



A complete guide with all the insights, tips, and some predictions for the data platform engineer, just like an Almanack provides, with practical information for daily life.
Operating the data orchestration layer can be as critical as the source OLTP databases, when decisions are taken from the data assets produced by downstream data pipelines. When orchestration gets at the heart of triggering and observing most of the schedules or assets, there is even more importance involved.
In Part 1 I argued that the open data platform makes orchestration data and its flow simpler, providing integration into data assets and transformation, ETL, BI and even Kubernetes all while being open, making it a fully composable data stack. This piece continues with what it takes to operate orchestration, and looks at one of the hardest parts of data engineering "DevOps", and how to manage different environments, business code vs infrastructure code, scalability and how orchestration.
I'd argue that DevOps is what data engineering was a decade ago, when everyone was talking about data science, but the actual work was 80% data engineering. With AI and generative AI, where even more data gets used for model training, or generated by AI, data engineering gets even more critical and larger, therefore also DevOps, which over a certain size gets the biggest task: deploying and upgrading to the latest error-free version, and keeping it stable and scalable.
Deployment, how to Start: DevOps vs. GitOps
Before you start deploying or operationalizing anything, you will get into DevOps and more so, GitOps. That's why we start with that.
Because once you start with deploying your own infrastructure, you need a way to automate changes across your systems, or even your development server. You can't manually deploy on different systems. If you only have dev and production, it might work at the start, but there are so many dependencies, stateful NFS mounts where important configs or DWH data is stored, or dependencies between the installed tools from the BI tools to data integration and orchestration.
GitOps is taking that deployment git repo and including infra code such as Kubernetes deployments (also called Infrastructure as Code (IaC)), and making them automatically deployable on git commit pushes to the git repo with post-trigger actions. With the goal of operationalizing data orchestration, we need to look at GitOps and DevOps best practices. GitOps is everywhere these days, with agents working best with Markdown or local YAML or code that is checked in to a git repo.
Orchestration is no different here, we want to have a repo for the code of data pipelines as well as infrastructure and ENVs for each environment (prod, test, dev). We need to separate infra from business-heavy ETL in the data pipeline. We want to standardize the deployment patterns (e.g. base and overlay is how Kustomize is doing it).
How to Operationalize Data Orchestration?
So now that we have GitOps ready and understand it, let's revise the challenges and then best practices of operationalizing a data orchestration tool. To make it more concrete, I use Dagster and its features whenever suited.
The Challenges of Deploying Data Orchestration
One important part is how to deploy a system that will be at the heart of your data stack and responsible for the refreshing of your data assets.
The problems are multi-fold. Do you want to auto-scale with Kubernetes, Terraform, meaning you rent machines and scale up and down based on tasks in your data pipelines, spawning up multiple spark jobs, multiple DuckDB processes in parallel as part of spawned containers? Or do you want to pay for it and just connect data pipelines with Databricks Spark Cluster, and hook up Dagster+ that handles it all.
Compare it to the Titanic iceberg collision where too many holds overflowed and then it sunk. Alex Noonan says it's the same with data at scale, you get too many duplicated data pipelines, tools, inconsistent data contracts, unclear ownership and ungoverned sprawl.
Dagster's ability to track compute costs per asset, per partition — this feeds directly into your "open data platform" narrative. FinOps for data pipelines.
Best Practices for Running Data Orchestration: Organization vs. Deployment
The problems at scale can get complex and run into a lot of work, quite quickly. Therefore we need a clear setup that works for all our deployments. Here we look at separating the organization-side and the deployment itself.
