencies in data management – including data observability and tracking – you need to have a long-term that will ensure data consistency and incorporate best practices around data lineage, security, governance, versioning, and metadata management.
Having a solid data platform is key to having visibility across your company and avoiding the above consequences. This platform should be open to everyone in the company but with access controls in place.

By making your data platform open and secure, you give teams the information they need while protecting sensitive data.
Tip: Check out this deep dive on building reliable data platforms to understand what else contributes to an A1 data platform.
Dagster and Data Visibility
Dagster is a data orchestration platform born out of the real-world problems data professionals face and built by some of the best and brightest data engineers who have experienced those problems firsthand. It solves the pain points many have experienced with data visibility and is your partner as you tackle the data visibility and resulting data quality problems we all know too well.
Here's how Dagster does data visibility:
Data Lineage and Traceability
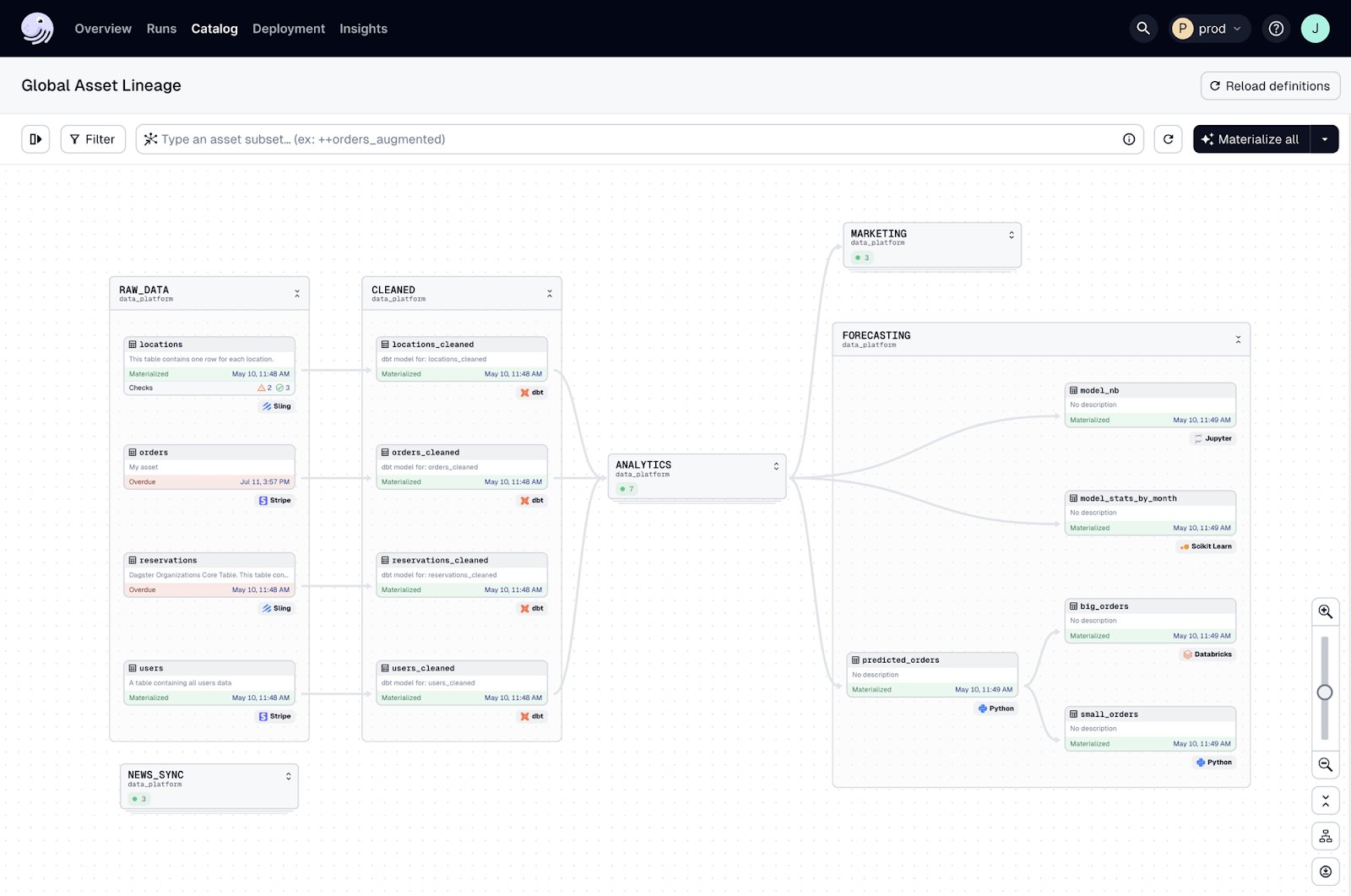
No one wants to relive the pain of trying to trace data through complex data pipelines.
