


What Is dbt (Data Build Tool)?
dbt, or Data Build Tool, is an open-source data transformation framework that enables data analysts and engineers to transform data in a data warehouse. It focuses on the transformation (T) step of ETL, allowing users to write data transformation workflows in SQL.
Users define transformation models within dbt, which then automatically handles their compilation, orchestration, and execution. This capability allows teams to transform raw data into a usable form without maintaining complex orchestration logic, ensuring that data processing becomes more accessible to those familiar with SQL.
The dbt workflow starts by connecting to a data warehouse, creating source models, and then building downstream models. It applies modular techniques, allowing users to reuse code and improve efficiency. This reduces duplicate work, improves collaboration among data professionals, and provides scalable, maintainable, and transparent data models.
Key Features of dbt
SQL-Based Transformation with Modular Code
dbt utilizes SQL for its data transformations, enabling a familiar and declarative approach to processing data. It encourages a straightforward method for data manipulation, making it accessible to data professionals who are already proficient in SQL. Users organize transformation logic into models, which helps reduce complexities.
These models maintain readability and modularity, which simplifies tracking changes and refining data pipelines. Modular design in dbt allows for easy code reuse, leading to cleaner and more maintainable code bases. It promotes reusability by abstracting common transformations into macros or functions. Users can then apply these macros across multiple models.
Version Control and Collaboration
Version control is integrated into dbt, utilizing Git's capabilities to maintain a history of changes, manage branching, and resolve conflicts. This integration supports collaboration among teams, as it allows multiple users to work simultaneously on the same project while tracking all alterations. dbt enables team members to review, test, and validate each other's work.
Users can structure dbt projects to align with their team's workflow, making it simple to involve multiple contributors and distribute tasks.
Testing and Documentation
dbt includes functionality for testing data to ensure accuracy and reliability throughout the transformation process. Users can define tests within their models, checking for anomalies or mismatches in data expectations. These tests capture errors early, leading to fewer data quality issues downstream. Regular testing ensures data remains reliable and maintains integrity, supporting consistent analytics and reporting.
The documentation is automatically generated and linked with the respective code, simplifying the tracking and auditing of data transformations. Users can annotate their models with markdown, providing context and improving understanding.
Easy Integration with Data Warehouses
dbt is compatible with various modern data warehouses such as Snowflake, BigQuery, Redshift, and others. It operates directly within the data warehouse, leveraging their processing power to execute SQL transformations. This eliminates the need for external processing environments, improving speed and reliability by utilizing the warehouse's capabilities directly.
Integration with data warehouses involves a simple configuration step within dbt, allowing users to quickly quickly to their data source. This means dbt can easily work alongside existing data infrastructure without significant changes, enabling efficient data transformations where data resides.
dbt Product Editions
dbt Core
dbt Core is the open-source version of dbt, for teams that prefer a self-managed approach to data transformation. It provides the core functionality of dbt, including SQL-based transformations, testing, and documentation. Users execute dbt commands via the command line, integrating it with version control tools like Git to manage model changes and collaboration.
Since dbt Core runs locally or within a custom environment, it requires users to set up their own infrastructure, including scheduling and orchestration. It is well-suited for organizations with existing deployment processes or teams comfortable managing their own workflows. Despite being free and open-source, dbt Core is capable of handling complex transformations.
dbt Cloud
dbt Cloud is a fully managed, web-based version of dbt that simplifies deployment and collaboration. It includes all the capabilities of dbt Core while adding features like a graphical user interface (GUI), job scheduling, integrated development environments (IDEs), and automated documentation. These improvements make it easier for teams to build, manage, and monitor their dbt workflows without needing to manage infrastructure manually.
dbt Cloud’s built-in scheduling and orchestration allow users to automate transformation workflows without relying on third-party tools. It also provides a more user-friendly experience, making dbt accessible to a wider range of users. Additionally, dbt Cloud offers enterprise features such as role-based access control (RBAC) and single sign-on (SSO).
Quick Tutorial: Running dbt Core with a Local DuckDB Database
This tutorial will guide you through setting up a GitHub Codespace to run dbt Core. By the end, you will have a fully functional dbt environment, connected to a DuckDB database, loaded with sample data from a fictional café called Jaffle Shop. These instructions are adapted from the dbt documentation.
Prerequisites
Before you begin, ensure that you:
- Have a GitHub account
- Are familiar with basic command-line navigation (commands like cd, ls, and pwd)
Step 1: Create a Codespace
- Log into your GitHub account and navigate to the jaffle_shop_duckdb repository.
- Click Use this template and choose Create new repository.
- Once the repository is created, click Code, then go to the Codespaces tab and select Create codespace on main.
- Wait for the postCreateCommand to complete, which will set up the development environment. Once done, a new terminal window will open, ready for commands.
Step 2: Run dbt Commands
Once your codespace is ready, you can execute dbt commands from the terminal.
