




Learn how to use data engineering patterns and Dagster’s dynamic partitioning to build an outbound email report delivery pipeline.
Sending email reports with custom, user-specific charts is an easy-sounding, backend engineering task that inevitably becomes a nightmare to maintain. Solutions typically involve cron jobs or manually configured queues and workers, which are brittle, hard to test, and even harder to fix when they fail.
Of course, it doesn’t have to be this way. Data engineering patterns map cleanly to orchestrating user emails and make these straightforward to build.
So today, we’re using Dagster—along with DuckDB, Pandas, Matplotlib and Seaborn—to build an almost production-ready email pipeline. More specifically, we’ll build a monthly revenue report email for hosts of MyVacation, a pretend Airbnb-like company, and tap into Dagster's powerful partitioning features.
What we’re building
Want to skip right to the code? It’s all on GitHub.
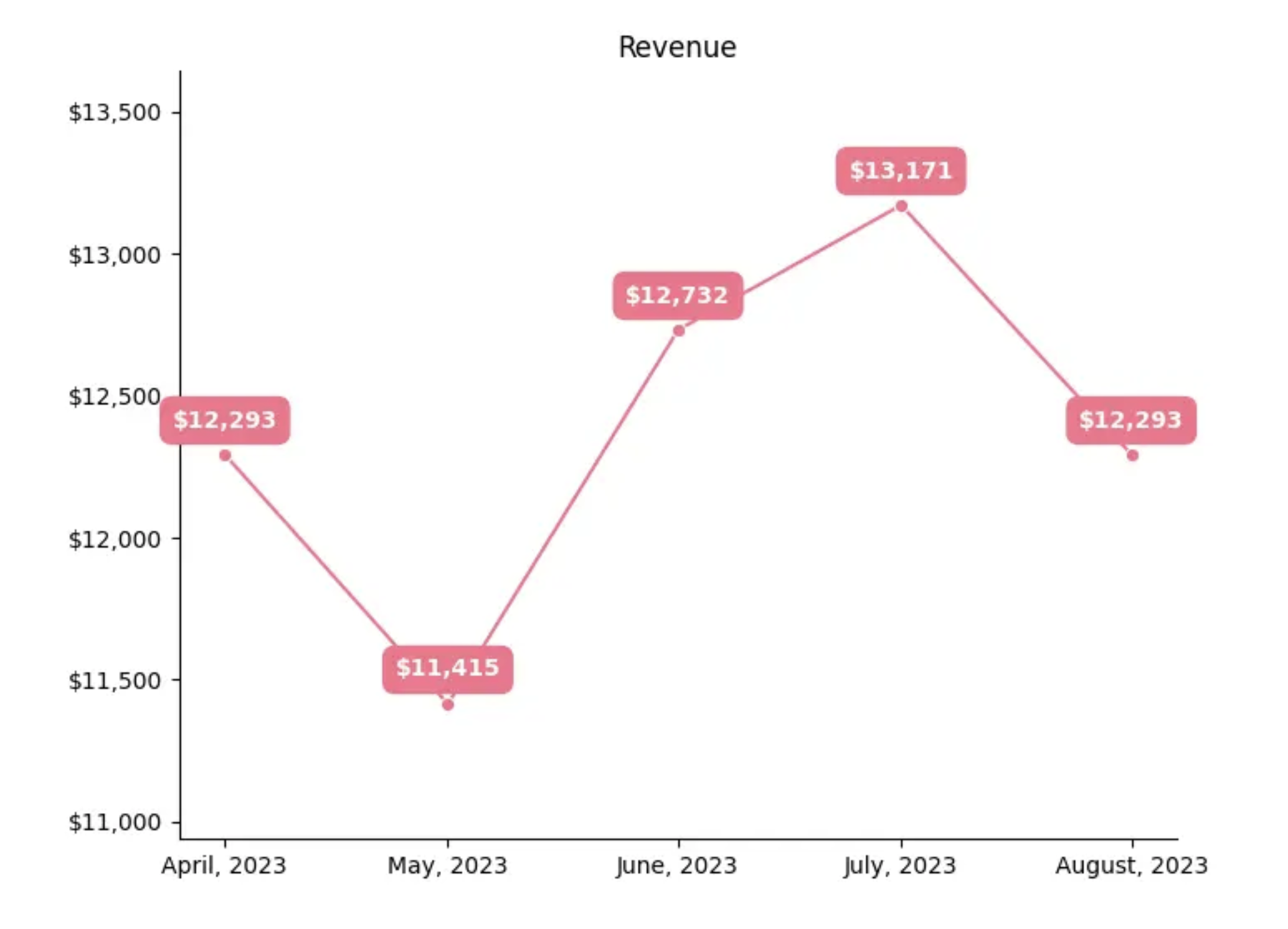
We’re building a tiny version of an email report delivery pipeline. It will calculate an owner’s monthly revenue numbers and create an image containing a line chart with their historical revenue data. This information will then be emailed to the property owners. We’ll work with partition mappings to segment data and resources to connect to remote services. The chart will look like this:
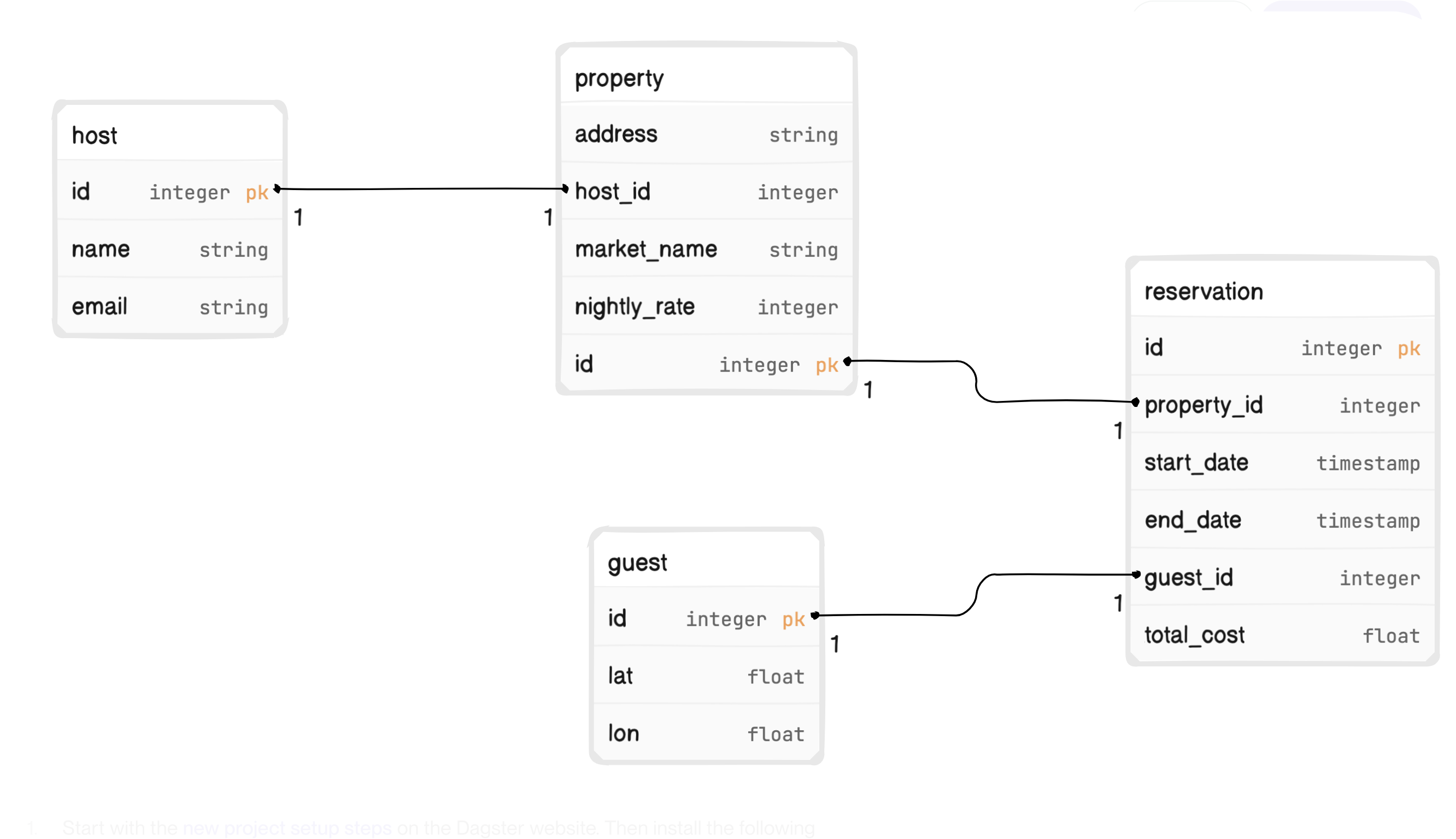
MyVacation is unique in that its application database has only four tables, all of which are necessary for sending a monthly property revenue email.
