


What Is a Data Discovery Platform?
A data discovery platform is a software solution that enables organizations to find, understand, and use their data, regardless of its location. These platforms automate data exploration and analysis to uncover patterns, anomalies, and insights, serving as a foundation for data-driven initiatives like governance, compliance, and AI development.
Data discovery platforms make it easier to:
- Locate data: They connect to various data sources (databases, cloud storage, data lakes, and applications) to identify where data resides.
- Understand data: They provide tools to profile data, assess quality, and understand relationships between different data elements.
- Catalog data: Platforms often create a data catalog, a centralized repository with metadata that describes the available data assets.
- Analyze & visualize: They offer user-friendly interfaces and visualization tools to explore datasets, spot trends, and identify anomalies.
- Govern data: Platforms assist in defining access controls, enforce rules, and manage data throughout its lifecycle, supporting privacy and security efforts.
- Enable AI: By making data discoverable and trustworthy, these platforms are critical for building and scaling AI-powered applications.
Key components and processes of these platforms include:
- Data source identification: Recognizing and cataloging all available data assets.
- Integration with governance frameworks: Applying established frameworks to ensure compliance with data requirements.
- Data cataloging: Creating a searchable, organized inventory of data assets.
- Data quality management: Assessing and improving data accuracy and consistency.
- Security & governance: Implementing controls and policies to protect sensitive information and ensure compliance.
This is part of a series of articles about data platform.
What Data Discovery Platforms Do
Locate Data
Data discovery platforms excel at helping organizations locate data wherever it resides in the enterprise. They use automated scanning and connectors to search databases, cloud storage, data warehouses, and other sources without manual intervention. By continuously scanning the environment, they ensure their inventory stays up to date even as new data assets are introduced or old ones are retired.
This ability to locate data quickly is crucial for overcoming data silos, making it easier for technical and non-technical users to find relevant information. By providing a central catalogue, these tools eliminate the need for time-consuming manual searches, allowing teams to respond rapidly to business needs and regulatory inquiries.
Understand Data
Once data is located, a platform must help users understand the context, structure, and meaning of that information. Data discovery solutions use features like metadata extraction, profiling, classification, and automated tagging to illuminate what data exists and what it describes.
This intelligence is surfaced through search, recommendations, and visual summaries, making the data accessible to users with varying technical backgrounds. Understanding data is not just about identifying columns or formats. It involves assessing data quality, highlighting sensitive information, and tracing relationships between datasets.
Catalog Data
Cataloging is a core function of data discovery platforms. By constructing a centralized repository of all available data assets, these tools enable organizations to manage and retrieve data efficiently. The catalog includes metadata such as source, owner, schema, freshness, and usage history, giving users confidence in what they’re accessing.
A mature catalog doesn’t only list data; it also supports collaboration by allowing users to annotate data sets, flag issues, or recommend trusted sources. This central catalog becomes the backbone for data governance, improving consistency, accountability, and reuse throughout the data lifecycle.
Analyze and Visualize
Modern data discovery platforms often include analysis and visualization tools so users can explore datasets without switching to other solutions. These platforms enable users to create dashboards, generate insights, and visualize trends directly from discovered data, often using natural language queries or drag-and-drop interfaces.
The ability to analyze and visualize within the discovery platform accelerates the journey from data to insight. It reduces the friction in moving data between tools, lets users validate their findings on the fly, and supports better, faster decision-making across the organization.
Govern Data
Data governance is integrated deeply within data discovery platforms. They enforce access controls, track data usage, and underpin compliance efforts with audit logs and policy enforcement. By embedding governance into the discovery process, these platforms help organizations manage who can access what data, ensuring privacy and regulatory requirements are met.
Users benefit from transparency: they know where data comes from, how it can be used, and its quality status. For compliance teams, tooling for governance reduces manual monitoring burdens, simplifies policy application, and centralizes incident response, strengthening an organization’s overall data posture.
