


What Is a dbt Python Model?
A dbt Python model is a type of transformation within the dbt (data build tool) ecosystem that lets developers write business logic using Python, instead of SQL. Traditionally, dbt has relied on SQL-based transformations for analytics engineering, but with the support for Python models, users can execute Python code directly in data warehouses that support external languages, such as Snowflake, Databricks, and BigQuery.
This extension bridges the gap between analytics engineering and data science, allowing for more complex data transformations and machine learning operations natively within dbt workflows. Python models in dbt are defined as .py files within the models directory of a dbt project. These scripts have access to input data as data frames, and allow the use of libraries like pandas or PySpark, depending on the data warehouse.
The outputs are written directly back to the warehouse, enabling the results to be queried and joined just like any other table or view produced by SQL models. This integration keeps workflows consistent across SQL and Python, enabling teams to leverage both languages as needed for complex analytics requirements.
Pros and Cons of Running Python in dbt
Here are a few reasons to use Python in dbt:
- Python has a rich ecosystem of libraries and tools, and supports a wide range of data processing and machine learning workflows, which SQL alone can't handle efficiently. This makes it easier to implement transformations, statistical models, or predictive analytics directly in the warehouse.
- Python models return data frames rather than SQL query results, enabling flexible manipulation using tools like pandas or PySpark. This makes it easier to work with complex data types or apply custom business logic.
- Python models integrate with dbt's existing structure, so they support referencing sources and models with dbt.ref() and dbt.source(), just like SQL models. Materialization options like table and incremental are also supported, allowing Python models to fit into standard dbt workflows.
Here are some limitations and drawbacks to be aware of:
- dbt’s Python support is currently limited to just three platforms—Snowflake, Databricks, and BigQuery. Users must rely on these platforms' ability to execute Python code, meaning local development or execution isn't possible. This reliance also adds overhead in terms of setup and environment management.
- Performance is another concern. Translating efficient SQL models into Python doesn't always yield good performance. Python offers many ways to write the same logic, and inconsistent coding practices can lead to slower models.
- As of the time of this writing, dbt Python models don’t work with dbt Fusion, the next-generation rewrite of dbt with a significantly improved developer experience.
How Does dbt Interpret Python Code?
When you run a Python model in dbt, the code isn't executed locally. Instead, dbt relies on the data warehouse's cloud services to interpret and execute the Python code. This design ensures that all transformations occur inside the warehouse, avoiding data movement and eliminating the need for updates or synchronization.
- On Snowflake, dbt uses the Snowpark API to handle Python models. The Python code is compiled by dbt, passed to Snowflake, and executed as a stored procedure. The entire computation runs within Snowflake’s environment, keeping the data in place.
- For BigQuery, dbt uses Dataproc, which provides managed Hadoop and Spark clusters to process Python code.
- Databricks integrates with dbt through the dbt-databricks adapter, which supports running Python models using PySpark. When a Python model is executed, dbt compiles the code and submits it to a Databricks cluster where it runs within a Spark session. This allows the model to process data in parallel across distributed nodes, leveraging Spark's scalability.
These cloud services are optimized for large-scale data workloads. However, they introduce considerations such as costs, cluster sizing, storage configuration, and network access. To ensure reliable performance, users must manage these factors according to the demands of their Python models.
Tutorial: Defining and Configuring dbt Python Models with Snowpark
Prerequisites
To define a Python model in dbt, and run the Python code on your data using Snowflake’s Python API, first create a .py file in the models/ directory. Each file must include a function named model(dbt, session). The dbt parameter provides access to project context and references, while session represents the warehouse connection, used to read and write data as data frames.
Inside the function, use dbt.ref() or dbt.source() to load upstream models or source tables as data frames.
Performing transformations with Python
Perform your transformations using pandas, PySpark, or the platform-specific DataFrame API, and return a single DataFrame as the output. This returned DataFrame is what dbt will write back to the data warehouse.