To build your dbt project, run:
dbt buildThis command:
- Compiles the dbt models into executable SQL
- Runs the transformations
- Tests the results to ensure data quality
Other useful dbt commands include:
dbt compile # Generates executable SQL from project files
dbt seed # Create the source tables using the CSV seed files
dbt run # Compiles and runs the project
dbt test # Runs tests on the transformed data Step 3: Query Data Using duckcli
To explore your data warehouse directly from the terminal, use duckcli:
duckcli jaffle_shop.duckdbThis allows you to write SQL queries against the DuckDB database and explore the models created by DBT.
With this setup, you now have a fully functional dbt environment running in GitHub Codespaces. You can start modifying models, writing transformations, and analyzing data directly from your browser.
Key Limitations of dbt
While dbt is useful for data transformation, it has certain limitations that users should be aware of before adopting it. These limitations were reported by users on the G2 platform:
- Steep learning curve: dbt requires a shift in mindset, particularly for those coming from traditional data modeling tools. Users need to understand dbt’s structured approach to modeling and modularizing SQL with CTEs. Beginners may find it difficult to get started without prior SQL knowledge.
- Limited Python support: While dbt allows data modeling in Python, its functionality depends on the data platform being used. This means some warehouses have better Python support than others, limiting flexibility for certain workflows.
- No built-in scheduler: dbt does not have an integrated scheduling system for automating workflows. Users must rely on external tools like Dagster, Airflow, or Prefect to schedule dbt runs.
- Batch processing only: dbt operates in batch mode, meaning it cannot be used for real-time data transformations. This makes it unsuitable for streaming or event-driven use cases.
- Development environment limitations: The dbt Cloud IDE lacks some features found in other SQL development environments, which can make development less efficient. However, new features are being rolled out with each release.
- Difficult log navigation: The Job Runs tab in dbt Cloud is not intuitive for debugging. Finding and interpreting logs to troubleshoot issues can be cumbersome.
- High data warehouse load: Since dbt runs transformations directly in the data warehouse, it can lead to increased processing costs and slower query performance if models are not optimized.
- Lack of visual data modeling: dbt is heavily code-focused and does not provide strong visual tools for data modeling. Users who prefer graphical representations may find this limiting. However, new features like dbt Canvas are enabling visual approaches to data modeling.
- Limited integration with external tools: While many data tools (like Fivetran and Monte Carlo) work well with dbt, dbt itself does not always integrate seamlessly with these tools. More built-in support for external integrations could improve its usability.
- Inconsistent documentation and support: The documentation process could be improved to make onboarding easier. Some users have also reported slow customer support response times.
Related content: Read our guide to dbt cloud alternatives (coming soon)
5 Best Practices for Effectively Using dbt
Here are some useful practices to keep in mind when using dbt.
1. Organizing the Project Structure
A well-organized project structure is critical for scaling and maintaining dbt projects. Start by grouping models logically: such as by subject area or data domain: to improve clarity and manageability. Consistent naming conventions for directories and model files ensure that all team members can identify components quickly and understand the structure.
Documentation and README files should accompany project structures to offer guidance on navigating and understanding the project setup. Clear documentation aids teams in maintaining consistency in modeling practices and helps new team members integrate smoothly into ongoing projects.
2. Implementing Tests and Documentation
Implementing tests within dbt models is vital to ensure data reliability throughout the pipeline. Tests should check for expected outcomes, such as row counts or specified constraints, validating model logic. Regular testing helps quickly spot and rectify issues, maintaining high confidence levels in data quality.
Consistent documentation improves the comprehension and tracking of dbt models. By documenting transformation logic, rationale, and associated tests, teams ensure transparency and accountability. dbt's automated documentation aids these efforts, generating records of model lineage and logic.
3. Using Macros and Jinja for Code Reuse
Macros allow users to abstract repetitive SQL logic into reusable functions, which can be invoked across different models. This approach minimizes code duplication, enables standardization, and accelerates development by allowing teams to focus on unique transformation logic rather than repetitive coding tasks.
Jinja templating complements macros by enabling dynamic SQL generation, catering to complex transformation scenarios. It allows injecting variables and conditional logic into SQL statements, increasing flexibility and adaptability of models. By using Jinja, organizations improve their ability to dynamically scale transformation logic and adapt to new requirements.
4. Managing Environments with Version Control
Version control is important for managing environments, especially in multi-developer setups. Git enables commit logging, branching, and merging that reflect changes in model logic, allowing team members to work independently and integrate their changes. It ensures that transformations are tracked over time, maintaining clarity over the evolution and rationale for alterations.
With segregated environments, such as development, staging, and production, version control ensures consistency across different models and transformations. Branch-specific modeling and testing preserve existing resources while allowing iterative development. dbt's integration with version control leads to a disciplined approach in managing environments.
5. Automating Deployments and CI/CD
Automating deployments with continuous integration and continuous deployment (CI/CD) frameworks improves the reliability and efficiency of dbt projects. Incorporating CI/CD introduces automated testing and validations as part of the deployment pipeline, ensuring models adhere to predefined standards before entering production environments.