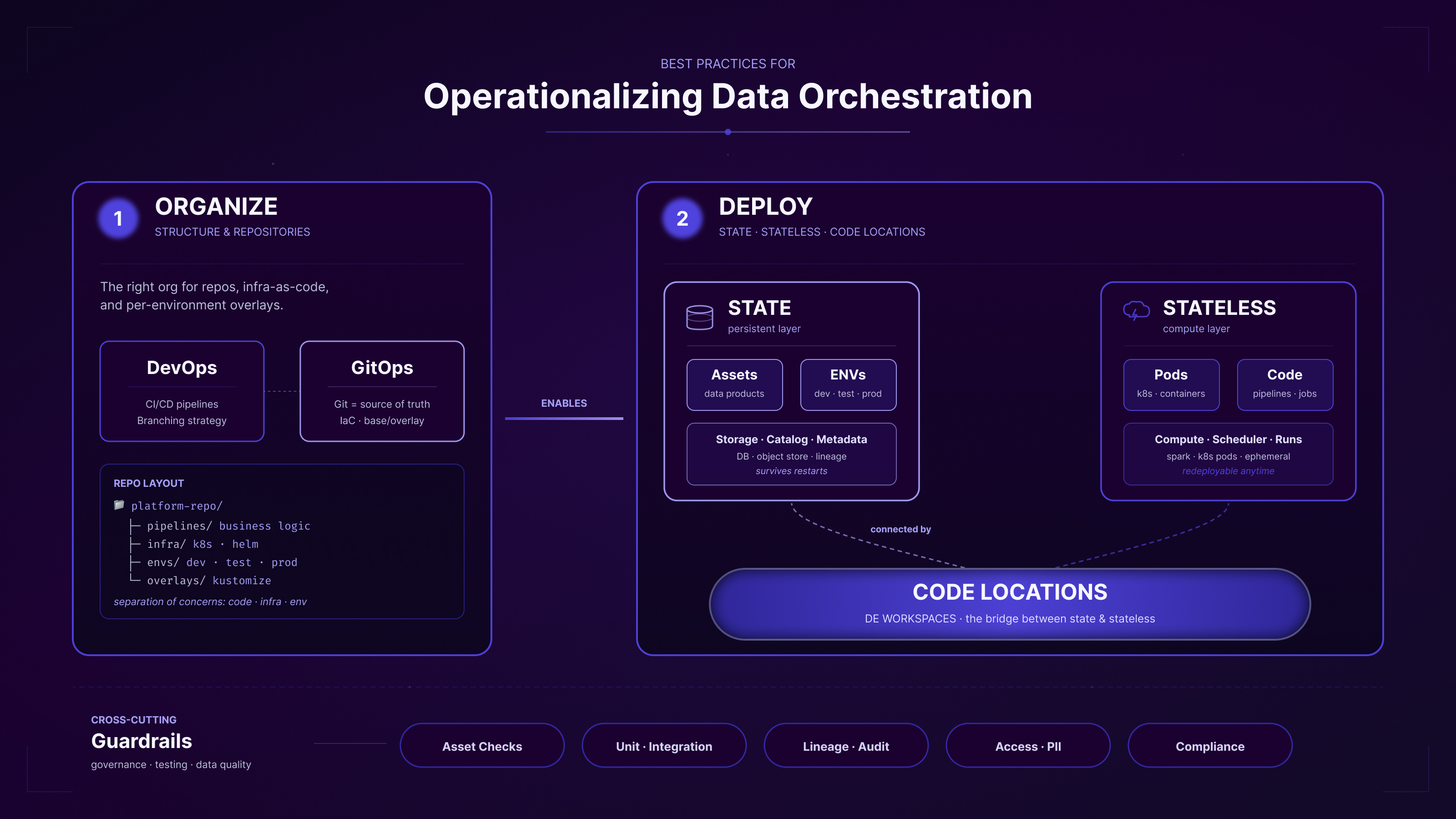
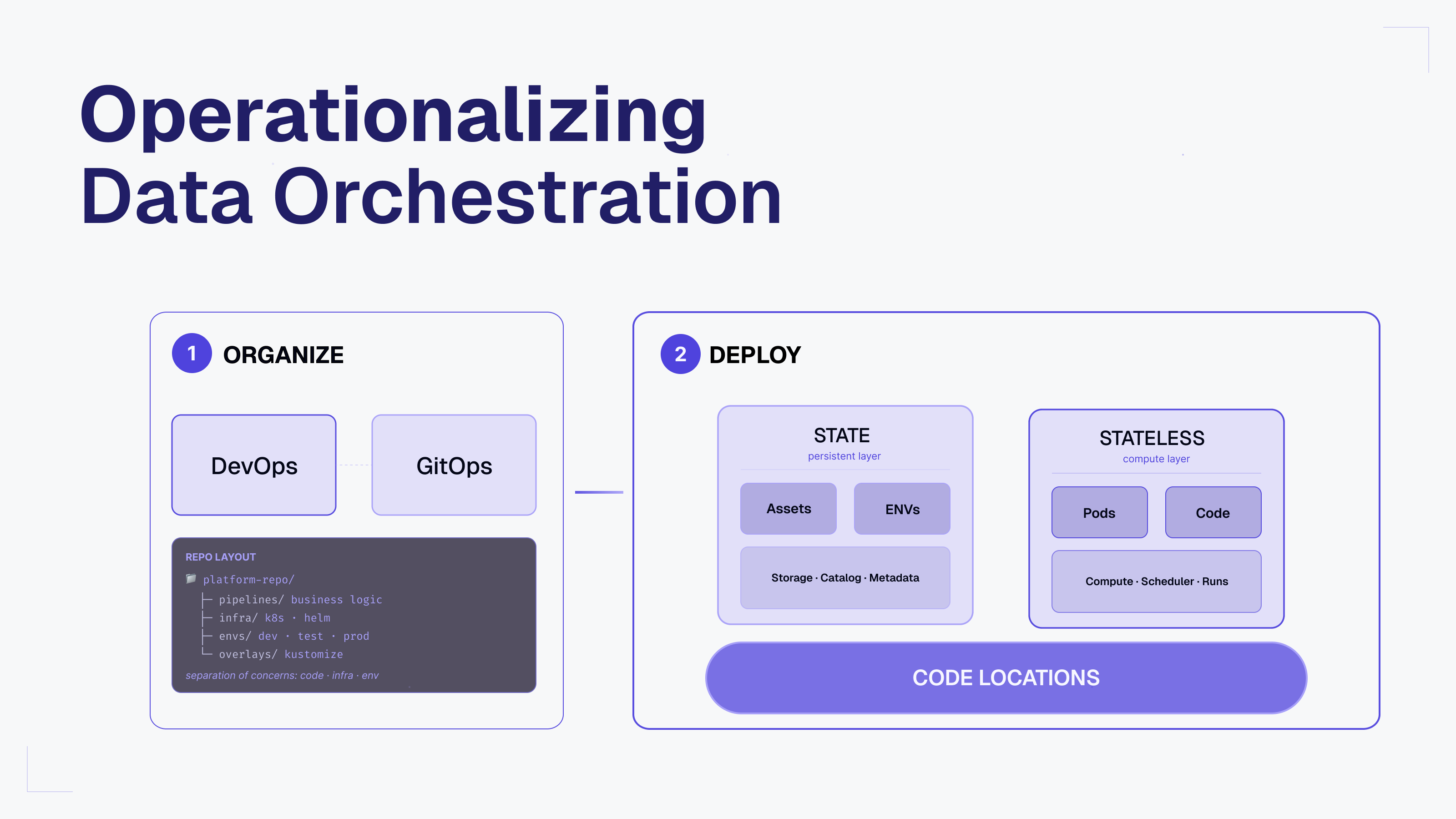
This shows the organizing part that is about the structure and the deployment handling state and business logic.
It all starts once you decide to run your own deployments and machines. Maybe you have a platform team or cloud server that you use with Kubernetes. That's when we need to separate the state vs stateless, and also the code of data pipelines is a key point here.
1. Organize DevOps means to focus on structure and organization. We need the right organization for structure and repositories. For example, I once created a Kubernetes GitOps deployment Blueprint repo, that includes such structural questions such as GitOps workflow patterns, infrastructure configs, tenant isolation, database migrations, and observability templates for production deployments with Flux.
The organization usually happens in the form of a git repository, and you have one for environment and deployment for infrastructure as code. You set up some sort of GitOps with Flux, ArgoCD, Terraform, or GitHub Actions or similar to automate deployment with a single git commit && git push. All of the environments are typically handled with ENV variables.
