


What Is dbt Unit Testing?
dbt unit tests are a feature within dbt (data build tool) that enable the validation of a dbt model's SQL logic in isolation, using a small, controlled set of static input data. Unit tests are different from dbt's traditional data tests, which run assertions against live data, typically the outputs of materialized models in a production environment.
dbt unit tests let you catch logical flaws or regressions early, ensuring your transformations produce correct results under different scenarios. It’s analogous to unit testing in software engineering: you want precise, repeatable confirmation that a piece of logic works in isolation before it’s part of a larger pipeline.
In dbt, unit testing has become more practical with improvements in dbt Core, the introduction of generic tests, and increased community-driven support for seed data and macros. Unit tests can simulate edge cases, verify business logic, and catch problems that might not be evident using only data tests.
The Need for dbt Unit Tests: Why Data Tests Are Not Enough
While dbt's built-in data tests are useful for catching data quality issues like null, duplicate, or invalid values, they come with limitations that reduce their effectiveness at scale:
- dbt data tests validate assertions against live datasets: This means the results can change unpredictably as either the data or the transformation logic changes. When a test fails, it’s often unclear whether the problem lies in the data itself or in recent code changes, making debugging more difficult.
- These tests can be slow and resource-intensive: Running checks on large tables, especially with multiple assertions across many columns, can consume significant compute and extend pipeline run times. This makes it hard to run them frequently, especially in development environments.
dbt unit tests use fixed input and output data, allowing them to run quickly and deterministically. They provide targeted validation of transformation logic without depending on the current state of the data. This makes unit tests a more scalable and precise tool for verifying business rules and preventing regressions in complex pipelines.
When to Add a dbt Unit Test to Your Model
You should add unit tests when your model has any of these characteristics:
- Includes logic that is complex or error-prone. This includes SQL that uses regex, date math, window functions, or long
case whenchains. - Is mission critical, such as public-facing models, models bound by contracts, or ones that sit directly upstream of exposures. Testing here helps prevent downstream issues where errors would have a bigger impact.
- Uses truncation or other custom transformations that go beyond built-in functions.
- Handles logic that caused issues in the past or involves edge cases that might not always appear in production data.
- Is under active development and you are concerned about regressions. Unit tests can help ensure refactoring doesn’t break expected behavior, especially during significant rewrites.
When you should not use unit testing
dbt Labs advises running unit tests in development or CI only, since they rely on static inputs and do not add value in production runs. They can be excluded from production builds with the --exclude-resource-type flag or the DBT_EXCLUDE_RESOURCE_TYPES variable to save compute.
Limitations of unit testing in dbt
While dbt unit tests bring advantages for validating transformation logic, they also have some limitations to consider:
- Setup overhead: Defining mocked inputs and expected outputs requires extra effort compared to data tests, especially for complex models with many dependencies. This can slow down adoption if teams don’t establish clear patterns or reusable test frameworks.
- Maintenance burden: As business logic evolves, seed or mock data used in unit tests must also be updated. Out-of-date tests can become noisy, producing false failures or being ignored altogether.
- Limited real-world coverage: Unit tests are only as strong as the scenarios you anticipate. They won’t catch unexpected edge cases in production data unless those cases are explicitly mocked.
- Not a replacement for data tests: Unit tests validate logic but don’t ensure data quality or freshness in real datasets. They must be complemented by dbt’s schema and data tests to provide end-to-end coverage.
- Tooling gaps: Compared to software engineering ecosystems, dbt’s testing framework is still maturing. Features like debugging tools, test discovery, and built-in mocking utilities are less mature, requiring workarounds or community packages.
Quick Tutorial: Unit Testing a Model in dbt
In this tutorial we’ll show how to add a unit test to a regular dbt model and a more complex incremental model. The instructions are adapted from the dbt documentation.
Unit Testing a Regular dbt Model
Suppose you create a dim_customers model that includes a field is_valid_sku to check whether a customer’s SKU is valid. The logic uses a regex pattern (for example, enforcing ^PROD-[A-Z0-9]{5,8}$) to verify the SKU structure and joins against a table of production_skus to ensure that the value exists in the authoritative list of products.
