




We look at the write-audit-publish software design pattern used in ETL to ensure quality and reliability in data engineering workflows.
The following article is part of a series on Python for data engineering aimed at helping data engineers, data scientists, data analysts, Machine Learning engineers, or others who are new to Python master the basics. To date this beginners guide consists of:
- Part 1: Python Packages: a Primer for Data People (part 1 of 2), explored the basics of Python modules, Python packages and how to import modules into your own projects.
- Part 2: Python Packages: a Primer for Data People (part 2 of 2), covered dependency management and virtual environments.
- Part 3: Best Practices in Structuring Python Projects, covered 9 best practices and examples on structuring your projects.
- Part 4: From Python Projects to Dagster Pipelines, we explore setting up a Dagster project, and the key concept of Data Assets.
- Part 5: Environment Variables in Python, we cover the importance of environment variables and how to use them.
- Part 6: Type Hinting, or how type hints reduce errors.
- Part 7: Factory Patterns, or learning design patterns, which are reusable solutions to common problems in software design.
- Part 8: Write-Audit-Publish in data pipelines a design pattern frequently used in ETL to ensure data quality and reliability.
- Part 9: CI/CD and Data Pipeline Automation (with Git), learn to automate data pipelines and deployments with Git.
- Part 10: High-performance Python for Data Engineering, learn how to code data pipelines in Python for performance.
- Part 11: Breaking Packages in Python, in which we explore the sharp edges of Python’s system of imports, modules, and packages.
Sign up for our newsletter to get all the updates! And if you enjoyed this guide check out our data engineering glossary, complete with Python code examples.
Data engineering is as much about the methodologies and data pipeline design patterns as it is about the tools and technologies. In this series, you've learned about proven development paradigms in data engineering and how to build more robust and scalable software through factory patterns.
Today, we’ll look at write-audit-publish, a design pattern used in software engineering when moving data. It addresses the particular problem of data integrity by staging, validating, and then committing data to production in large-scale operations.
What is Write-Audit-Publish? A definition in data engineeringWrite-Audit-Publish (WAP) is one of several key design patterns in data engineering that emphasize data quality and integrity, especially within data orchestration workflows. It works in three stages:1. writing data to a non-production environment,2. auditing this data to identify and rectify quality issues3. publishing data to production.Data developers use write-audit-publish with data orchestration tools to automate and monitor quality control processes throughout the data pipeline.
WAPs have proven integral to improving data quality. We’ll look at how WAP design patterns ensure accuracy, consistency, and trustworthiness throughout data flows. We’ll also explore examples of how write-audit-publish can be used in two real-world scenarios: batch processing and streaming real-time data.
Table of contents
- Software design patterns explained
- What is write-audit-publish?
- The key benefits of write-audit-publish
- The write-audit-publish workflow
- Data orchestration & write-audit-publish
- Write-audit-publish in data pipeline design patterns
- Conclusion
Software design patterns explained
In part seven of our series, we discussed how design patterns are standard solutions to common problems that occur in software design. They represent best practices and are templates that can be used in multiple situations to solve particular problems and improve code readability.
We’ve discussed how data developers use factory patterns for everyday tasks like batch processing or building real-time data streams and ETL pipelines. Similar patterns can be used in moving data, managing data changes, or other computer science steps.
In this post, we’ll tackle another pattern that’s an example of a structured approach to ensuring data quality and reliability. But how does this process translate into the hands-on, code-driven world of a data engineer?
What is write-audit-publish?
Write-audit-publish is also a type of software design pattern:
At its core, the WAP pattern operates on a principle of commitment: data is first written to a staging area, subjected to rigorous quality checks, and only upon validation is it transitioned to the production environment.
You can think of this design pattern as a gatekeeper, ensuring that only the most reliable and vetted data makes its way to the forefront. This approach not only safeguards data integrity but also fortifies the trust stakeholders place in your data systems.
The key benefits of write-audit-publish patterns
Adopting WAP design patterns in data pipelines yields several substantial benefits:
Enhanced Data Integrity and Quality
WAP patterns ensure that the data is of high quality and integrity. The audit phase (described below) scrutinizes the data for accuracy, completeness, and adherence to predetermined standards, rectifying any discrepancies or anomalies, which guarantees that only validated and reliable data sources are published to production.
Increased Data Security
The structured approach of WAP provides a security layer by isolating raw and audited data, protecting sensitive and unvalidated information from premature exposure, which is critical in maintaining data compliance and security standards in various industries.
Improved Reliability
The segregation of writing, auditing, and publishing phases allows for superior error handling and recovery mechanisms. This distinct separation facilitates the easy identification and amendment of issues at each stage, bolstering the overall reliability and stability of the data pipeline.
Operational Flexibility and Scalability
The modular architecture inherent to WAP patterns provides the flexibility to modify, upgrade, or scale individual components independently, allowing the system to adapt to evolving requirements without compromising the entire pipeline’s stability.
Other benefits, as discussed earlier, include:
- Optimized Data Flow Management
- Boosted Operational Efficiency
- Enhanced Trust and Compliance
The write-audit-publish workflow
Let’s turn to the WAP workflow.
At the beginning of the process, our schedule triggers a run, or our data pipeline sensor lets the system know a change has occurred in our data source (as raw data in a file or in a data warehouse, or the product of other data pipelines). At this stage, we do not know the quality of the data, so we will consider it untrustworthy. Meanwhile, users access production data via a BI tool.