from snowflake.snowpark.functions import col
def model(dbt, session):
dbt.config(materialized="table")
orders_df = dbt.ref("fct_orders") # ref to an existing model/table
filtered_df = orders_df.filter(col("status") == "completed")
return filtered_df
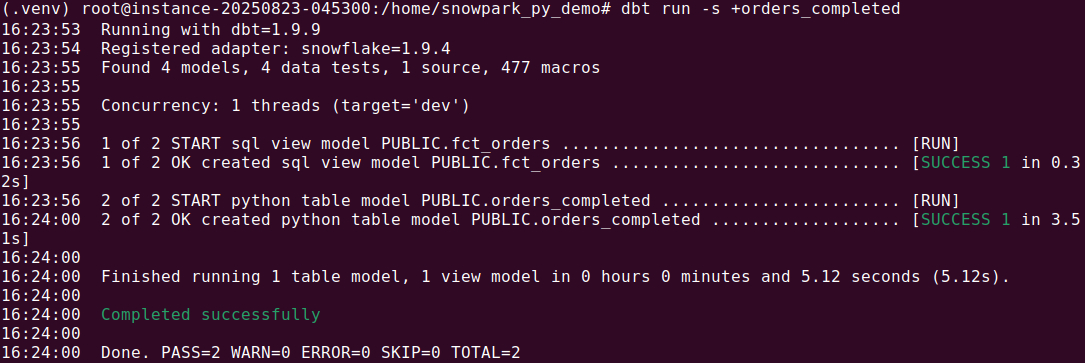
Options for configuring Python models
You can configure Python models in three ways:
- Inside
dbt_project.ymlto set defaults for multiple models - In a YAML file in the
models/folder for per-model settings - Inline in the
.pyfile usingdbt.config()
Only literal values (like strings, numbers, and booleans) can be passed to dbt.config(). More complex configurations should be placed in a YAML file and accessed via dbt.config.get() in your model code, like this:
# models/config.yml
version: 2models:
- name: my_python_model
config:
materialized: table
target_name: "{{ target.name }}"
# models/my_python_model.py
def model(dbt, session):
target_name = dbt.config.get("target_name")
df = dbt.ref("orders")
if target_name == "dev":
df = df.limit(500)
return dfUsing materializations
Python models support table and incremental materializations. To build incremental models, use dbt.is_incremental to conditionally filter for new data.
def model(dbt, session):
dbt.config(materialized="incremental") # Materialization type
df = dbt.ref("events") # Reference source table (can be a model or source)
if dbt.is_incremental:
# Get max timestamp from existing incremental table
max_ts_query = f"SELECT MAX(event_time) FROM {dbt.this}"
max_ts = session.sql(max_ts_query).collect()[0][0]
if max_ts:
# Filter only new data
df = df.filter(df["event_time"] > max_ts)
return df
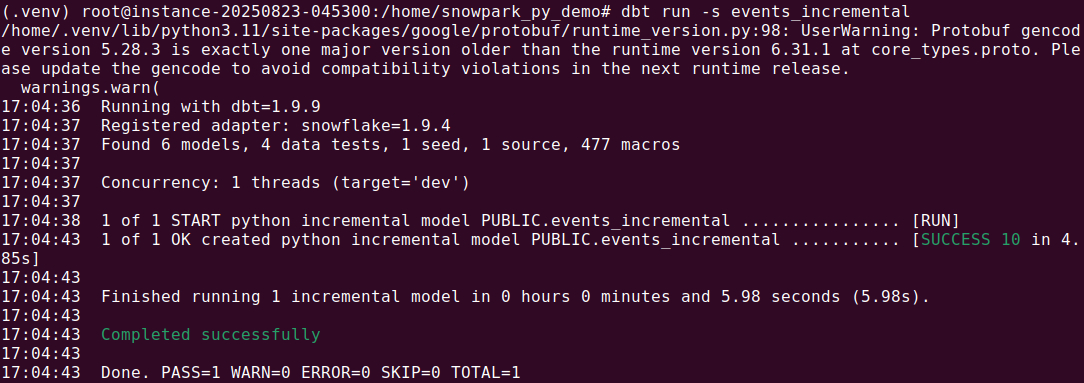
Using helper functions and Python packages
You can also define helper functions within the model or import third-party packages. To use packages, list them via dbt.config(packages=...) or in the model YAML.
