


Definition of Software-defined Asset:
A software-defined asset (SDA) is a declarative design pattern that represents a data asset through code. An asset is an object in persistent storage that captures some understanding of the world, and it can be any type of object, such as a database table or view, a file in local storage or cloud storage like Amazon S3, or a machine learning model.
Software-defined assets are defined by writing code that describes the asset you want to exist, its upstream dependencies, and a function that can be run to compute the contents of the asset. This approach allows you to focus on the assets themselves—the end products of your data engineering efforts—rather than the execution of tasks.
Here are some key points about Software-defined Assets:
- Declarative Nature: SDAs allow developers to declare what the end state of an asset should be, and the orchestrator takes care of the execution logic required to achieve that state. This shifts the focus from task execution to asset production.
- Observability and Scheduling: SDAs provide enhanced observability into your data assets and allow for advanced scheduling. This makes it easier to understand the state of your assets and when they should be updated.
- Environment Agnosticism: SDAs are designed to be environment-agnostic, meaning that the same asset definitions can be used across different environments, such as development and production, without changes to the asset code.
- Data Lineage: SDAs have clear data lineage, which makes it easier to understand how data flows through your system and to debug issues when they arise.
- Integration with External Tools: SDAs can be integrated with external tools like dbt, allowing the orchestrator to track the lineage of every individual table created by these tools.
- Rich Metadata and Grouping: SDAs support rich metadata and grouping tools, which are useful for organizing and searching assets within large and complex organizations.
- Partitioning and Backfills: SDAs support time partitioning and backfills out of the box, which is useful for managing historical data and ensuring data consistency.
In summary, Software-defined Assets represent a novel declarative, code-based approach to defining and managing data assets, providing clear lineage, observability, and the ability to work seamlessly across different environments.
Learn more about Software-defined Assets in the Dagster Documentation.
An example of a Software-defined Asset in Python
Using the Dagster framework for data orchestration, here is an example of defining an asset in code:
This asset is generated by reading data from a CSV file, processing it, and then writing the processed data to a new CSV file (the Asset).
In this example, we will create a simple pipeline with three assets:
raw_data: Reads data from an input CSV file namedinput_data.csvinto a Pandas DataFrame.processed_data: Takes the raw data DataFrame as input, performs some processing (in this case, doubling the values of an existing column), and returns the processed DataFrame.write_processed_data: Takes the processed DataFrame and writes it to a new CSV file namedprocessed_data.csv.
Each asset is defined with the @asset decorator, and the dependencies between assets are implicitly defined by the function arguments. For example, processed_data depends on raw_data because it takes raw_data as an argument.
The assets are rendered automatically in the Dagster UI along with upstream and downstream dependencies.
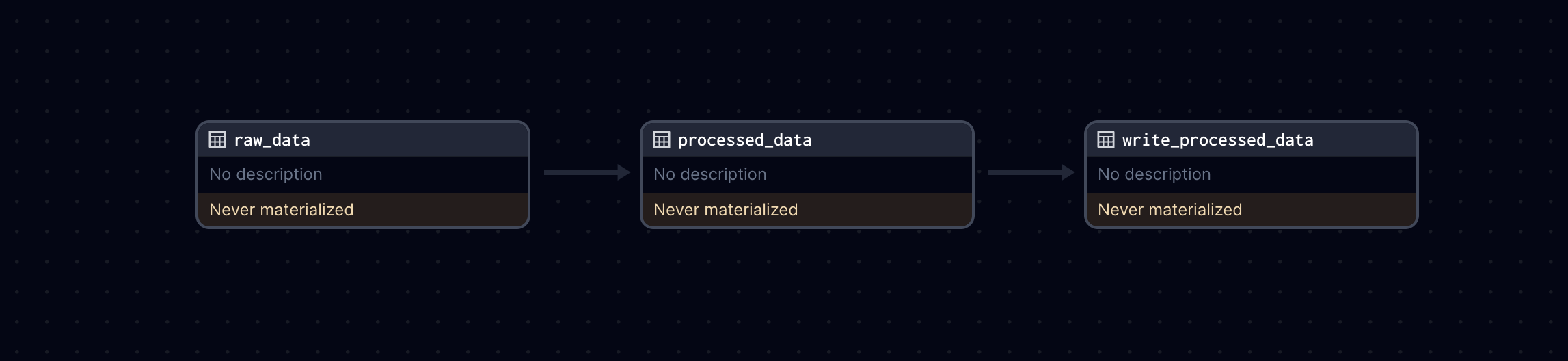
Note that all three assets will be persisted in memory, and will be observable, meaning we will capture metadata on each materialization of the asset.
import pandas as pd
from dagster import asset
# Asset to read data from a CSV file
@asset
def raw_data():
df = pd.read_csv('input_data.csv')
return df
# Asset to process the raw data
@asset
def processed_data(raw_data):
# Imagine some processing logic here, for example:
# - Cleaning the data
# - Filtering rows
# - Transforming columns
# For simplicity, we'll just add a new column with transformed data
processed_df = raw_data.copy()
processed_df['new_column'] = raw_data['existing_column'] * 2
return processed_df
# Asset to write the processed data to a new CSV file
@asset
def write_processed_data(processed_data):
processed_data.to_csv('processed_data.csv', index=False)To make these assets discoverable by Dagster, you would make sure they are imported in your repository defs:
# __init__.py
from dagster import Definitions, load_assets_from_modules
from . import assets
all_assets = load_assets_from_modules([assets])
defs = Definitions(
assets=all_assets,
)This repository now contains a sequence of Software-defined Assets that can be materialized to perform a data processing workflow. When you run this in Dagster, the system will automatically resolve the dependencies and execute the assets in the correct order, in an optimized fashion.