2. is Deployment, this is where we handle state and stateless. The deployment repo is usually mostly stateless. It has state for persistent storage locations for configs that Dagster, or BI tools or others need, but these are of a technical nature and usually can be recreated as there is no historic data stored as in a data warehouse where we ingest data from source OLTP databases for example, and version the changes. This way of not breaking state is much harder.
We need to make sure that the data assets produced by the data orchestrator stay intact, and don't get purged with a new deployment. Other things to take care of are technical resources such as the Spark integration as a resource Python file, which is stateless and can just be redeployed when we update the code, so we have the latest version prepared for the next run.
There's no complexity, and with proper versioning, we can also easily roll back by just setting the older version in our deployment repo, commit and push. GitOps will then make sure to roll back to a working version. And when the data itself needs repair, partitioned backfills let you re-materialize a specific time range across the whole asset graph, with dependencies resolved automatically.
Code Locations: the Key Piece to Connect State and Stateless
The key piece, again, is connecting state with no state, and Dagster offers an elegant solution here that I suggest for any data work: code locations or also thought of data engineering workspaces. The code locations connect the state and stateless in a meaningful way. Code locations are both stateless (libraries used, technical implementations) but also stateful once the business logic has been run. The outputs are data assets used by downstream processes, and we can't just delete and recreate them easily. It might also be that some of the assets take hours to create, so just deleting them and then rerunning the full data warehouse for a day isn't desired.
Code locations are key to a successful orchestration deployment story where we differentiate business from technical implementation logic. Many start deploying Airflow or other data orchestrators and pretty quickly land at the questions: "how do we update data pipelines?", "do we give people access to the deployment repository?", "where are all the envs for each environment?", "how can business users quickly test their Python script or notebook?", "what about access permissions to the data assets, are they allowed to see all tables, the full S3 bucket?".
With workspaces you can containerize your data pipeline logic, with its required Python libraries, into a docker image or similar, and test it and deploy independently from the deployment code that is usually only accessible to the platform team or data engineers if they do platform engineering. This leads to a natural separation between data wranglers and data platform people.