Because regex checks and SKU lookups are easy to get wrong, this is a good candidate for unit testing. You can define a test with controlled inputs and expected outputs to confirm that the logic works across common edge cases: SKUs missing the PROD- prefix, SKUs that are too short or too long, or SKUs that don’t appear in the production_skus table.
Step 1: A unit test for this model might look like this:
unit_tests:
- name: test_is_valid_sku
description: "Ensure SKU validation logic handles edge cases"
model: dim_customers
given:
- input: ref('stg_customers')
rows:
- {customer_id: 1, customer_name: Alice, sku: "PROD-ABC12"}
- {customer_id: 2, customer_name: Bob, sku: "PROD-FOO777"}
- {customer_id: 3, customer_name: Charlie, sku: "PROD-BAD"}
- {customer_id: 4, customer_name: Dana, sku: "prod-ABC12"}
- {customer_id: 5, customer_name: Emre, sku: "ABC12345"}
- {customer_id: 6, customer_name: Fay, sku: "PROD-123456789"}
- {customer_id: 7, customer_name: Grace, sku: null}
- input: ref('production_skus')
rows:
- {sku: "PROD-ABC12", active: true}
- {sku: "PROD-XYZ789", active: true}
- {sku: "PROD-12345", active: true}
- {sku: "PROD-HELLO1", active: true}
- {sku: "PROD-FOO777", active: false}
expect:
rows:
- {sku: "PROD-ABC12", is_valid_sku: true} # exists + regex OK
- {sku: "PROD-FOO777", is_valid_sku: false} # regex OK but inactive
- {sku: "PROD-BAD", is_valid_sku: false} # too short
- {sku: "prod-ABC12", is_valid_sku: false} # lowercase prefix
- {sku: "ABC12345", is_valid_sku: false} # missing prefix
- {sku: "PROD-123456789",is_valid_sku: false} # too long
- {sku: null, is_valid_sku: false} # null not allowedHere, you define mock input tables for stg_customers and production_skus, then specify the expected results. This lets you confirm that only valid SKUs pass and all invalid cases are caught.
Step 2: Before running the unit test, you need to make sure the direct parents of your model exist in the warehouse. You can do this without incurring large compute costs by creating empty versions:
dbt run --select "stg_customers production_skus" --empty
Step 3: Then you can run the test with one of several commands, depending on how specific you want to be:
dbt test --select dim_customersruns all tests ondim_customers.dbt test --select "dim_customers,test_type:unit"runs only unit tests for the model.dbt test --select test_is_valid_skuruns just this single test.
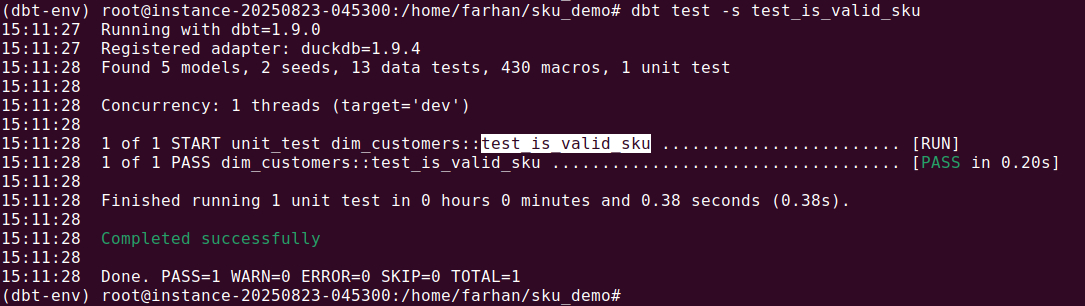
Step 5: If a test fails, dbt shows a diff between actual and expected results.
By catching the bug before materializing the model in the warehouse, the unit test saved time and ensured the logic was correct. This same process can be extended to incremental models or models depending on ephemeral inputs by overriding macros, variables, or using inline SQL for fixtures.
