




The foundation of a solid Python project is mastering modules, packages and imports.
The following article is part of a series on Python for data engineering aimed at helping data engineers, data scientists, data analysts, Machine Learning engineers, or others who are new to Python master the basics. To date this beginners guide consists of:
- Part 1: Python Packages: a Primer for Data People (part 1 of 2), explored the basics of Python modules, Python packages and how to import modules into your own projects.
- Part 2: Python Packages: a Primer for Data People (part 2 of 2), covered dependency management and virtual environments.
- Part 3: Best Practices in Structuring Python Projects, covered 9 best practices and examples on structuring your projects.
- Part 4: From Python Projects to Dagster Pipelines, we explore setting up a Dagster project, and the key concept of Data Assets.
- Part 5: Environment Variables in Python, we cover the importance of environment variables and how to use them.
- Part 6: Type Hinting, or how type hints reduce errors.
- Part 7: Factory Patterns, or learning design patterns, which are reusable solutions to common problems in software design.
- Part 8: Write-Audit-Publish in data pipelines a design pattern frequently used in ETL to ensure data quality and reliability.
- Part 9: CI/CD and Data Pipeline Automation (with Git), learn to automate data pipelines and deployments with Git.
- Part 10: High-performance Python for Data Engineering, learn how to code data pipelines in Python for performance.
- Part 11: Breaking Packages in Python, in which we explore the sharp edges of Python’s system of imports, modules, and packages.
Sign up for our newsletter to get all the updates! And if you enjoyed this guide check out our data engineering glossary, complete with Python code examples.
Dagster runs on Python, and most data engineers or developers with a basic grasp of Python can get simple pipelines up and running rapidly. But some users who are less familiar with Python find Python packages to be a bit of a headache.
So let’s talk about what Python packages are and how to use them. We’ll cover specific topics that will help you understand what’s involved in structuring a Python project, and how this translates to more complex builds such as data pipelines and orchestrators. In later articles we will see how these concepts apply to Dagster.
If you’ve only worked on existing codebases or a Jupyter notebook, it can be pretty overwhelming to package code from scratch. What is an __init__.py file and when should you use it? What are relative vs. absolute imports? Let’s dive in!
Table of Contents
- What are Python packages?
- Starting with modules
- From modules to packages
- What is __init__.py?
- How do you manage packages in Python?
- How does pip work?
- What are relative vs. absolute imports?
What are Python packages?
We put our Python code into packages as it makes it easy to share and reuse code in the Python community. A package is simply a collection of files and directories that include the code, documentation, and other necessary files that we will examine later.
We use Python packages instead of script files and Jupyter notebooks when we want to reuse complex code. With script files, code can become cluttered and difficult to maintain, while notebooks are often used for exploratory work but are not easily reusable.
You can think of a Python package as a standalone “project”. A project can contain multiple modules, each of which contains a specific set of related functions and variables. Hence, this makes it easier for you to embed tools from “projects” you need within your own code.
Starting with modules
Modules are the building blocks of Python packages. A module is a single Python file that contains definitions and statements. They provide a way to structure your code into logical units and reuse code across multiple projects.