Here's an overview of how centralized teams can structure their code locations differently - from centralized to embedded and to hybrid, with dedicated workspaces for different teams such as data engineering, data scientists, finance or marketing:
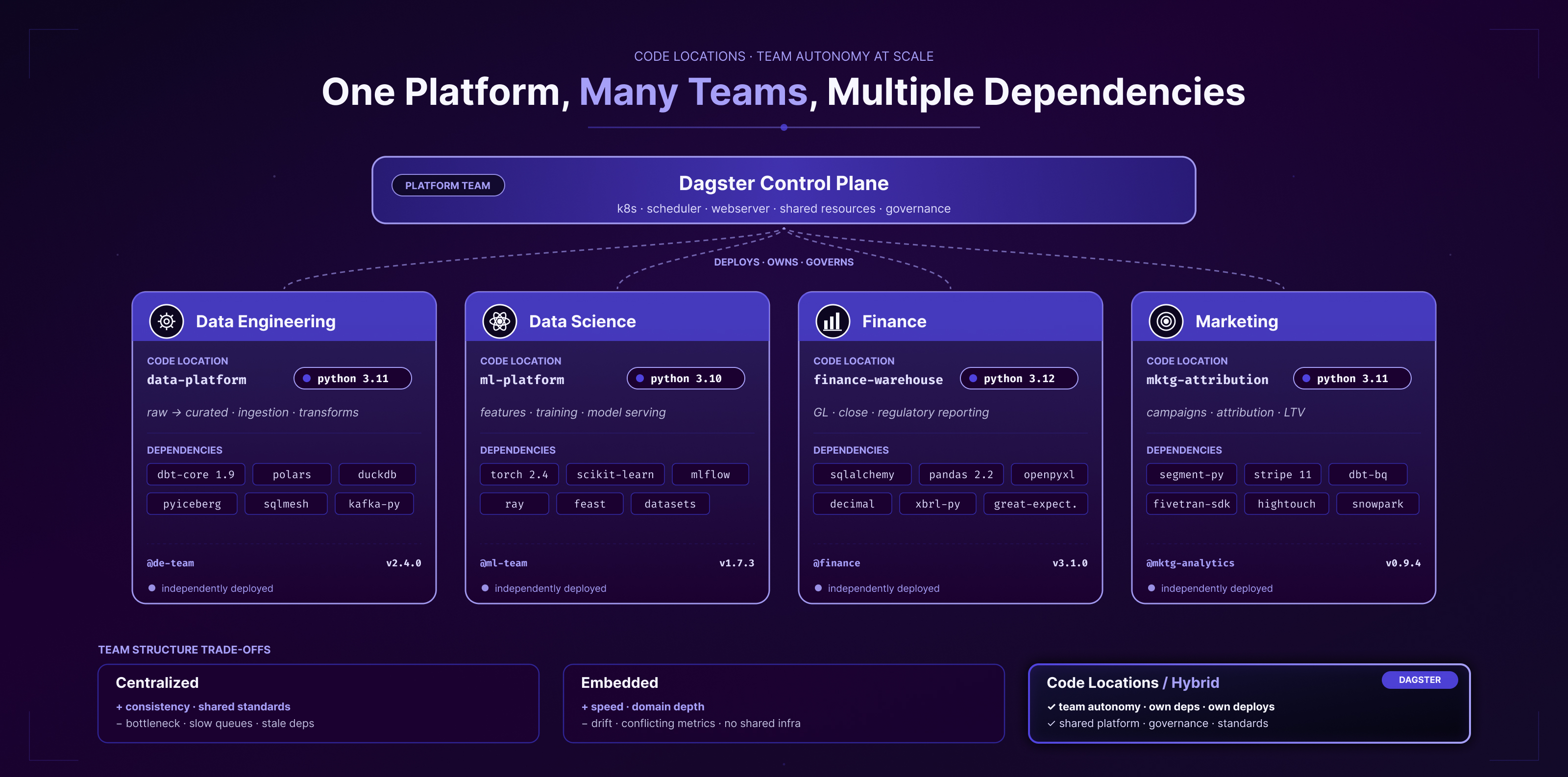
Find more on multi-tenancy and code locations at Multi-Tenancy for Modern Data Platforms
The differences are that centralized data team structures can give you consistency across teams, but are bottlenecked and slower when you want to change and iterate. Embedded means that teams have a link to each team, increasing speed and domain depth, but can lead to drift and fewer standards if not careful.
The different setup of teams is also something we have discussed since the dawn of data work. It started with a centralized data warehouse to a more shared Data Mesh and other approaches. With code locations, you can have a centralized data platform orchestrator while still having your domain ETL and data pipelines in dedicated team code repositories, using a hybrid with the best of both worlds.
The code locations also fit into the right abstraction layer as we talked about in the Dagster Almanack, meaning that code locations separate concerns for data teams, and with Dagster resources separate business from technical implementation, that can be used across different code locations (e.g. versioned PyPI packages), making the setup more flexible and adaptable to how data teams work.
Microservices that Work with a Central Open Data Orchestrator
The right abstractions with code locations let you use data pipelines as an advanced microservice with reusable technical code while using sole-purpose domain logic in each location, that integrate into the platform easily with Dagster abstractions and applied functional data engineering best practices. With something like Dagster Pipes, you can invoke external code — Spark jobs, notebooks, R or Rust processes — while logs and metadata still stream back into the asset graph.
If you need a better integration for less technically savvy people, you can use the in-built DSL. DSL stands for Domain Specific Language, which lets you define your pipelines and transformations with a simple YAML interface. Dagster Components takes this further: a toolkit for packaging integrations and common patterns behind a YAML interface, so pipeline instances can be defined with little to no Python.
General Learning from GitOps
More learnings from using GitOps and deploying orchestration and general data workloads with Kubernetes, here are 8 more points:
- Separation of concerns is crucial - keeping infrastructure, platform services, and business logic (pipelines) in distinct sections makes maintenance and collaboration easier.