In our model, guests make reservations at properties which hosts own. Conveniently, all columns are also relevant to the monthly property report email.
Setup
If you’d like to follow along:
- Start with the new project setup steps on the Dagster website. Then install the following packages:
- Install dependencies -
pip install dagster-duckdb~=0.20 dagster-duckdb-pandas~=0.20 seaborn~=0.12 Faker~=19.2 geopy~=2.3 - Go to the project’s GitHub and copy the database.py file into your local directory. Running that file will create
myvacation.duckdb. We’ll use this as a local application server and back the DuckDB I/O Manager. - If you want to create sample data, copy and execute the
sample_data.pyfile - Configure your I/O Manager
### __init__.py
from dagster_duckdb_pandas import DuckDBPandasIOManager
database_io_manager = DuckDBPandasIOManager(database="myvacation.duckdb", schema="main")
defs = Definitions(
...
resources={
"io_manager": database_io_manager,
...
},Denormalizing Reservation Data
Our first task is combining reservation data with property and guest data to start our analysis, filtering only for reservations completed in the last month.
We’ll use a Partition class to isolate the time range we want to operate on. MonthlyPartitionsDefinition is a predefined partition type that lets us run assets on a month’s worth of reservations. The start and end times for the current partition are available inside the asset’s context object, which we’ll get back to momentarily.
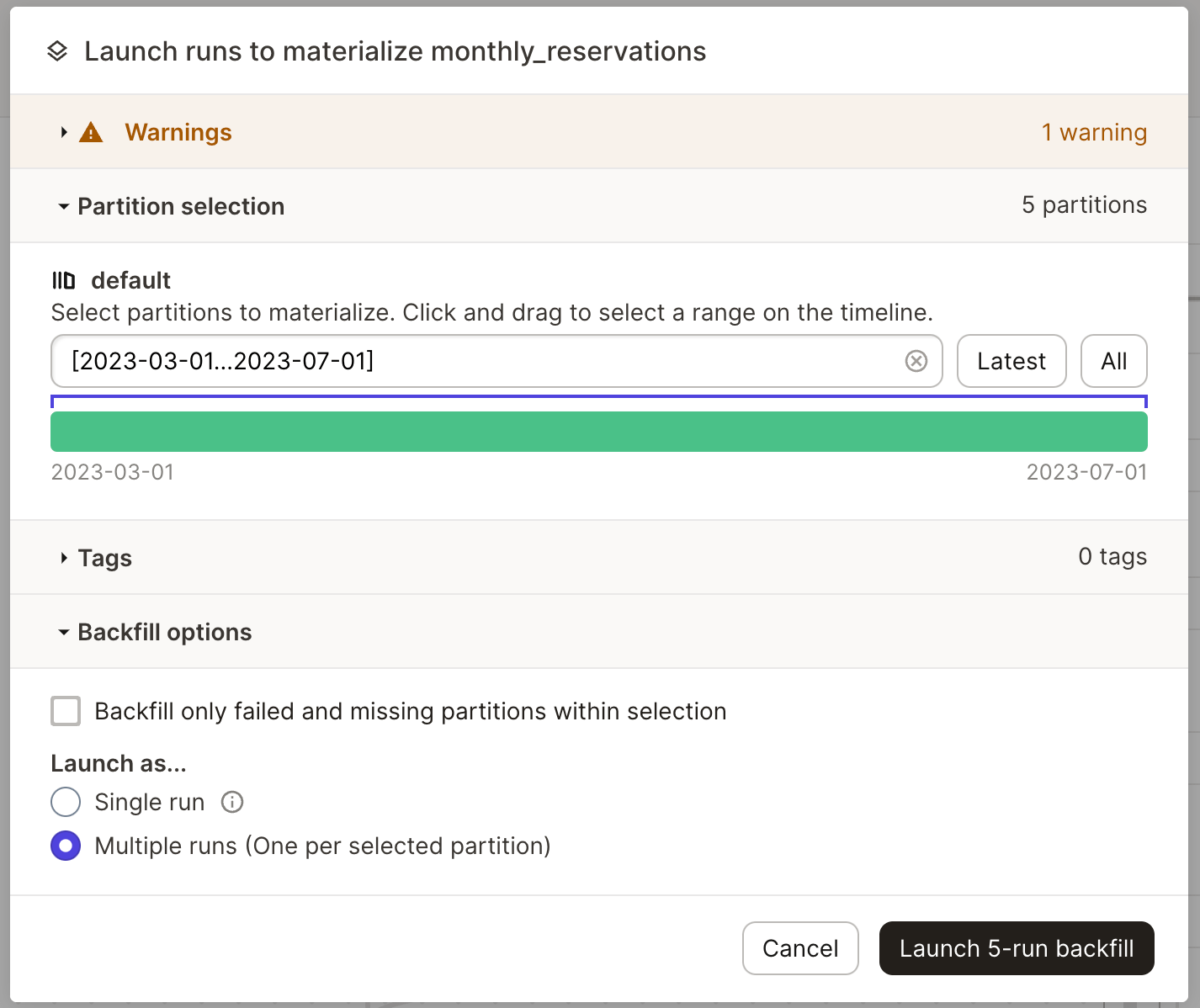
When materializing a partitioned asset in the UI, the available time range is now split up across multiple partitions, where they can be executed individually or in bulk.
