


What is a dbt Snapshot?
dbt snapshots are a mechanism within dbt (data build tool) designed to track and preserve changes in data over time, which implements Type 2 Slowly Changing Dimensions for mutable tables. They allow users to maintain a historical record of how individual rows within a table evolve with updates.
Unlike models, which only reflect the latest state of your data, snapshots allow you to track historical versions of data as records are inserted, updated, or deleted. Think of snapshots as a method to analyze how your data has evolved without losing prior states.
When you define a snapshot in dbt, it automatically manages the logic for identifying when a record has changed and persists new versions to a snapshot table. These versions are annotated with metadata, such as validity timeframes and change timestamps, supporting robust historical analysis. Snapshots are especially valuable in analytics workflows where audits, change tracking, or time-based reporting is necessary.
Why Do We Need dbt Snapshots?
Operational data systems often overwrite records when updates occur. For example, when a customer changes their phone number or address, the old data is lost unless it’s explicitly preserved. This creates challenges for teams that need to track how data has changed over time.
Snapshots solve this problem by maintaining historical versions of records. This enables use cases such as:
- Tracking changes to customer data over time
- Analyzing how user behavior or segments evolve
- Ensuring compliance with audit requirements
- Recovering from incorrect updates in source systems
They are particularly useful for implementing slowly changing dimensions. While type 1 SCDs overwrite old data, type 2 SCDs retain historical versions. dbt snapshots make it straightforward to implement type 2 SCDs by automatically detecting changes and preserving previous states, eliminating the need for custom ETL logic.
How Snapshots Work in dbt
Snapshots in dbt follow a structured process to manage data versioning without manual intervention.
- Initial load: On the first snapshot run, dbt captures and writes the current state of the source table into a snapshot table. This creates a baseline version for each record.
- Change detection: On subsequent runs, dbt evaluates each record based on user-defined criteria (such as comparing field values or timestamps). If any relevant field has changed, dbt considers the record updated.
- Version creation: When a change is detected, the previous version of the record is marked with an end timestamp, and a new version is inserted with a new start timestamp. This process continues over time, building a full version history.
This setup allows teams to query the state of a record at any point in time, using the generated validity ranges. The snapshot logic abstracts the complexity of managing this historical tracking, making it easier to implement reliable data auditing and temporal analysis.
Snapshot Strategies in dbt
There are two main strategies you can use for dbt snapshots: timestamp and check.
Timestamp Strategy
The timestamp strategy is used when source records include a field that updates with every change—typically a last_updated or modified_at column. dbt uses this column to determine whether a record has changed since the last snapshot run.
To use this strategy, you specify the column in the snapshot configuration. dbt compares the stored value with the current value during each run. If the timestamp has advanced, dbt treats the record as updated, ends the previous version, and inserts a new version.
This strategy is efficient and avoids comparing all rows in the snapshot with the current state. However, it requires a reliable and consistently updated timestamp column in the source data. If the timestamp doesn’t change when data changes, updates may be missed.
Check Strategy
The check strategy works by comparing a subset of columns to detect changes. Instead of relying on a timestamp, dbt hashes the specified columns and checks whether the hash has changed since the last snapshot.
This approach is useful when no reliable update timestamp exists. You define which columns to check, and dbt automatically detects changes by comparing the current and previous hash values.
While more flexible, this strategy can be more computationally expensive, especially for wide tables or large datasets. It's important to select only the columns that are expected to change, to avoid unnecessary versioning.
Quick Tutorial: Add dbt Snapshots to Your DAG
This tutorial will show you how to add a snapshot to a dbt project. Instructions are adapted from the dbt documentation.
To add dbt snapshots to your DAG:
1. Start by creating a snapshot configuration file in the snapshots directory. This YAML file defines how dbt will detect and store changes to your source table over time. For example:
snapshots:
- name: sales_snapshot
relation: source('my_source', 'sales')
config:
schema: public_snapshots
database: analytics
unique_key: id
strategy: timestamp
updated_at: updated_at
dbt_valid_to_current: "timestamp '2030-12-31 00:00:00'"
This configuration tells dbt to monitor the sales source table, using the timestamp strategy to detect changes based on the updated_at column. The unique_key identifies each row uniquely, and dbt_valid_to_current sets a future date for currently valid records.
You can also preprocess data before snapshotting. If the source needs filtering or transformation, use an ephemeral model to define this logic:
-- models/ephemeral_table1.sql
{{ config(materialized='ephemeral') }}