This methodology reduces manual intervention, lowering the risk of errors and increasing deployment speed. CI/CD enables seamless transitions from development to production, ensuring tested and validated transformations are consistently deployed. Automated deployments can be configured to trigger on specified events, such as code commits or merge requests.
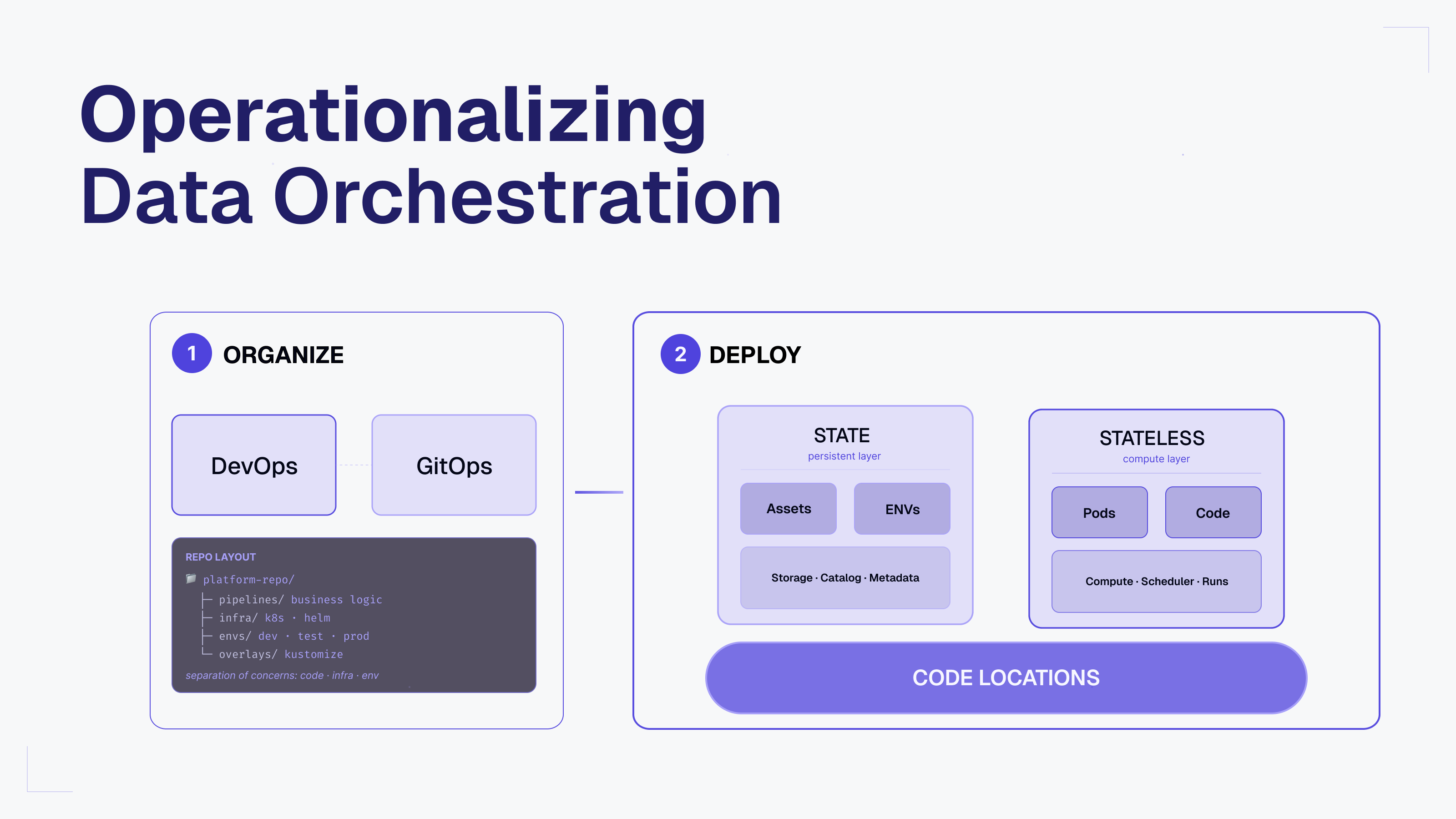
Setting Up Effective dbt Workflows with Dagster
Dagster is an open-source data orchestration platform with first-class support for orchestrating dbt pipelines. As a general-purpose orchestrator, Dagster allows you to go beyond just SQL transformations and seamlessly connect your DBT project with your wider data platform.
It offers teams a unified control plane for not only dbt assets, but also ingestion, transformation, and ML workflows. With a Python-native approach, it unifies SQL, Python, and more into a single, testable, and observable platform.
Best of all, you don’t have to choose between Dagster and dbt Cloud™ — start by integrating Dagster with existing dbt projects to unlock better scheduling, lineage, and observability. Learn more by heading to the docs on Dagster’s integration with dbt and dbt Cloud.






.jpg)
.png)


.png)