Now that our asset has information about the time range, we need to access the database. We could connect directly to a database client, but this approach makes testing and configuration across environments difficult.
Instead, we’ll use another Dagster class to define a configurable database resource that gets passed into our object at runtime.
Database is a simple class that connects to DuckDB and returns a query as a Pandas DataFrame.
To make Database available to our asset, define it as a resource in our project’s Definitions object.
Now if we add database to our function signature, Dagster can pass in our newly created resource.
Why is `from .resources import Database` in two separate files?
Database is imported into `__init__.py` so Dagster has the resource object available to inject into assets. It’s imported into `assets.py` to allow type-checking to take place.
Isn’t this a lot of work just to query DuckDB?
It’s true; you can easily query DuckDB directly from a single asset. But we query the database from other assets, and thanks to resources, we don’t need to duplicate any code.We now have everything we need to query our database for the desired timeframe.
###assets.py
@asset(
partitions_def=monthly_partition_def,
)
def monthly_reservations(
context: AssetExecutionContext, database: Database
) -> pd.DataFrame:
bounds = context.partition_time_window
results = database.query(
f"""
SELECT
r.id,
r.property_id,
r.guest_id,
r.total_cost,
g.lat AS lat_guest,
g.lon AS lon_guest,
p.lon,
p.lat,
p.host_id,
p.market_name
FROM
reservation r
LEFT JOIN
property p ON r.property_id = p.id
LEFT JOIN
guest g ON r.guest_id = g.id
WHERE r.end_date >= '{bounds.start}' AND r.end_date < '{bounds.end}'
"""
)Is a triple join on an application database a good idea?
If the crucial columns aren’t indexed, then definitely not. Otherwise, it depends on how much data you have and the rate of queries through your system. In a later section, we’ll discuss preparing this code for production and what may need to change at scale.
Thanks to our Database resource, the query results are already converted to a DataFrame when they get back our asset. But they aren’t ready to be returned from our asset yet. The magic of assets is that the results are saved (materialized) and available to downstream assets or ops, even if executed at different times. When configuring our io_manager, we told Dagster to save results by default in DuckDB. So when monthly_reservations returns a DataFrame, Dagster adds the results to a monthly_reservations table in the database. When new partitions are executed, the results are added to the same monthly_reservations table.
This raises a DuckDB-specific question. If the next downstream asset, which depends on the monthly_reservations asset, is also partitioned by month, how does Dagster know which records from the monthly_reservations table need to be made available?
The monthly_reservations asset needs to tell Dagster by specifying which column of its output columns should be used for partitioning via the partition_expr metadata value.
We’re adding a new column that indicates the very end of month that the reservations occurred (technically, it is midnight on the start of the next month), and telling Dagster that this value is a reliable way to determine which partition a record belongs to.
Aggregating Monthly Property Results
Next, we need to calculate how much each property makes per month. We won’t go into detail about this asset because, although it’s important to the pipeline, there are no new concepts other than a Pandas aggregate function.
Since property_analytics uses the same monthly partition as monthly_reservations, we’ll pull that into its own monthly_partition_def variable.
Creating a historical income chart
Now that we have our property results, we have enough data to build a bar chart with historical data.
Partitions have built-in support for using multiple upstream partitions to create the current asset, and we’ll use this functionality to grab historical months’ booking revenue. The ins argument of the @asset decorator allows us to customize how specific dependencies’ partitions are mapped. This enables us to specify the start_offset argument of TimeWindowPartitionMapping, which shifts the time window for incoming data from one month (the default) to five. start_offset=-4 indicates that the start time is four steps earlier than the default.