Dagster has full data lineage tracking so you can trace data from its source to its final form. This lineage tracking helps you understand how data is transformed and used across your pipeline and is required for compliance, auditing and impact analysis. Monitoring data values throughout the lineage process gives you data integrity and data reliability. Dagster’s data catalog is a central place to document and explore your data assets so you can understand the relationships and dependencies in your data ecosystem.
Monitoring and Quality Assurance
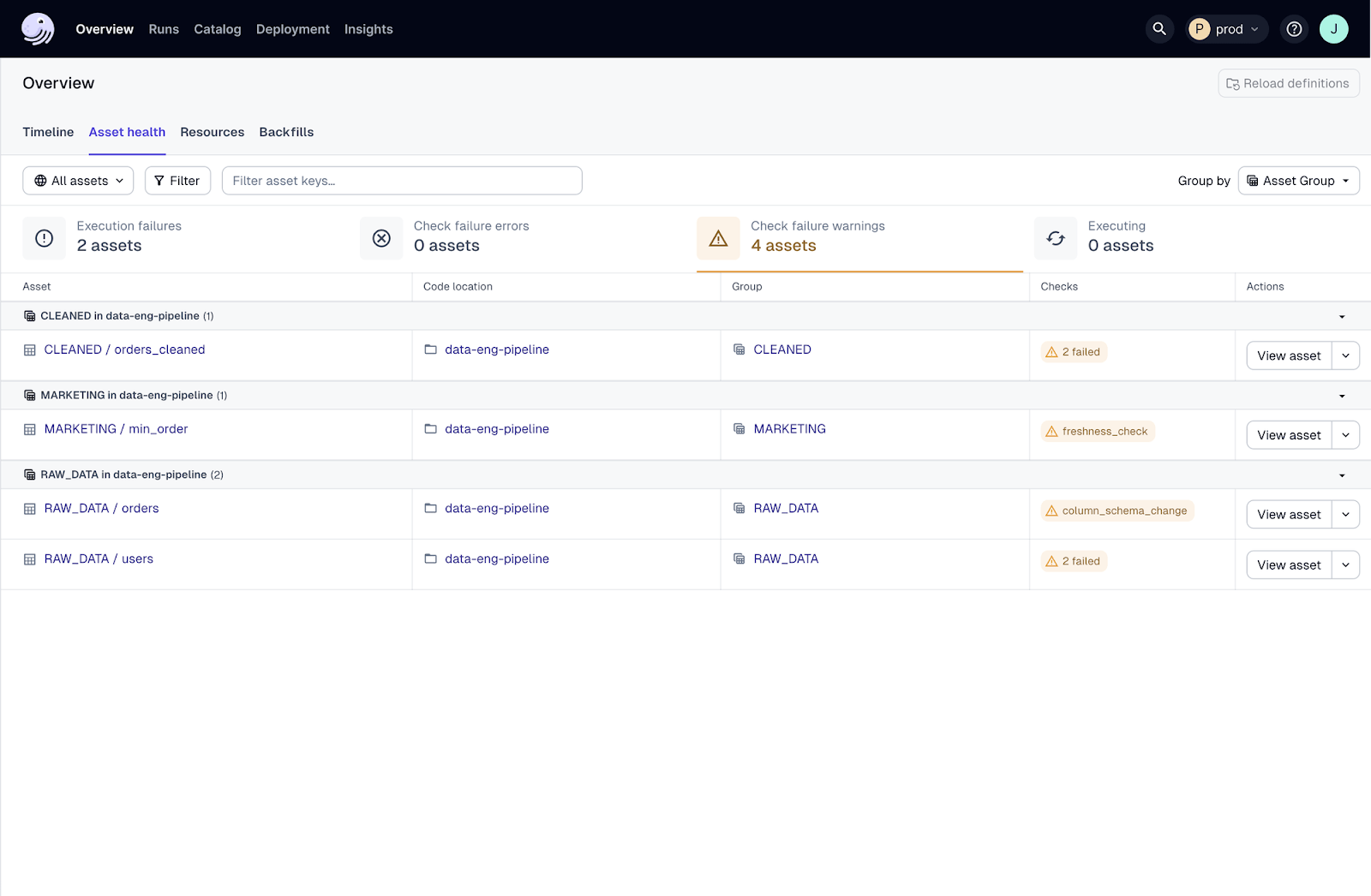
Trying to fix data issues after they’ve already caused problems can be a real PITA.
Dagster has real-time monitoring to ensure data health, quality and performance. You can define data quality checks using built-in and custom validations, freshness policies and alerting systems so you can catch and fix data quality issues quickly. These features let you proactively catch and address data issues for quality standards and data reliability.
Dagster also has automated data pipeline testing which means continuous validation and verification of data integrity throughout the data pipeline itself.
Access Control and Security
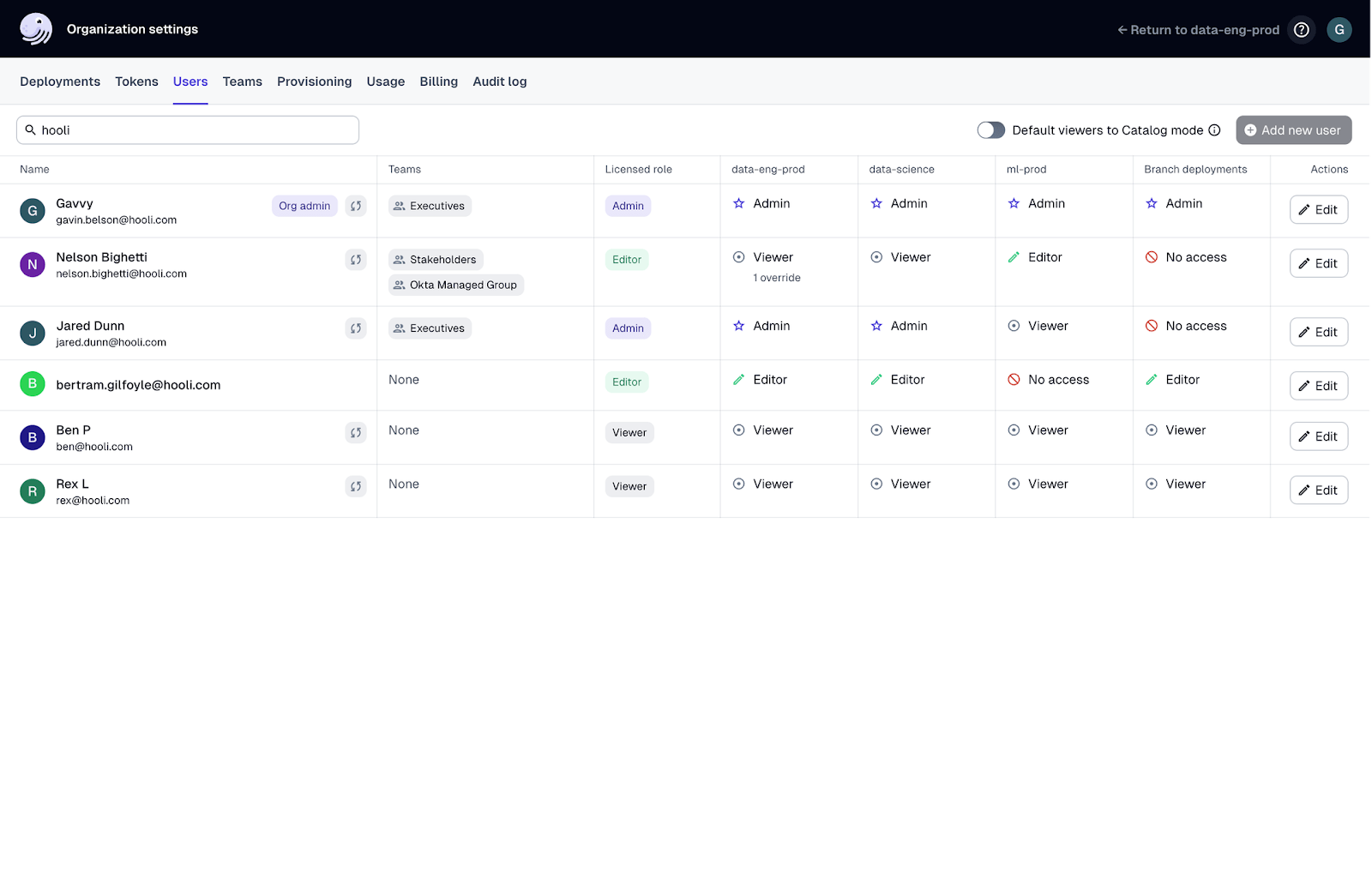