1. Write

In the "Write" phase, data is either ingested from various sources—like a data warehouse, APIs, or streaming platforms—or transformed from existing datasets using tools like Apache Spark or Apache Kafka. This data is then "written" to a designated location, typically known as a staging area or a log. Imagine this as the initial draft of a report, where raw data is collected and preliminary transformations are applied, such as aggregations, filtering, or joining datasets.
2. Audit

Once the data lands in the staging area, it's time for a rigorous quality check. In this "Audit" phase, a good software design technique is to employ a series of predefined rules or conditions to ensure the data's integrity. It's similar to a detailed review of a draft, where every line and figure is scrutinized.
For instance, data engineers might use Python scripts to:
- Validate the data's structure (schema) against expected definitions.
- Use statistical methods for anomaly detection to spot outliers or unexpected patterns.
- Ensure there are no duplicate records, missing values, or misformatted entries.
- Validate that data adheres to business rules, such as a product's price never being negative or a user's age being within a reasonable range.
3. Publish
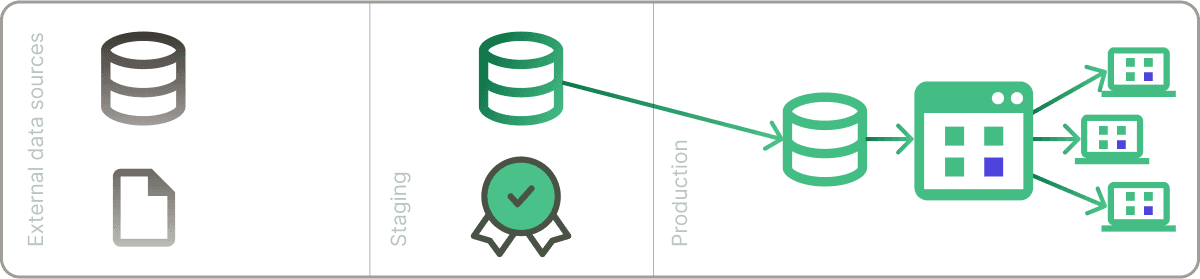
After you're confident that your data processing is complete and your data is clean and accurate, you "publish" it. This means moving the data from the staging area to its final destination, where it'll be used for analysis, reports in a BI tool, or other tasks.
Here, we can use ETL or ELT tools, like Dagster, to move the vetted data from the staging area to its final destination—be it a data warehouse like Snowflake or BigQuery, or a data lake. This polished data is then ready for in-depth analysis, powering dashboards, generating reports, or feeding machine learning models.
However, if the data doesn't pass the audit, the data pipeline can halt the process or trigger a warning mechanism, much like a safety switch that stops things when something's not right.
Data orchestration & write-audit-publish
These three steps in software development act as a rigorous quality control mechanism, ensuring that the data being processed is both accurate and trustworthy.
WAP is especially relevant in the context of data orchestration. Data pipeline tools such as Dagster are designed to automate, schedule, and monitor data workflows. These tools allow for the creation of complex workflows by chaining together multiple tasks in a directed acyclic graph (DAG) structure.
There are many reasons why WAP and data orchestration go hand in hand:
- Complex Data Pipelines: Data workflows often involve multiple steps, from data extraction to transformation and loading. The WAP pattern can be naturally integrated into these workflows, ensuring that each step is validated before moving on to the next.
- Automated Quality Checks: Orchestration tools allow for the automation of the audit phase. For instance, after writing data to a staging area, an automated quality check task can be triggered. If the data fails the check, the workflow can be halted, or other corrective tasks can be initiated.
- Dependency Management: Using DAGs, orchestration tools ensure that the "Audit" phase only begins after the "Write" phase completes successfully, and the "Publish" phase starts only after a successful "Audit". This sequential and dependent execution in the data pipeline ensures data integrity.
- Alerts and Monitoring: If data fails the audit phase, orchestration tools can send alerts to data engineers or other data consumers. This immediate feedback loop ensures that issues are addressed promptly, improving business agility.
- Reusability and Scalability: With orchestration tools, the WAP pattern can be templated and reused across different datasets or workflows. This ensures consistent data quality checks across the board.
Write-audit-publish in data pipeline design patterns
Knowing and implementing WAP can be the difference between routinely delivering pristine data and occasionally letting errors slip through, making it an invaluable tool in a data engineer's toolkit.
In real-world scenarios, the complexity would scale based on the data set, the event data volume, variety, and specific requirements of the data engineering pipeline.