We’re also loading in a LocalFileStorage object, so we need to define that class in resources.py. This class allows us to ensure that a base storage directory exists, along with any subdirectories, before attempting to write a file. setup_for_execution() is a hook that will run when the object is instantiated, so we can be confident the target directory will always exist.
We can now create and save an image file. The specifics of creating the image are outside the scope of this tutorial, but the code is available on GitHub. It uses Seaborn and matplotlib to draw the chart and lives in charts.py, which we’ll need to import.
Most of the method is standard Pandas work. Since the dataset includes multiple months of a single location, we group the property_analytics data by property_id and then sort the subgroup sequentially by the month_end column.
We then take these sorted results and call charts.draw_line_chart, which returns an image as bytes that are saved to a buffer. The raw bytes are then passed to the LocalFileStorage, which saves them as a file at the specified location.
Finally, a new DataFrame is constructed that includes the final month as month_end along with a path to the image file.
Combining charts with host data
At this point we have property data and a dynamically created chart visualizing property performance over the past few months, we just need to decide who to send it all to. The host data still lives in the database, so before we can join the relevant DataFrames, we need to make use of our Database resource once more.
Beyond the database query, this asset merges the three DataFrames based on shared columns.
With this, we’ve successfully built out our assets; let’s look at them in the UI.
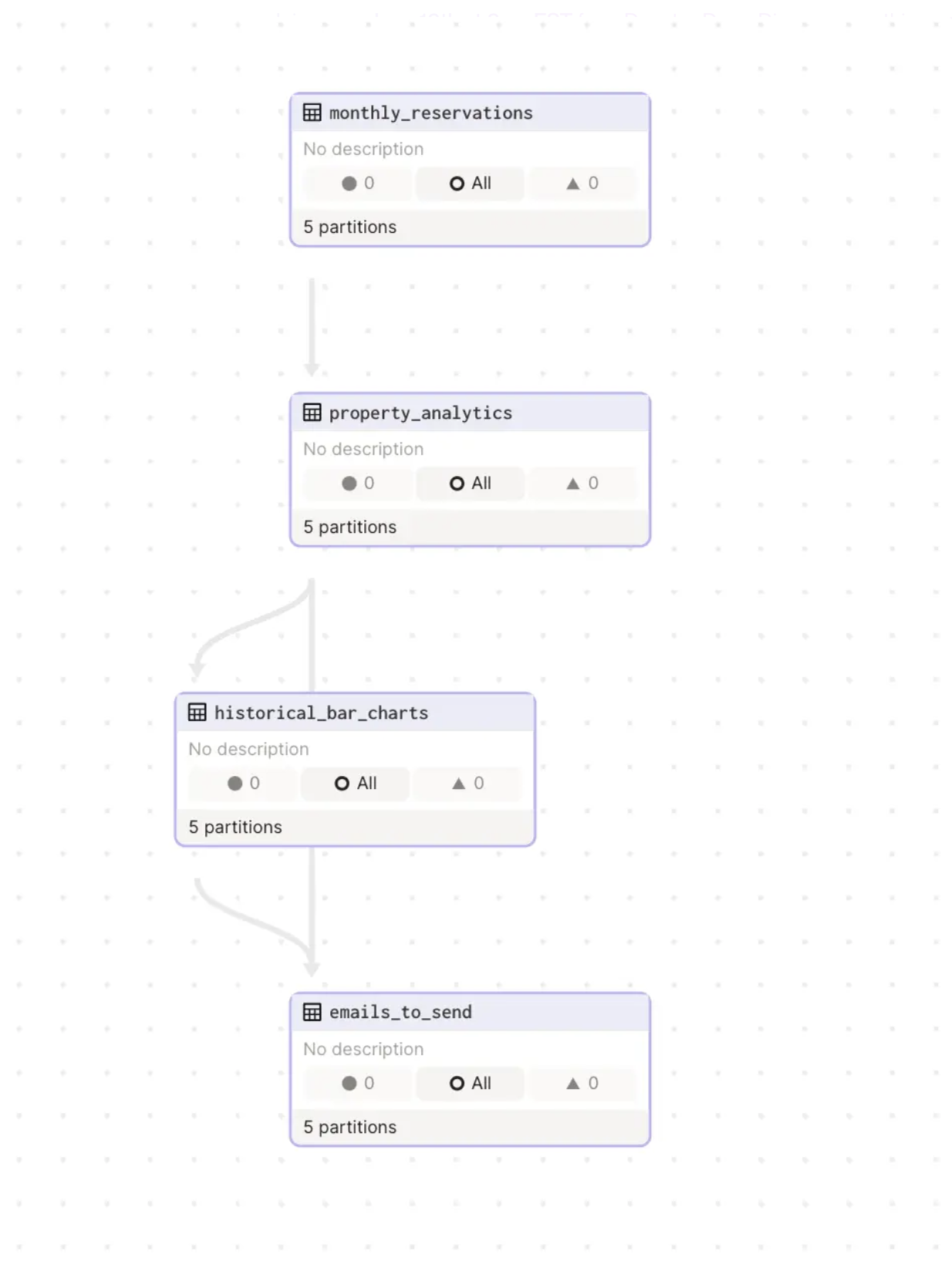
Sending the email
We’ve gathered our data and built our chart; all that’s left is sending the emails to various hosts. This step doesn’t require another asset, because it isn’t creating any output record. Instead, we need to take the assets we’ve created and do something with them, which is exactly why jobs exist.