import holidays
def is_holiday(date):
return date in holidays.France()
def model(dbt, session):
dbt.config(materialized="table", packages=["holidays"])
df = dbt.ref("calendar").to_pandas()
df["IS_HOLIDAY"] = df["DATE"].apply(is_holiday)
return df

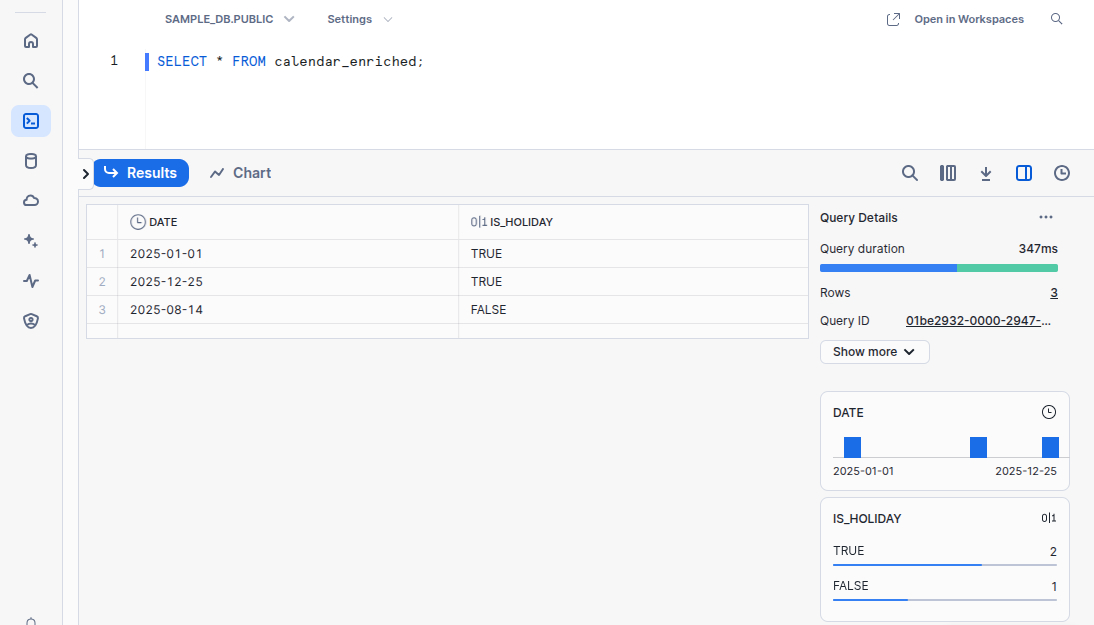
While Python models offer flexibility, note that functions can't yet be reused across models. UDF support is platform-dependent, and currently limited on some warehouses like Snowflake.
Best Practices for Running Python in dbt
Here are some useful practices to keep in mind when dbt for Python code.
1. Use Native Warehouse Data Frames
Always prefer the native DataFrame API provided by your data platform—such as Snowpark on Snowflake, PySpark on Databricks, or BigQuery’s Spark interface—over pandas. These APIs allow computations to run directly on the warehouse engine, which is optimized for distributed processing and avoids pulling large datasets into Python memory.
For example, with Snowpark, you can use .filter(), .withColumn(), or .join() to perform operations directly in Snowflake’s execution layer. Converting to pandas with .to_pandas() should be reserved for small datasets or operations not supported by the native API. Pulling data into pandas bypasses warehouse execution, introduces memory constraints, and slows performance due to serialization and data transfer overhead.
2. Keep Your Python Models Well-Structured
Structure your model code for clarity and maintainability. Keep your main model(dbt, session) function focused and concise. Move non-trivial logic into helper functions defined within the same file, and isolate configuration retrieval at the top of the script. For example:
def transform_orders(df):
return df.filter(df["status"] == "completed")
def model(dbt, session):
dbt.config(materialized="table")
orders_df = dbt.ref("fct_orders")
return transform_orders(orders_df)
Avoid deeply nested logic or large, monolithic functions. Name variables clearly and consistently, and use comments to document complex operations or business-specific logic. Following these conventions reduces onboarding time for new team members and makes debugging easier.
3. Testing the Python Models
dbt allows you to test the integrity of your data transforms using data tests, including the built-in generic tests, such as unique, not_null, or accepted_values. These tests are defined in your model’s .yml file and dbt will ensure that your model outputs satisfy these requirements after the Python model is materialized.
dbt currently doesn’t support unit tests for Python models. Since dbt executes Python models only in the data platform’s custom execution environment, locally testing the logic of Python models during development is not possible without mocking dbt’s Python interface.
4. Integration with SQL Models
Python and SQL models in dbt are fully interoperable through dbt.ref() and dbt.source(). This allows Python models to read data from upstream SQL transformations, or to feed downstream SQL models. Ensure the naming conventions and materialization types are compatible. For example, avoid using ephemeral models as inputs to Python models since they are not materialized as physical tables.
5. Implement Proper Error Handling in Your Python Models
Python models are susceptible to runtime errors, especially when querying external data or performing complex transformations. Wrap risky logic in try-except blocks to catch and log exceptions. For example:
try:
df = dbt.ref("events")
result = df.filter(df["event_type"] == "click")
except Exception as e:
raise Exception(f"[{dbt.this}] Failed to process events: {e}\n{tb}") from e

Always validate inputs and outputs. For example, check that input DataFrames are not empty and required columns are present before proceeding. If using dynamic SQL via session.sql(), verify the result shape and handle edge cases like None values or unexpected schema changes.