Unit Testing Incremental Models
Incremental models introduce another layer of complexity because their behavior depends on whether they are run in full refresh or incremental mode. You can unit test both cases by overriding the is_incremental macro, and in the case of an incremental update, passing a this input representing the current state of the incremental model in your test configuration.
unit_tests:
- name: int_customers_valid_skus_full_refresh_mode
description: "Full refresh should load all rows with valid SKUs"
model: int_customers_valid_skus
overrides:
macros:
is_incremental: false
given:
- input: ref('stg_customers')
rows:
- {customer_id: 1, customer_name: Alice, sku: "PROD-ABC12"}
- {customer_id: 2, customer_name: Bob, sku: "PROD-XYZ789"}
- {customer_id: 3, customer_name: Charlie, sku: "PROD-BAD"} # invalid (regex)
- input: ref('production_skus')
rows:
- {sku: "PROD-ABC12", active: true}
- {sku: "PROD-XYZ789", active: true}
expect:
rows:
- {customer_id: 1, customer_name: Alice, sku: "PROD-ABC12"}
- {customer_id: 2, customer_name: Bob, sku: "PROD-XYZ789"}
- name: int_customers_valid_skus_incremental_mode
description: "Incremental should only insert new valid rows beyond existing max customer_id"
model: int_customers_valid_skus
overrides:
macros:
is_incremental: true
given:
- input: ref('stg_customers')
rows:
- {customer_id: 1, customer_name: Alice, sku: "PROD-ABC12"}
- {customer_id: 2, customer_name: Bob, sku: "PROD-XYZ789"}
- {customer_id: 3, customer_name: Charlie, sku: "PROD-HELLO1"}
- {customer_id: 4, customer_name: Dana, sku: "PROD-BAD"} # invalid (regex)
- input: ref('production_skus')
rows:
- {sku: "PROD-ABC12", active: true}
- {sku: "PROD-XYZ789", active: true}
- {sku: "PROD-HELLO1", active: true} # simulate existing target table rows
- input: this
rows:
- {customer_id: 1, customer_name: Alice, sku: "PROD-ABC12"}
expect:
rows:
- {customer_id: 2, customer_name: Bob, sku: "PROD-XYZ789"} # new + valid
- {customer_id: 3, customer_name: Charlie, sku: "PROD-HELLO1"} # new + valid
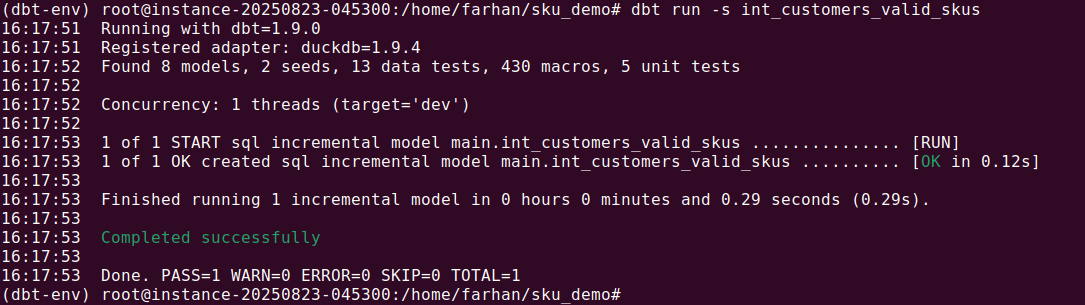
In these tests, we use the overrides.macros.is_incremental property to to simulate whether the model is running as incremental or full refresh. The expected results match only the rows that would be newly inserted or updated during that run. This ensures your incremental logic is tested without needing a full warehouse build.
Best Practices for Implementing Unit Testing in dbt
Here are some useful practices to keep in mind when using dbt unit tests.
1. Integrate Tests into the Development Workflow
Integrate unit tests directly into your feature development lifecycle. When adding or modifying a model, write unit tests that confirm the logic works as intended before pushing changes. This helps prevent regressions early and builds confidence that your changes won’t break downstream dependencies.
In CI environments, configure your pipelines to run unit tests using flags like --select state:modified test_type:unit to test only changed models. This keeps feedback loops fast without the overhead of running every test on every model. Also, consider running unit tests locally as a first step before any dbt run or full test suite.