To use a module in your code, you use the import statement. For example, if you have a module called mymodule.py , you can use its functions and variables in your code with the following import statement:
import mymoduleOnce you have imported a module, you can access its functions and variables using the dot (.) notation. For example, if the mymodule.py file has a function called greet, you can use it in your code as follows:
import mymodule
mymodule.greet("John")
Let's create our own example module to illustrate the concept. Create a file called examplemodule.py and add the following code to it:
def greet(name):
print("Hello, " + name + "!")
def add(a, b):
return a + bHere, we defined two functions, greet and add , in the examplemodule.py file. These functions can now be imported and used in other parts of your code.
From modules to packages
As your code grows, it can become difficult to manage and maintain all the code in a single module. Packages provide a way to organize and split your code into multiple modules, while still keeping everything organized and accessible.
To create a package, simply create a directory and place one or more modules in it. The directory should contain a special file called __init__.py , which tells Python that this directory is a package and should be treated as such. The __init__.py file can be left empty or it can contain code that will be executed when the package is imported. We explain __init__.py files in more detail below.
Let's refactor the example module from the previous section to be a package. Create a directory called examplepackage and move the examplemodule.py file into it. Then, create a file called __init__.py in the examplepackage directory.
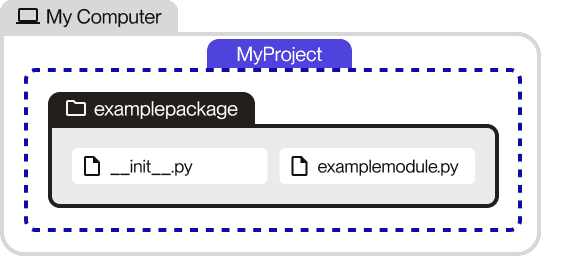
Your file structure should now look like this:
examplepackage/
__init__.py
examplemodule.pyYou can now import the functions from the examplemodule.py file in your code as follows:
import examplepackage.examplemodule
examplepackage.examplemodule.greet("John")
examplepackage.examplemodule.add(1, 2)
In this example, we have refactored the examplemodule.py file into a package called examplepackage. The functions from the examplemodule.py file can now be imported and used in your code as before, but with the added benefits of organization and modularity provided by packages.
What is __init__.py?
__init__.py is a special file in Python packages that serves as an entry point for the package. It is executed when the package is imported, and its code can be used to initialize the package or set up any necessary components. The file is optional, but is often used to define the public interface of the package, making it easier for other developers to understand and use the package.
In previous versions of Python, __init__.py was required for a directory to be recognized as a package. However, as of Python 3.3, __init__.py is optional due to the introduction of PEP 420, which allows for packages to be defined without an __init__.py file.
Here's an example of how you could use __init__.py in a package:
### examplepackage/__init__.py
from .examplemodule import greet, add
__all__ = [
'greet',
'add',
]
In this example, the __init__.py file imports the greet and add functions from the examplemodule.py file and makes them part of the public interface of the package. The __all__ variable is used to define the public interface of the package, and makes it easier for other developers to understand and use the package.
With this setup, you can now import the greet and add functions from the examplepackage as follows:
import examplepackage
examplepackage.greet("John")
examplepackage.add(1, 2)
How do you manage packages in Python?
The most common way developers distribute their packages is by uploading them to a public repository called the Python Package Index (PyPI). We use a system called pip which stands for "Pip Installs Packages". It is a command-line tool that allows users to install and manage packages from PyPI and other package indexes.
If you’ve used pip install, you have downloaded and installed a package through the Python Package Index (PyPI).
Package management systems like pip make it easy to install, update, and remove packages, as well as manage dependencies (packages that are required for other packages to function properly) in a project.
How does pip work?
pip install is the command we use to download and install different packages from a library called PyPI or even from your own computer. When you run this command, it will check if the package is available on PyPI and if so, it will download and install it on your computer. In addition, it will check on - and if needed install - all the dependencies listed in the package metadata. Finally, pip will keep track of all the packages you install to help you upgrade or uninstall them later.
By default, pip install installs the latest version of the package, but you can choose to install a specific version if you need to by using pip install <PACKAGE>==<VERSION>, so for example you might use pip install numpy==1.23.5. This can be helpful if you're having trouble with your code and need to use a specific version of a package.
Have you ever noticed that when you use pip install to add a feature to your Python code, the name you use to install it is different from the name you use when you import it? This happens because there are two types of names:- the distribution name, which is the name you use to install the package using pip install- the package name, which is the name you use when you import the package in your code.
The distribution name is unique and guaranteed to be different from other package names by PyPI, the library where you get your packages from. On the other hand, the package name is chosen by the person who created the package, so it may not be unique.
This is why you might install a package called "dagster-dbt" using pip install, but import it in your code using the name "dagster_dbt". This is also why you might install a package called "scikit-learn" using pip install, but import it in your code using the name "sklearn".
What are relative vs. absolute imports?
When writing a package, there may be times when we want to use relative imports. Relative imports consist of either explicit or implicit imports, but you really only need to know about explicit relative imports as implicit relative imports are not supported in Python 3.
Relative imports allow you to import modules relative to the current module. They use the keyword "from" followed by the name of the current package and the name of the module or package being imported. For example, if you have a package named examplepackage with two modules, module1.py and module2.py, you can import the code from module1.py into module2.py using a relative import as follows:
### examplepackage/module2.py
from .module1 import greeting
def greet(name):
print(greeting + " " + name)
Here, the relative import from .module1 import greeting is used to import the greeting variable from the module1.py file into the module2.py file. The . before module1 indicates that the import should be relative to the current module.
Absolute imports allow you to import modules using their full name, regardless of their location relative to the current module. They use the the full path of the module or package being imported. For example, you could use an absolute import to access the greeting variable from the module1.py file into the module2.py file as follows:
### examplepackage/module2.py
from examplepackage.module1 import greeting
def greet(name):
print(greeting + " " + name)
Here, the absolute import from examplepackage.module1 import greeting is used to import the greeting variable from the module1.py file into the module2.py file. The full name of the module, examplepackage.module1, is used to specify the location of the module.
In Python 3, relative imports must be explicit and the absolute imports are the default behavior.
Up next…
We hope this blog post has provided a useful introduction to Python packages and how to manage dependencies effectively. If you have any questions or need further clarification, feel free to join the Dagster Slack and ask the community for help. Thank you for reading!
Our next article (Part 2 of this series) will dive into Python dependency management and how and when you should use virtual environments.





.jpg)
.png)



.png)