Related content: Read our guide to dbt test (coming soon)
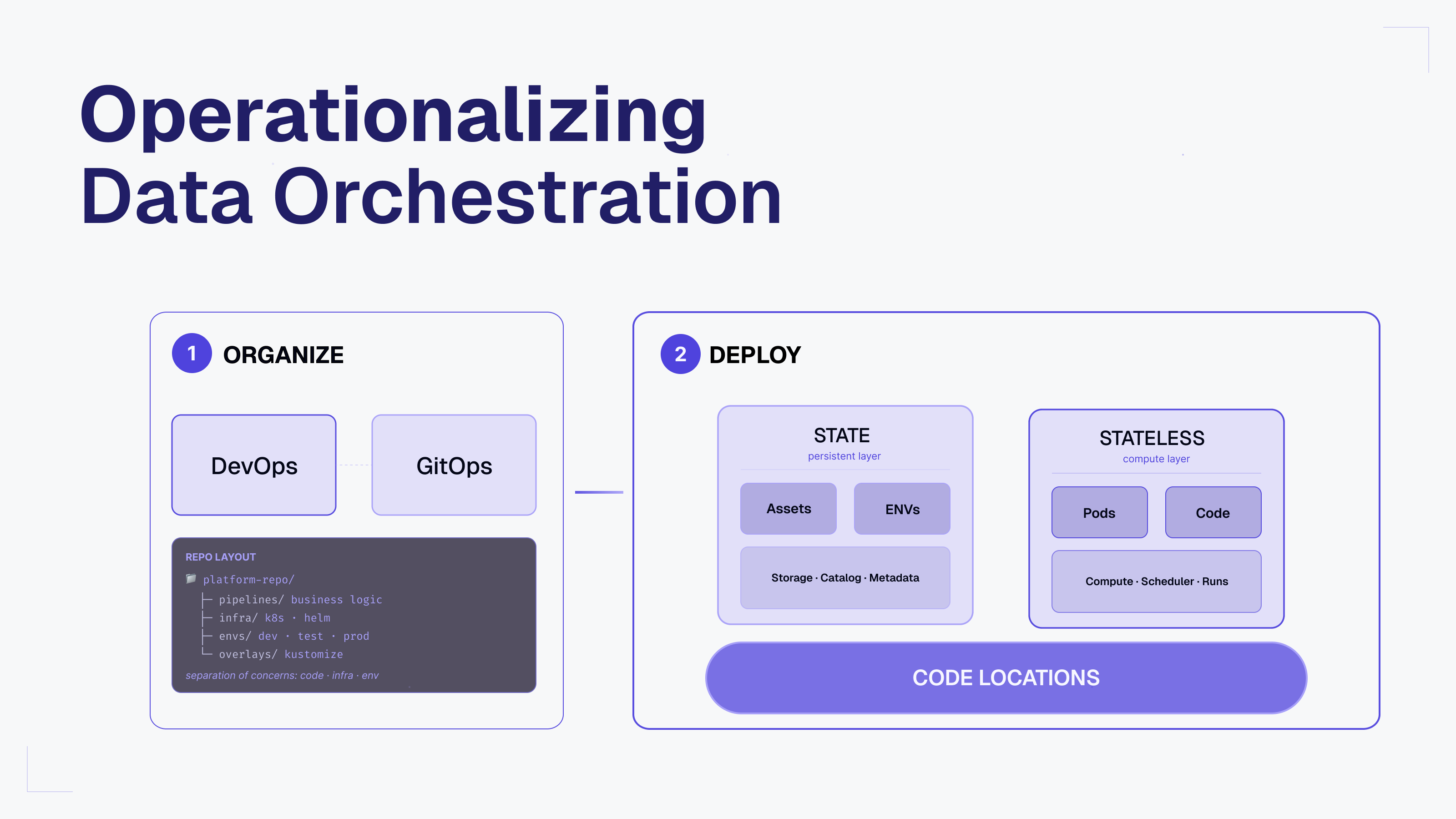
Orchestrating dbt Data Pipelines with Dagster
Dagster is an open-source data orchestration platform with first-class support for orchestrating dbt pipelines. As a general-purpose orchestrator, Dagster allows you to seamlessly expand your data platform to include Python-based data assets, while allowing dbt to focus on what it does best: SQL transformations.
Unlike dbt, which provides only limited visibility into Python models and a sub-par testing and developer experience for Python models, Dagster was built from the ground-up to run Pythonic data flows.
It offers teams a unified control plane for not only dbt assets, but also ingestion, transformation, and ML workflows. With a Python-native approach, it unifies SQL, Python, and more into a single, testable, and observable platform.
Best of all, you don’t have to choose between Dagster and dbt Cloud™ — start by integrating Dagster with existing dbt projects to unlock better scheduling, lineage, and observability. Learn more by heading to the docs on Dagster’s integration with dbt and dbt Cloud.






.jpg)
.png)


.png)