You can also enforce unit test coverage in code reviews by requiring that all business logic changes come with corresponding tests. This ensures the testing habit becomes part of your team's culture and reduces the likelihood of missing important edge cases.
Note: It’s important to make sure unit tests are not included as part of production runs of dbt, because they can introduce overhead and interfere with production runs. They should only run as part of CI/CD processes, to ensure SQL code is ready for production.
2. Isolate Logic into Modular Models
Splitting logic into modular components makes unit testing easier and your dbt project more maintainable. Each model should handle a specific part of the transformation pipeline, for example, data cleaning, filtering, joining, or enrichment.
Avoid bundling multiple business rules into a single final model. Instead, create intermediate models that represent discrete steps in the logic. For example, if your final model calculates customer lifetime value, split it into:
- A staging model for cleaned transactions
- A model that aggregates customer spend
- A final model that adds calculated metrics
Each of these can be tested independently with focused unit tests. Smaller models with narrow scopes are easier to understand, debug, and validate.
3. Organize Tests Clearly
Good organization of unit tests helps teams maintain clarity as projects scale. Place unit tests in a structured directory like tests/unit/<model_name>/ and name them based on the logic they validate. For instance, for a model dim_customers, you might create:
test_sku_validation.ymltest_age_brackets.ymltest_loyalty_score_calculation.yml
Within each YAML file, separate tests using clear description fields and make use of tags to categorize them by model or test type. This allows you to select subsets of tests for faster runs using dbt test --select tag:customer_tests.
Also, include comments or documentation in your test definitions explaining what each test is validating. This reduces the learning curve for new developers and helps future maintainers understand why a test exists.
4. Use Seed Data for Input Mocking
Seed files offer a scalable way to mock input datasets for your unit tests. Instead of writing row-level mocks directly in your test YAML, place your inputs in CSV files under data/ and load them into the warehouse using dbt seed.
This is especially useful when:
- You need to reuse the same input data across multiple tests
- Your test inputs include many columns or rows, making inline YAML verbose
- You're testing models that rely on static reference data like country codes or product catalogs
Using seeds makes test setup clearer and avoids duplication. For example, if multiple tests rely on a fixed production-skus.csv, you only need to define it once. You can still override or extend it in individual tests as needed.
To maintain clarity, version seed files with your models and include them in your CI pipeline setup to ensure tests have all the required context to run.
5. Make Use of dbt run-operation for Test Setup and Teardown
dbt run-operation allows you to call custom macros before or after tests to prepare your environment. This is especially useful in automated pipelines where you need to control the state of your test schema.
For setup, you might create a macro that truncates or recreates schemas, seeds test-specific tables, or ensures certain environment variables are set. For teardown, you can clean up temporary tables or reset materialized views that could interfere with other runs.
Example macro:
-- macros/reset_test_schema.sql
{% macro reset_test_schema(schema_name) %}
{% set sql %}
drop schema if exists {{ schema_name }} cascade;
create schema {{ schema_name }} ;
{% endset %}
{% do run_query(sql) %}
{% endmacro %}
You could then call this with:
dbt run-operation reset_test_schema --args '{"schema_name": "dbt_unit_tests"}'
Automating this setup and teardown removes manual steps and ensures consistency across local and CI runs. It also enables parallel testing by isolating tests in separate schemas when needed.
Orchestrating dbt Data Pipelines with Dagster
Dagster is an open-source data orchestration platform with first-class support for orchestrating dbt pipelines. As a general-purpose orchestrator, Dagster allows you to go beyond just SQL transformations and seamlessly connect your dbt project with your wider data platform.
It offers teams a unified control plane for not only dbt assets, but also ingestion, transformation, and AI workflows. With a Python-native approach, it unifies SQL, Python, and more into a single testable and observable platform.
Best of all, you don’t have to choose between Dagster and dbt Cloud™ — start by integrating Dagster with existing dbt projects to unlock better scheduling, lineage, and observability. Learn more by heading to the docs on Dagster’s integration with dbt and dbt Cloud.






.jpg)
.png)



.png)