Let’s take a look at two examples: batch processing data and streaming real-time data.
Batch data pipelines with write-audit-publish
Imagine you’re the data engineer responsible for processing sales historical data from multiple sources, merging them, and then storing the results in DuckDB. You are likely also to include data cleansing, data transformation, and other patterns in your data pipeline. How would you implement the WAP framework?
Write: Read sales data from multiple CSV files and combine them into a single DataFrame.
import pandas as pd
import glob
import duckdb
### Collect all CSV files in the directory
files = glob.glob('sales_data_*.csv')
### Buffer to temporarily store data from each file
data_frames = []
for file in files:
df = pd.read_csv(file)
data_frames.append(df)
### Combine all data into a single DataFrame
combined_data = pd.concat(data_frames, ignore_index=True)
Audit: To audit our data, we’ll have to check for missing values in the 'sales_amount' column and ensure that no sales amount is negative.
### Filter out rows with missing 'sales_amount'
clean_data = combined_data.dropna(subset=['sales_amount'])
### Filter out rows with negative 'sales_amount'
clean_data = clean_data[clean_data['sales_amount'] >= 0]
Publish: Finally, we can store the transformed sales data in a DuckDB table.
### Connect to DuckDB
conn = duckdb.connect(database=':memory:', read_only=False)
if not clean_data.empty:
clean_data.to_sql('cleaned_sales_data', conn, if_exists='replace', index=False)
print(f"Inserted {len(clean_data)} rows into DuckDB.")
else:
print("No data passed the audit.")
This kind of batch processing is common in scenarios where data is collected periodically (e.g., end-of-day sales reports) and then processed in chunks. It can equally be applied to micro batch processing where data latency needs to be reduced. The WAP process ensures that the data is consolidated, cleaned, and then stored in a structured database, ready for further analysis or reporting.
Stream real-time data with write-audit-publish
We’ll demonstrate how to handle streaming data, a particular scenario that is a bit different from the traditional batch processing methods. Streaming data is continuous, and the WAP process needs to be efficient enough to handle data in near real-time. In our tutorial here, we’ll simulate a data stream using randomly generated sales data.
Write: We’ll first generate random sales data and store them in a temporary buffer.
import pandas as pd
import duckdb
import random
from time import sleep
### Function to generate random sales data
def generate_sales_data():
return {
'product_id': random.randint(1, 100),
'sales_amount': random.uniform(10.5, 500.5),
'timestamp': pd.Timestamp.now()
}
### Buffer to temporarily store sales data
sales_buffer = []
### Simulate streaming by generating data every second
for _ in range(100): # Generate 100 data points
sales_data = generate_sales_data()
sales_buffer.append(sales_data)
sleep(1)
Audit: We’ll then check if the sales amount is within a reasonable range (e.g., between 10 and 500).
df = pd.DataFrame(sales_buffer)
### Filter out rows with sales_amount outside the range
clean_data = df[(df['sales_amount'] >= 10) & (df['sales_amount'] <= 500)]Publish: If our audit is successful, we’ll store the cleaned sales data in a DuckDB table.
### Connect to DuckDB
conn = duckdb.connect(database=':memory:', read_only=False)
if not clean_data.empty:
clean_data.to_sql('cleaned_sales_data', conn, if_exists='replace', index=False)
print(f"Inserted {len(clean_data)} rows into DuckDB.")
else:
print("No data passed the audit.")
Conclusion
The WAP pattern, when combined with a data orchestration tool like Dagster, provides a robust framework for ensuring data quality in automated and complex data pipelines. Learning these common patterns (such as the factory method we explored in a previous post) will help improve your overall data pipeline and data architecture components, including data integration, data warehousing, CDC technology, etc. Furthermore, reusing design patterns helps speed up your development process.
Our next chapter in the guide explores automating data pipeline workflows with CI/CD.





.jpg)
.png)



.png)