Enable AI
Data discovery platforms play a significant role in enabling AI initiatives. They provide curated, well-documented, and high-quality datasets that are essential for building trustworthy machine learning models. Discovery platforms can also surface overlooked datasets and relationships that unlock new training data or features.
Automation within these platforms helps ensure the data used for AI is relevant, up to date, and compliant with internal policies or external regulations. As AI adoption increases, robust discovery tools have become essential in controlling risk and accelerating experimentation and deployment for enterprise AI projects.
Key Capabilities of Data Discovery Platforms
Automated Data Cataloging and Metadata Management
Automated cataloging is central to a data discovery platform’s value proposition. These systems connect to disparate data sources and automatically extract metadata, mapping datasets, schemas, and lineage without heavy manual effort. This automation not only accelerates the creation of a living data inventory but also significantly reduces human error in documentation.
Effective metadata management goes beyond collection: it involves classifying, enriching, and maintaining metadata over time. Powerful search, tagging, and relationship mapping features enable users to derive more context and make informed decisions. This automated approach ensures data remains discoverable and relevant as environments evolve, supporting continuous data-driven operations.
Data Source Identification
Understanding data lineage (the movement and transformation of data over time) is essential for transparency, trust, and compliance. Data discovery platforms offer dynamic lineage mapping that tracks how data flows from its original sources through pipelines, transformations, and reporting layers. This way, users can easily visualize dependencies and understand the ripple effects of changes.
Impact analysis builds on lineage to answer questions such as, “If I change or remove this field, what downstream dashboards, models, or processes will break?” By illuminating these connections, platforms prevent costly errors, support safe governance, and enable data migration or modernization projects with minimal disruption.
Data Quality Management
Continuous data quality monitoring is crucial for maintaining trustworthy analytics and AI. Discovery platforms embed automated profiling and validation mechanisms to detect anomalies, missing values, or inconsistent formats within datasets. These quality checks are often visualized through dashboards and alerts, allowing teams to triage and respond before issues reach end users.
Observability doesn’t stop at static checks. More advanced platforms detect trends, monitor data freshness, and spot drifts over time. This ensures organizations can take corrective action quickly and maintain a high standard for their production data environments, thereby improving the accuracy and reliability of business decisions.
Integration with Data Governance Frameworks
Integration with governance frameworks is a defining strength of leading data discovery platforms. They enable the application and enforcement of business rules, privacy policies, and data stewardship practices at scale. Integration points may include interoperability with identity management, policy engines, and compliance reporting tools, which ease the work of governance teams.
These integrations support automation of common governance tasks such as access provisioning, data masking, or retention enforcement. By making policy enforcement native to the discovery process, organizations can reduce the risk of ungoverned data usage and set clear guidelines for all data interactions, driving both safety and productivity.
Security and Governance
Security and compliance are non-negotiables for handling enterprise data. Discovery platforms incorporate strong access controls, encryption, and auditing to protect sensitive assets. They also provide automated detection of personally identifiable information (PII) and other regulated data, mapping it to compliance frameworks like GDPR, HIPAA, or CCPA.
These capabilities make it straightforward for organizations to demonstrate compliance during audits and mitigate the risk of data breaches. Centralizing controls within the discovery platform helps enforce consistent security practices and enables organizations to adapt quickly to evolving regulatory landscapes, without increasing operational burden.
Notable Data Discovery Platforms
1. Dagster
.png)
Dagster is a data discovery–adjacent platform that approaches discovery through data assets, metadata, and operational context, rather than through standalone cataloging alone. It helps organizations understand what data exists, how it is produced, and whether it can be trusted, making it a strong foundation for discovery, governance, and AI readiness.
Dagster Compass extends these capabilities by serving as a lightweight, developer-first data catalog that surfaces asset metadata, lineage, ownership, and health in a centralized interface. Compass focuses on making data discoverable and understandable directly from how it is produced, without requiring heavy manual curation.