- Standardized deployment patterns like the base/overlay structure with Kustomize allow for reusable configurations across environments with minimal environment-specific overrides.
- Versioned artifacts with timestamps (e.g., finance-pipeline-20250512123045.tar.gz) create a reliable release process that enables rollbacks and audit trails.
- Database migration automation tools, such as Liquibase, can handle schema changes programmatically across environments, thereby reducing manual errors.
- Test early, test often - validate data pipelines, infrastructure code, and database migrations separately before integration testing in an isolated environment.
- Workspaces separation from infrastructure code enables domain experts, such as data scientists and analysts, to focus on their core competencies while maintaining deployment standards.
- CI visibility through lineage diagrams and documented processes enables teams to understand the deployment flow and troubleshoot issues more efficiently.
- GitOps, as the single source of truth, means changes occur through Git commits, creating an automatic audit trail and enabling pull request reviews.
This overall blueprint, with best practices, helps you specifically with data engineering reference architecture for Kubernetes-based data platforms using GitOps workflow patterns. It includes infrastructure configs, tenant isolation, database migrations, and observability templates for production deployments with linked CI/CD implementation with GitOps infrastructure example.
How to Deploy Dagster: Kubernetes, Helm, Docker
If we go one step deeper, we see different ways of deployment pretty quickly. We will keep this chapter short, as it would fill a full book, but generally you need to decide if you want to run scalable on something like Kubernetes, where pods and compute are automatically scaled up/down, or locally to test, with docker.
Or if you just want to get started without headache and lot of development time, this is where paying for something like Dagster+ service makes sense.
The biggest question for data pipelines is where do you run the compute, do you scale up a Spark cluster, do you run Python or SQL engines as part of Kubernetes pods, or do you use any other way. Because that's where you will spend most money, as data pipelines are only expensive as the process they run, e.g. crunching large data sets with compute. Partitioned, incremental materialization is the other half of the cost equation. Processing only yesterday's partition instead of a full refresh is where the orchestrator saves compute money. The same scaling applies to partitioned asset checks, so quality validation only runs on the partition that changed.
You can think about it more high-level, so segregate storage from compute with a Lakehouse or with tables and data stored in Open Table Formats (Iceberg, Delta and Hudi), that saves you money by not using expensive SSDs, but is slower and costs more on the analytics side when you query and join these data.
Here's a list that helps you get started to operationalize Dagster as the data orchestrator with different deployment options:
- Helm Charts (recommended for production on Kubernetes): Official chart at helm/dagster:
helm repo add dagster https://dagster.io/helm. Two charts:dagster(webserver + daemon infra) anddagster-user-deployments(your code locations), so pipeline code deploys independently of platform upgrades. Guide: Deploying to Kubernetes. - Docker Compose (local or single VM, e.g. EC2): one container each for webserver, daemon, and per code location. Example: examples/deploy_docker, guide: Docker deployment. For pure local dev, just
dagster dev. - Kubernetes customization: there is no official operator — the Helm chart is the K8s story. Runs launch as K8s Jobs via
K8sRunLauncher, with autoscaling configured and tunable per asset/job withdagster-k8s/configtags. See Customizing your deployment. - AWS ECS / VM (if no K8s): Terraform/ECS pattern, example at examples/deploy_ecs, guide: Deploying to AWS.
- Hosted: Dagster+: Serverless (they run everything) or Hybrid (control plane hosted, an agent runs compute in your K8s/ECS, deployed via the
dagster-cloud-agentHelm chart).
Guardrails and Pitfalls
Beyond deploying and operationalizing the orchestrator itself, there are related topics that cut across data orchestration, some of which we touched on in the open data platform architecture image in Part 1, where you see related tasks we need to deploy when wanting a full open data platform. The most important are testing and governance.
Governance & Testing
A deployment is only as trustworthy as the data it produces. With integrated data quality checks, we enforce assertions on every run instead of testing data after the fact, something a BI tool can't do, and the source can't either, because the business transformation hasn't happened yet. The data pipeline is exactly where the business rules live, so it's where domain experts can enforce checks and data types they know must hold.