You shouldn’t be losing sleep over security concerns. No one should.
Dagster provides access transparency through detailed audit trails and role-based access control (RBAC). RBAC ensures only authorized people can access and manipulate data so you can support security and compliance efforts.
Tip: Read more about our general security here or about our BCBS 239 compliance here.
Operational Efficiency
Tired of delays and bottlenecks? So were our engineers.
Dagster’s orchestration capabilities simplify data operations, eliminating delays, data downtime, and bottlenecks. Its pipeline management and sensors ensure execution and data freshness.
Collaboration and Governance

No one likes to work with siloed teams and inconsistent data governance.
That’s why Dagster provides a collaborative environment and strong data governance through its single control plane and full metadata management. So teams can collaborate, maintain data quality and support better decision making.
Choose Dagster on Your Data Visibility Quest
Implementing Dagster isn’t just a platform – it’s you choosing to benefit from years of data science and engineering experience and knowledge. It’s you building a data platform with best practices baked in so you can have better data visibility and more firepower in your data management arsenal. Its lineage tracking, real-time monitoring, access transparency and operational efficiency means your data is always reliable, accurate and compliant.
Most importantly, it’s you choosing a reliable partner in us as you tackle the data visibility challenges we all know so well and join us in our mission to raise data management standards and practices across the industry.
Final Thoughts
Data visibility isn’t just a technical requirement; it’s your superpower that gives you the (spidey) senses to propel your business to success (wall crawling, web-swinging and invitation to The Avengers not included). By improving data quality, operational efficiency, security and decision making you’re not just avoiding risks – you’re unlocking growth and innovation.
Dagster is your tool in this journey to get the data insights and levels of data visibility your business needs.
You don’t have to take our word for it though – try Dagster and see for yourself how it can change your data management and visibility game.
Remember, with data, visibility isn’t just a plus – it’s your key to moving the needle in your business. Whatever you do, make sure you can see your data and watch your business take off.





.jpg)
.png)



.png)