Key features include:
- Software-defined data assets: Treats datasets as first-class entities with explicit dependencies, ownership, and metadata
- Built-in lineage tracking: Automatically captures upstream and downstream relationships across pipelines, warehouses, and transformation tools
- Operational metadata capture: Surfaces freshness, run history, failures, and quality checks alongside datasets
- Dagster Compass catalog: Provides a centralized, searchable view of data assets, lineage, and metadata without complex catalog setup
- Data quality and validation: Integrates checks and expectations directly into data production workflows
%20(1).webp)
2. Alation
Alation is a data discovery platform to help organizations find, understand, and trust their data, even in highly decentralized environments. AI-driven simplifies how users navigate enterprise data. Alation's platform enables both technical and business users to quickly locate relevant data assets through natural language queries, semantic search, and customizable filters.
Key features include:
- Universal search: AI-powered search bar queries across connected data sources, including databases, lakehouses, and file systems
- Natural language understanding: Interprets human-readable questions to return contextually relevant results
- Semantic and keyword search: Combines search by meaning and keywords for precise discovery
- Advanced filtering: Filters results by object type, custom tags, or data quality status (e.g., endorsed, deprecated)
Saved searches: Allows users to save and reuse complex queries for consistent access to trusted data

3. Atlan
.webp)
Atlan is a data discovery and governance platform to help data teams find, understand, and collaborate on data across the enterprise. Built with a focus on active metadata, Atlan transforms metadata into a dynamic layer that supports search, lineage, access control, and context.
Key features include:
- Active metadata platform: Continuously ingests and activates metadata from tools like Snowflake, dbt, Looker, and Tableau to keep discovery and governance up to date
- Search and discovery: Use natural language search to find datasets, dashboards, metrics, and lineage, with rich context and usage metadata
- Data lineage: Visualize upstream and downstream lineage across modern data stacks to understand dependencies, assess impact, and troubleshoot faster
- Embedded Collaboration: Bring context to data with embedded Slack/Teams integrations, user annotations, conversations, and ownership assignments
Role-based access control (RBAC): Govern data access and enforce policies with role-aware permissions, audit trails, and automated workflows
.webp)
4. Collibra Data Catalog

Collibra Data Catalog helps simplify data discovery, understanding, and access across large ecosystems. It connects to over 100 data sources, automatically extracting and enriching metadata to create a unified, searchable inventory of enterprise data assets.
Key features include:
- Automated discovery and profiling: Uses over 100 native connectors to scan structured and unstructured data, automate profiling, and reduce manual stewardship work
- AI-assisted metadata curation: Uses AI to generate descriptions and classify assets, simplifying catalog creation and maintenance
- Contextual enrichment: Connects data to glossary terms, policies, data contracts, stakeholders, and quality metrics to improve understanding
- Integrated data marketplace: Offers a curated, self-service portal for discovering and accessing trusted data products
End-to-end lineage mapping: Visualizes technical and business lineage to show where data comes from, how it’s used, and its downstream impact
5. AWS Glue Data Catalog
.webp)
The AWS Glue Data Catalog is a centralized metadata store for managing and discovering data across AWS and external sources. It uses crawlers to automatically scan data repositories, infer schemas, and populate metadata tables. This enables a consistent, queryable view of data assets across services like Amazon Athena, Amazon EMR, and AWS Lake Formation.
Key features include:
- Centralized metadata repository: Stores schema, location, and operational metadata in databases and tables for unified access
- Automatic data discovery: Crawlers detect and register new or updated data sources, reducing manual cataloging
- Schema management and evolution: Tracks schema changes and partitioning for supported formats and services
- Materialized views for Iceberg tables: Supports precomputed views that automatically refresh for faster query performance
Column-level statistics: Computes metrics like min/max, null counts, and distinct values to help profile data and optimize queries
6. Google Cloud Data Catalog
Google Cloud Data Catalog is a fully managed metadata management service that helps organizations discover and understand data assets across Google Cloud. It provides a unified search interface and supports tagging, classification, and metadata enrichment. It is now deprecated and scheduled for discontinuation in January 2026. Users are encouraged to transition to Dataplex Universal Catalog for continued support.
