


Data linearizing - a definition
Linearizing data is a process where the relationship between variables in a dataset is transformed or adjusted to make it linear or approximately linear. This transformation is often done in data engineering to simplify analysis, improve model performance, or meet assumptions of certain statistical methods.
Methods for linearizing data can vary depending on the nature of the dataset and the specific goals of the analysis. Common techniques include logarithmic transformations, exponential transformations, polynomial transformations, and Box-Cox transformations. Additionally, feature engineering techniques can be employed to create new linear combinations of variables that better capture the underlying relationships in the data.
When to use data linearizing in data engineering
Linearizing data can be useful in data engineering for several reasons:
Data Modeling: Many statistical and ML models assume a linear relationship between variables. By linearizing the data, we can make these models more applicable and effective. And example here is ANOVA (Analysis of Variance): ANOVA tests for significant differences in the means of two or more groups. In its simplest form (one-way ANOVA), it assumes a linear relationship between a categorical independent variable (factor) and a continuous dependent variable.
Normalization: Linearizing data can also involve normalizing it, which makes the data comparable and easier to work with across different scales. Normalization can involve techniques such as scaling variables to have a mean of zero and a standard deviation of one.
Error Reduction: In some cases, linearizing data can help reduce errors or biases in the analysis. For example, when dealing with non-linear relationships, errors might be larger in certain parts of the dataset. Linearizing the data can help mitigate this issue.
Interpretability: Linear relationships are often easier to interpret than non-linear ones. By linearizing the data, we can make the relationships between variables more transparent and understandable.
Assumptions of Analysis Techniques: Certain statistical techniques, such as linear regression, assume that the relationship between variables is linear. Linearizing the data ensures that these assumptions are met, thereby improving the validity of the analysis.
An example of data linearizing in Python
To demonstrate the concept of linearizing data, we will use a common non-linear dataset that follows a power law relationship and then apply a linear transformation to linearize it. This process is often used in data analysis to apply linear regression techniques on datasets that do not initially exhibit a linear relationship.
Consider a dataset that follows the equation y = ax^b, where a and b are constants. This is a common form of a power law relationship. To linearize this data, we can apply a logarithmic transformation to both sides of the equation, resulting in a linear relationship that can be analyzed with linear regression techniques.
The transformed equation becomes log(y) = log(a) + blog(x).
Here is a step-by-step Python example:
- Generate a synthetic dataset that follows a power law relationship.
- Plot the original dataset to show its non-linear nature.
- Apply a logarithmic transformation to both
xandyto linearize the data. - Plot the transformed (linearized) dataset.
- Perform a linear regression on the transformed data as a demonstration of how linearization allows for linear modeling techniques to be applied to non-linear data.
The dataset includes random noise, simulating data variability. The plots and linear regression analysis demonstrate how the logarithmic transformation still effectively linearizes the data, allowing for linear regression to be applied. The added variability makes the data analysis scenario more representative of real-world data challenges.
Noise is added as a small fraction of the y_power_law value to minimize the risk of y becoming non-positive. This approach should prevent the occurrence of NaN values during the logarithmic transformation and allow the linear regression analysis to proceed without errors.
Please note that you need to have the necessary Python libraries installed in your Python environment to run this code.
Running this code will output a plot along these lines:
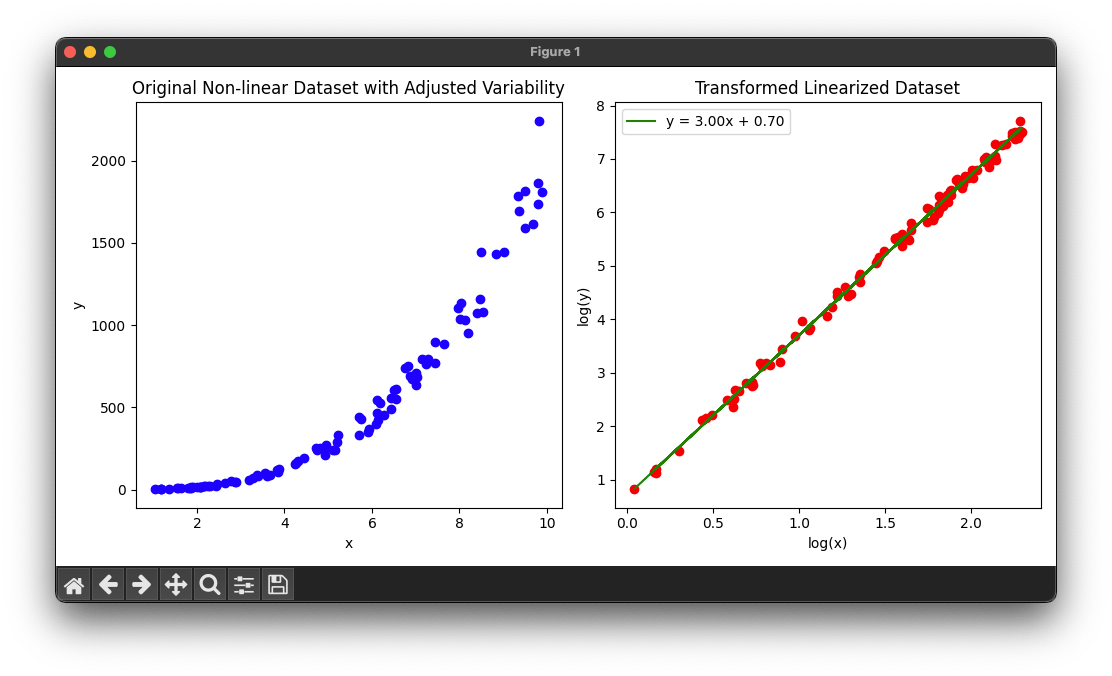
This example demonstrates how to linearize non-linear data to analyze it using linear methods. The first plot (blue) shows the original non-linear relationship, while the second plot (red) shows the data after applying a logarithmic transformation, making it linear. The linear regression model is then fitted to the transformed data, demonstrating the effectiveness of linearization in analyzing non-linear relationships.