We’ll create a job to wrap our assets, and then add an op to take the emails_to_send data and send the emails. Wrapping all of our work thus far in a single job creates a single unit of work that can be executed, scheduled, and monitored at once.
Like the assets in the job, the job has the monthly partition. This allows the entire job to be partitioned as a unit. The call to emails_to_send.to_source_asset() exposes the emails_to_send asset to our (currently undefined) send_emails op.
The final step is adding it to the Definition object.
Before diving into the op, we’ll need to make two resource modifications. The first change is to make our chart files readable. This involves adding a simple function to LocalFileStorage that reads a file and returns the raw bytes.
Our second resource change is a bit more complex. We need a way to send emails, without adding that code directly to our op. A simple EmailService wraps EmailClient, which is fake but modeled on a real world commercial email service’s SDK.
Like every other resource, we need to add it to our Definitions object.
Because this configuration involves a private token, we’ll follow good security practices by setting the value as a configurable environment variable. We’ve now covered all the necessary dependencies to look at the send_emails op.
Ops aren’t partitioned (since they don’t materialize data), but the job’s partition bounds are still accessible via the AssetExecutionContext object, allowing us to filter the emails DataFrame (which is the output of the prior call to emails_to_send.to_source_asset() in the job).
We can then iterate over the filtered results and send the email. The call to image_storage.read returns raw bytes, which are then encoded into a base 64 string.
Scheduling the job
The final step is to take this job and make sure it runs automatically every month. We’ll do this by defining a schedule.
This schedule will ensure our job runs every month at midnight on the first day. We can also see the schedule in the Dagster UI and toggle on/off or test different evaluation times.
Moving our pipeline into production
It’s worth considering what changes we’d need to make to this code before moving it into production.
Data access
The monthly_reservations asset does a joined database query, which could be prohibitively expensive at a sufficient scale. An alternative may be to make multiple large queries and then merge them with Pandas, but this comes at a higher memory cost. One solution at scale is creating a read replica of the database, or relevant database tables, that pipelines can query without impacting production services.
I/O Manager
Using DuckDB as an I/O Manager works well in dev, but queries are performed in memory, so it may not be feasible at production scale. An alternative is to use a production data platform as an I/O Manager. Because the architecture is pluggable, this is easy to do by creating a new resource and replacing the current one in the Definition object.
As detailed in the post “Poor Man’s Data Lake with MotherDuck" you can easily port this local project to MotherDuck, the brand new DuckDB serverless analytics platform. This would be a simple change from:
Alternatively, you can plug into a platform like Snowflake or Databricks.
Fanning out or multi-partitioning
We create images and send emails by iterating over a large number of results. This increases the risk of a mid-execution failure that may force a lot of rework. It also means we’re working on large amounts of data at once, which could lead to memory problems. We could mitigate this by fanning out those iterations to ops that create a single chart, for example.
We’re partitioning solely on time (per month), but we could also do a multi-partition to work on smaller blocks of data at once. For example, we could partition on both time and geographic submarkets. A single partition then would represent a few thousand properties at most and would be much more manageable.
Error handling, logging, and testing
Good engineering practices go a long way, and Dagster has built-in support to simplify these. Ideally, each asset would have error handling (with retries, if appropriate) and context-specific logging that surfaces useful data regardless if asset/job succeeded or failed. Finally, all these Pandas calls are a recipe for tricky bugs that are easy to miss. Solid testing, and the designs needed to enable good testing, are essential if you were to take this into production.





.jpg)
.png)



.png)