Key features include:
- Centralized metadata management: Stores technical and business metadata for Google Cloud data assets
- Search-driven discovery: Uses a search interface built on Google's internal search engine for fast, relevant results
- Custom tagging system: Supports user-defined tags and tag templates for consistent metadata enrichment
- Sensitive data detection: Integrates with the DLP API to automatically identify and tag sensitive information
Third-party metadata integration: Supports ingestion of metadata from tools like Looker, Tableau, and on-premises RDBMS systems
7. Informatica Enterprise Data Catalog
Informatica Enterprise Data Catalog is a scalable metadata management solution to scan, index, and organize data assets across cloud and on-premises environments. It provides capabilities for data discovery, profiling, and lineage to help users understand their data.
Key features include:
- Automated data discovery: Scans and catalogs metadata from enterprise data sources, both cloud and on-premises
- AI-assisted curation: Uses machine learning for domain discovery, similarity detection, and linking business terms to technical assets
- Data lineage: Tracks end-to-end lineage at system and column levels for transparency and impact analysis
- Contextual data profiling: Surfaces data quality and profiling information to support informed data use
Collaborative insights: Enables teams to share knowledge and maximize data reuse through a unified platform
8. Ataccama Data Catalog

Ataccama Data Catalog is part of the Ataccama ONE platform and integrates data discovery, quality, and governance into a single environment. It uses AI-driven automation to catalog data from cloud and on-premises sources, classify it, and maintain quality through continuous monitoring.
Key features include:
- Automated data discovery and classification: Scans connected systems to identify data assets and apply AI-based tagging and business term suggestions
- Data quality monitoring: Uses prebuilt and custom rules to detect anomalies, profile data, and ensure reliability over time
- Augmented data lineage: Captures end-to-end lineage and overlays it with business terms and quality metrics for better traceability
- Business glossary integration: Manages business terms, rules, and policies to align metadata with organizational context
- Collaborative workflows: Supports task assignment, comments, and feedback within the catalog for improved team coordination
Report and metadata cataloging: Indexes reports, dashboards, ML models, APIs, and other assets in a customizable metadata system