With asset checks, this even extends to assets external to your pipelines. Yes, writing checks is extra work, but it makes the whole system more stable and less complex: numbers are known to be correct, and you avoid the downstream ad-hoc fixes that persist as duplicated data marts or gold-layer (if we use Medallion Layers).
Testing data isn't comparable to testing software, as data, tools, and volumes change between dev, test, and prod, and upstream from source data sources that we have no control over.
This is again where abstractions make life easier, e.g. Dagster separates business logic from technical implementation in resources. You can swap a mocked or local Postgres resource in dev for Snowflake in prod without touching pipeline code. Combined with the environment separation from our GitOps setup above, functional tests and balancing tests (does the count in the source match the warehouse?) can run in Continuous integration (CI) before a single git push ever reaches production.
Governance goes beyond quality checks: asset-level access controls, audit trails via metadata, column-level lineage for GDPR, and PII redaction in compute logs are the features that make a deployment enterprise-ready.
Obviously, testing and governance are their own domain and field, so that's worth another article, but I didn't want to leave it out, as it needs to be part of the strategy and best practices. For example, simply defining what your prefixes for table names in stage, or core, are, or how to name last_updated and created_date across the warehouse and deployment of your data platform or orchestration is key.
Provisioning and Multi-tenancy
Data orchestration is what Dagster is made for, but provisioning is something that fits well in the scope of using Dagster and deployment. As a pipeline rarely runs alone, it also needs an object store, a data catalog, maybe a Spark cluster. Provisioning these accompanying services is itself orchestration, and platform teams increasingly use Dagster for exactly that. It is also an advanced, observable cron for infrastructure. In several organizations, this started with data pipeline deployment, and spread across the company from there.
So without provisioning the needed compute engines or related tooling for your data pipeline, operationalizing the data orchestrator and the full open data platform is not complete. This is also where in larger companies this task usually falls to two different teams, data practitioners (teams of data engineers, analysts, or power users) and the data platform team. The two teams are different, but they have the same need to orchestrate their many tasks and jobs:
For enterprises, this pairs naturally with multi-tenancy and branch deployments: isolated environments that mirror production, so teams can review data pipeline changes like code PRs, and the GitOps workflow from the deployment chapter is applied to the data itself. A concrete example: Lakeflow Jobs can't express dependencies across Databricks workspace boundaries, but bringing every workspace into a single asset graph can.
Orchestration as the Operating System of Your Data Platform
Closing the initial Dagster Almanack with its guidance, insights and tips for data platform engineers, as with this operationalizing data orchestration guide on DevOps, Infra, and Code Locations in the shared task of deploying a full open data platform.
We have seen how to operationalize data orchestration, and what features Dagster can bring to the table. The best practices are to organize and deploy around git repositories and with separation of concerns in mind. When you think about deployment, always ask yourself where your storage of data assets will be, and how to compute them. This will define the best strategy for finding the best platform for deployment.
The open data platform deployment also helps escape the modern data stack trap. Dagster helps you integrate different tools in line with deployment strategies while separating workspaces for different teams and domain experts in an elegant way that works well with GitOps strategies. Exchanging compute engines and using the best tools for the task is just one config change away, and doesn't need to change the logic of the data pipeline itself.
With newer features such as state-backend components, Dagster uses these for integrations whose definitions depend on external metadata. Instead of re-querying external systems every time a code location loads, Dagster can fetch that state at controlled times, persist it, and then build definitions from the cached result.
It makes it a composable toolkit for data engineers out of the box and a single pane of glass for the data platform, incrementally adopted across teams and stakeholders. Tools are integrated into a single data platform, with a single deployment strategy, where multiple teams work together.
In the future with more shifting left, DataOps that combines this all under one domain, and with AI agents that govern and help create data pipelines, this foundational data platform is more critical than ever, integrating and scheduling all tasks in a structured and reliable way.





.jpg)
.png)



.png)