select * from {{ source('my_source', 'sales') }}2. Then, point your snapshot to the model using ref('ephemeral_table1') in the relation field.
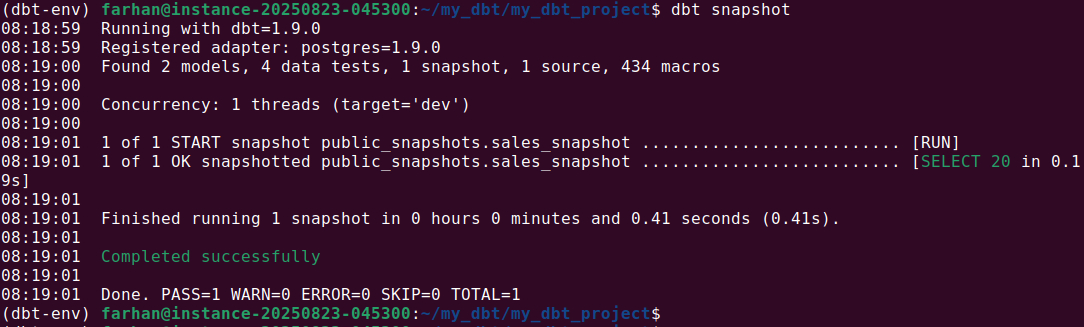
3. Once configured, run the snapshot with: dbt snapshot
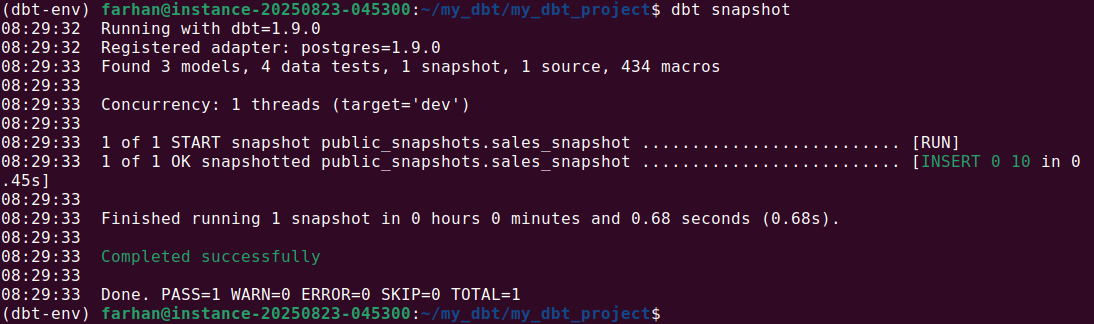
On the first run, dbt creates the snapshot table and captures the initial state of the data, adding metadata columns like dbt_valid_from and dbt_valid_to. On subsequent runs, dbt compares new data with the existing snapshot. If changes are detected, it closes out the previous record and inserts a new version with updated timestamps.
4. To use the snapshot in downstream models, reference it like any other model:
-- models/changed_sales.sql
select * from {{ ref('sales_snapshot') }}5. To keep snapshots useful, schedule the dbt snapshot command to run regularly, ensuring data changes are tracked consistently.
Best Practices for Using dbt Snapshots
Here are some useful tips to consider when using snapshots in dbt.
1. Clearly Define Snapshot Frequencies and Schedules
Snapshot frequency should match the rate at which your source data changes and the business requirements for change tracking. For example, if you're capturing updates to customer profiles that typically occur once a week, running snapshots hourly is wasteful. Conversely, for transactional data like orders that may change multiple times a day, daily or hourly snapshots ensure no updates are missed.
Use an orchestrator (like Dagster, Airflow, or dbt Cloud) to run dbt snapshot at regular intervals. Schedule snapshots during low-usage periods to reduce load on the warehouse. For critical datasets, consider incrementally increasing snapshot frequency and monitor whether the additional runs yield meaningful new versions.
Also, track snapshot freshness in your observability layer. This ensures teams are alerted if the snapshot task fails and historical data is not being captured on schedule.
2. Keep Snapshot Models Simple
Snapshot logic should focus solely on detecting and recording changes. Avoid embedding filters, joins, or transformation logic directly in the snapshot. Instead, create a dedicated staging or ephemeral model that prepares the data, and point the snapshot to that model using ref().
For example, if you need to snapshot only active customers, define a model like stg_active_customers with filtering logic, and configure the snapshot to reference it with
relation: ref('stg_active_customers')
This separation keeps snapshots maintainable, promotes reuse, and makes it easier to test or debug each part independently. Complex snapshots are harder to audit and more likely to fail silently.
3. Monitor Snapshot Performance and Storage Usage
Snapshots grow linearly with the number of changes in your data. A high-churn table will result in many historical versions being stored. Monitor row counts and table sizes regularly to understand growth patterns. You can query metadata tables (e.g., information_schema.tables or dbt artifacts) to track this over time.
Use partitioning, clustering, or table expiration (if supported by your warehouse) to manage growth. For example, in BigQuery, you can cluster snapshots by unique_key and partition by dbt_valid_from to improve query performance and reduce costs.
If storage becomes a concern, implement a retention policy to archive or delete versions older than a certain threshold, depending on your data governance requirements.
4. Establish Robust Data Quality Checks
Snapshots rely on accurate change detection. If the updated_at column doesn't update correctly or the unique_key isn’t truly unique, the snapshot logic will fail silently and produce bad data. Add tests in your dbt project to enforce these assumptions:
- Uniqueness tests on
unique_key - Non-null tests on key columns and timestamps
- Schema tests to detect unexpected column changes
- Custom tests to check for time gaps or overlapping validity ranges
You can also build monitoring queries that compare the number of snapshot records per key or detect unusual versioning patterns. This helps catch edge cases like out-of-order timestamps or duplicate entries early.
5. Use a Dedicated Schema for Snapshots
Place all snapshot tables in a separate schema, such as snapshots, to keep your warehouse organized and prevent confusion with models or source tables. This schema acts as a historical archive and allows for targeted access control.
For example, grant read-only access to analysts while restricting write access to snapshot tables. This prevents accidental data changes and ensures the integrity of historical records.
Additionally, using a dedicated schema makes it easier to manage lifecycle tasks—like truncating, backing up, or archiving snapshots—without affecting your production models or staging layers. If you need to replicate or export historical data, isolating it simplifies the process.
Orchestrating dbt Data Pipelines with Dagster
Dagster is an open-source data orchestration platform with first-class support for orchestrating dbt pipelines. As a general-purpose orchestrator, Dagster allows you to go beyond just SQL transformations and seamlessly connects your dbt project with your wider data platform.
It offers teams a unified control plane for not only dbt assets, but also ingestion, transformation, and AI workflows. With a Python-native approach, it unifies SQL, Python, and more into a single testable and observable platform.
Best of all, you don’t have to choose between Dagster and dbt Cloud™ — start by integrating Dagster with existing dbt projects to unlock better scheduling, lineage, and observability. Learn more by heading to the docs on Dagster’s integration with dbt and dbt Cloud.






.jpg)
.png)



.png)