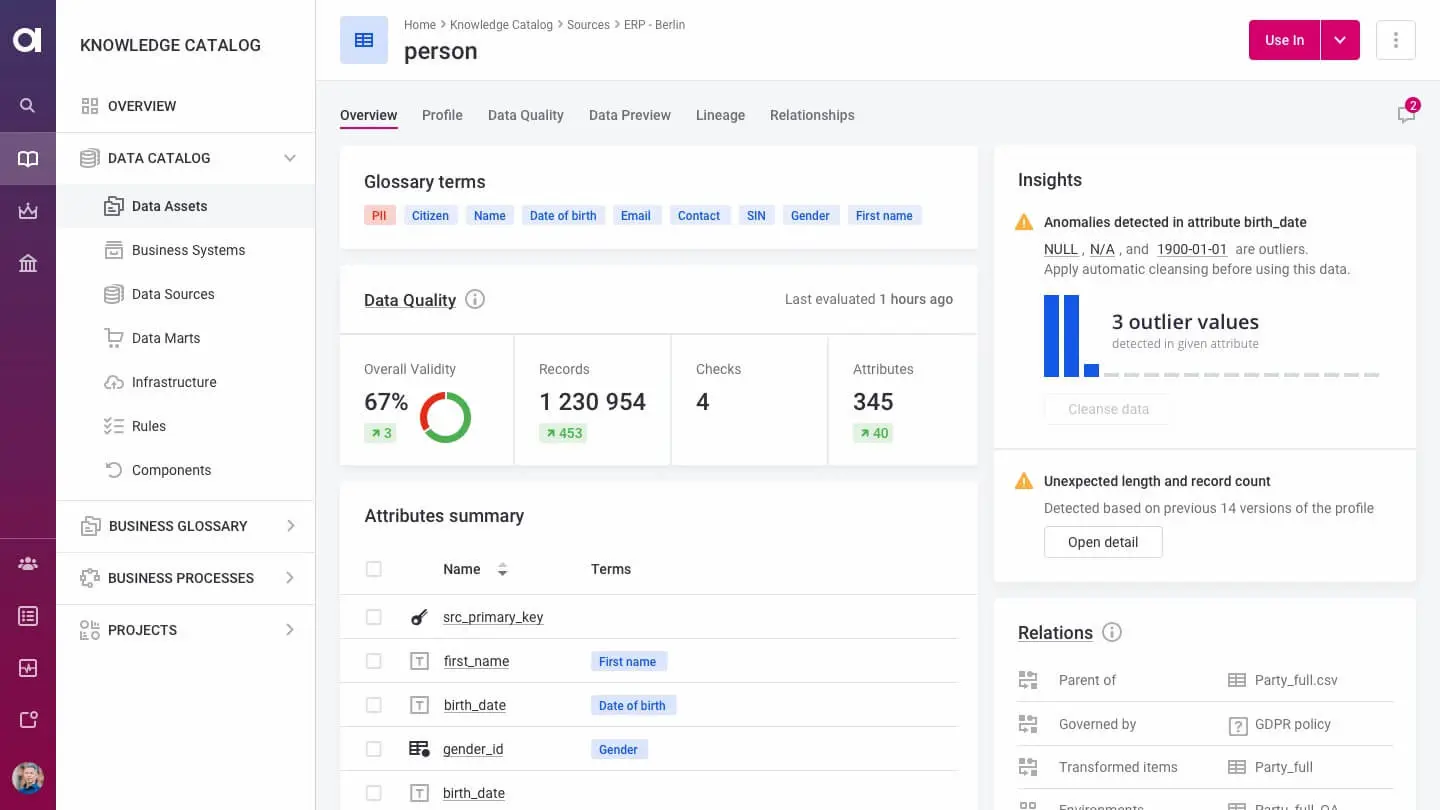
9. OvalEdge
OvalEdge is a modular data governance platform that includes a data catalog designed for fast deployment and broad organizational adoption. It connects to over 150 data sources and uses AI and automation to simplify metadata management, lineage tracking, and quality monitoring.
Key features include:
- Automated metadata crawling: Uses over 150 built-in connectors to scan and catalog data without manual mapping
- AI-powered natural language search: Supports business-friendly, ChatGPT-style queries to retrieve insights from enterprise data
- Integrated data quality tools: Monitors and ensures data consistency and accuracy across sources
- Lineage and glossary: Tracks data flow automatically and manages business terms for clarity and traceability
Embedded collaboration features: Designed for cross-team collaboration and integration with commonly used enterprise tools
10. data.world
data.world is an enterprise data catalog built around a knowledge graph architecture that captures relationships, context, and meaning across data assets. It enables teams to discover, govern, and connect data through a unified platform. The catalog supports explainable AI outcomes while delivering search, automated governance, and scalability.
Key features include:
- Knowledge graph foundation: Models data relationships and business logic to enable contextual understanding across the data ecosystem
- AI context engine: Supports accurate, governed AI applications by delivering explainable, precise responses from large language models
- Enterprise search: Provides Google-like search that understands both technical metadata and business semantics
- Automated governance workflows: Adapts to team processes with smart workflows for scalable policy enforcement
Unified data landscape: Breaks down silos by integrating data from multiple sources into a single, connected view
Conclusion
Data discovery platforms provide a foundational layer for modern data ecosystems, enabling organizations to gain visibility, control, and value from their data assets. By automating the processes of locating, cataloging, understanding, and securing data, these platforms help bridge the gap between data availability and usability. They support collaboration across technical and business teams, simplify governance, and ensure that data is both accessible and trustworthy, crucial for analytics, compliance, and AI initiatives alike.






.jpg)
.png)



.png)

